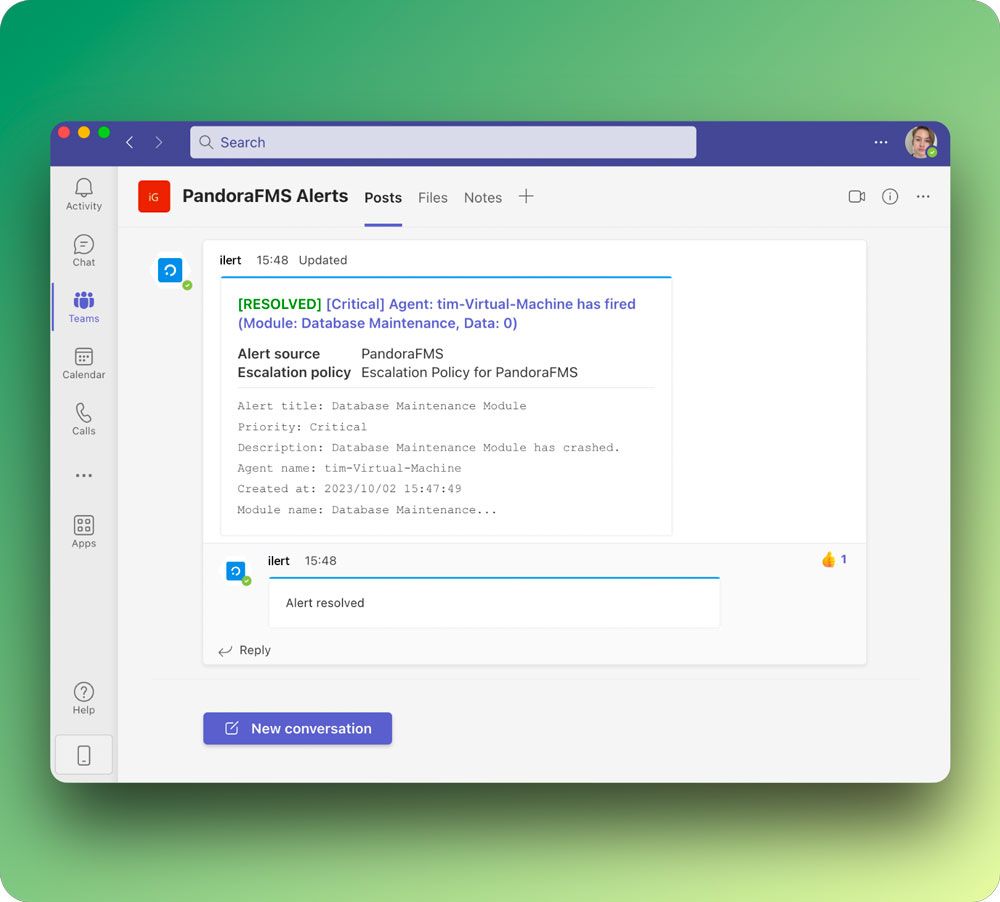
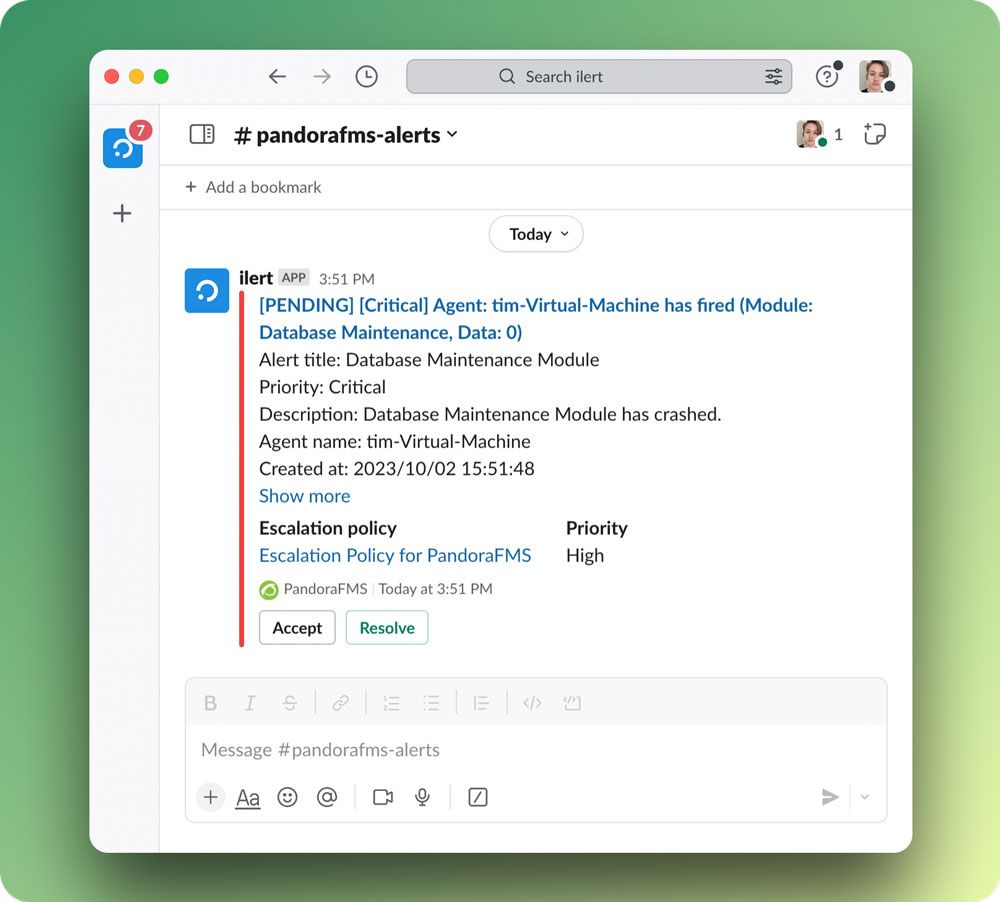
Решение для удаленного мониторинга и управления для проактивного контроля устройств, сетей и приложений. Идеально подходит для поставщиков управляемых услуг (MSP) и ИТ-команд, стремящихся к автоматизации, масштабируемости и контролю в режиме реального времени.
Мощная и гибкая служба поддержки для команд поддержки и обслуживания клиентов, согласованная с процессами библиотеки инфраструктуры информационных технологий (ITIL).
Программное обеспечение для удаленного управления серверами и ОС Windows, Linux и Mac, ориентированное на системных техников и компании, предоставляющие управляемые услуги (MSP).
Augmentez la puissance de votre surveillance. Pandora FMS s’intègre aux principales plateformes et solutions cloud.
Collectez, centralisez et consolidez les données de journaux et d’événements provenant de différents systèmes, applications et appareils dans la plateforme unique qu’est Pandora FMS.
Solution de surveillance et de gestion à distance pour un contrôle proactif des appareils, des réseaux et des applications. Idéale pour les fournisseurs de services gérés (MSP) et les équipes informatiques à la recherche d’automatisation, d’évolutivité et de contrôle en temps réel.
Helpdesk puissant et flexible pour les équipes d’assistance et de service à la clientèle, aligné sur les processus de la bibliothèque d’infrastructure des technologies de l’information (ITIL).
An extensive collection from detailed guides that break down complex topics to insightful whitepapers that offer a deep dive into the technology behind our software.
Expande el poder de tu monitorización. Pandora FMS es flexible y se integra con las principales plataformas y soluciones en la nube.
Recopila, centraliza y consolida los datos de logs y eventos de diferentes sistemas, aplicaciones y dispositivos en una única plataforma. Los datos se integran de forma nativa con Pandora FMS, sin necesidad de herramientas adicionales.
Solución de supervisión y gestión remota para la supervisión proactiva de dispositivos, redes y aplicaciones. Ideal para proveedores de servicios gestionados (MSP) y equipos de TI que buscan automatización, escalabilidad y control en tiempo real.
Potente y Flexible Helpdesk para equipos de soporte y atención al cliente, alineado con los procesos de Biblioteca de Infraestructura de Tecnologías de Información (ITIL).
Expand the power of your monitoring. Pandora FMS is flexible and integrates with the main platforms and cloud solutions.
Collect, centralize, and consolidate log and event data from different systems, applications, and devices into a single platform. Data integrates natively with Pandora FMS agents, with no need for additional tools to capture key information.
Remote monitoring and management solution for proactive oversight of devices, networks, and applications. Ideal for managed service providers (MSP) and IT teams seeking automation, scalability, and real-time control.
In this article, we will thoroughly address RMM Software (Remote Monitoring and Management Software) and its essential role for Managed Service Providers (MSPs). We will explain the core functions of RMM, from remote monitoring to efficient management of client devices, highlighting its key advantages such as reducing labor costs and improving productivity. We will analyze the strategic integration of RMM and PSA (Professional Services Automation) to empower MSP workflows and offer a vision of the future, supported by promising statistics. We conclude by highlighting the continued importance of RMM in the technology landscape and encouraging MSPs to consider its implementation to optimize efficiency and success in the delivery of managed services.
In the past, all businesses, regardless of size, used on-premise IT infrastructures. When a problem arose, they contacted their service provider and a technical team went to the offices to solve it. However, the landscape changed completely with the development of Cloud technology. The possibility of accessing data and computing resources from anywhere was gradually reducing the dependence on centralized IT infrastructures. The definitive leap occurred with the arrival of remote work and hybrid work. Organizations that go for a flexible working framework have their systems distributed in widely diverse locations, often outside the traditional corporate network.
On the other hand, each department within the company has specific technological needs that are quickly adapting to market changes. Managing all these applications manually would be very complex, expensive and could lead to human errors that put security at risk.
It is clear that to address these challenges new tools had to emerge such as the RMM (Remote Monitoring and Management) software that allows companies to maintain effective control of all their IT assets, even in distributed environments.
How does RMM software contribute to the digital transformation of companies?
As we just mentioned, RMM software has become a key piece to ensure the transition to decentralized and dynamic infrastructure environments, without neglecting the essential aspects.
Thanks to this technology, IT professionals can remotely monitor and manage a company’s entire infrastructure monitor the performance of IoT devices connected to the network in real time, identify possible threats or anomalous activities and apply corrective measures.
Although remote management tools emerged in the 1990s, they initially had limited features and were difficult to implement.
The first RMMs offered basic supervision and were installed on each computer individually. The central system then analyzed the data and created reports or alerts on critical events.
Instead, today’s RMM software takes a more holistic approach and enables unified and comprehensive management of the company’s technology infrastructure by retrieving information from the whole IT environment rather than from each device in isolation. In addition, it supports on-premise and cloud installations.
Finally, another key contribution of RMM tools for digitization is to switch from a reactive maintenance model to a preventive maintenance model. Remote access solutions allow technical teams to proactively monitor software processes, operating systems, and network threads, and address potential issues before they become critical situations.
As organizations grow, they store more data, and cyber threats are also on the rise. Many SMEs decide to hire the services of an MSP provider to take charge of their infrastructures, especially if they do not have an internal IT department that optimizes the security and performance of their systems.
MSPs use different technologies to distribute their services and one of the most important is RMM software, which allows them to proactively monitor their customers’ networks and equipment and solve any issues remotely without having to go to the offices in person.
According to data from the Transparency Market Research portal, the market for this type of software has not stopped growing in recent years and this growth is expected to remain constant at least until 2030, driven by the demand for MSPs.
How do RMM tools for remote monitoring work?
RMM tools work thanks to an agent that is installed on the company’s workstations, servers and devices. Once installed, it runs in the background and gathers information about the performance and security of systems.
The RMM agent continuously monitors network activity (CPU usage, memory, disk space, etc.) and if it detects any anomalies, it automatically generates a ticket with detailed information about the problem and sends it to the MSP provider. Tickets are organized in a panel according to their priority and their status can be changed once they have been solved or escalated to a higher level in the most complex cases.
In addition, RMM tools create periodic reports on the overall health of systems. These reports can be analyzed by technical teams to reinforce network stability.
How does RMM software help improve the operational efficiency of MSPs?
RMM software has a number of practical utilities that MSPs can leverage to raise the quality of their services:
Remote monitoring and management
It monitors equipment performance in real time and allows to solve problems remotely without having to go physically to the place where the incident took place. This saves time and costs associated with transportation.
Another advantage of implementing RMM tools is the possibility of hiring the best professionals regardless of their location and covering different time zones offering 24/7 support.
Full visibility of IT infrastructure
Thanks to RMM software, technical teams can keep track of all their customers’ IT assets from a single dashboard. For example, they can make an inventory of all devices and cloud services that are active, or check in a single dashboard view the tickets that are open and those that are pending resolution.
Automating repetitive tasks
RMM tools create automated workflows for routine tasks such as: installing/ uninstalling software, transferring files, running scripts, managing patches and updates, or backing up. This reduces the workload of IT teams and minimizes the risk of human error.
Increased security
RMM agents send alerts in real time if a critical event takes place. That way, network administrators can very quickly identify security threats or problems that affect computer performance.
Proactive monitoring is critical for MSP providers to ensure a stable and secure IT environment for their customers. In addition, it reduces the costs associated with equipment repair and data recovery.
Reduce downtime
The installation of new programs, updates and corrective measures runs in the background without interfering with user activity. This makes compliance with Service Level Agreements (SLAs) easier by solving problems as soon as possible without any prolonged service interruptions.
What aspects should MSPs consider when choosing RMM software?
It is important to choose a stable, safe and easily scalable solution that meets customer needs. In addition, the chosen RMM software is ideally integrated easily with other tools for more efficient and complete management.
Let’s look at some basic requirements!
Easy implementation
RMM tools should be intuitive to reduce commissioning time and costs.
Flexibility
As companies grow, so does their IT infrastructure. For MSPs, a higher volume of customers means increased monitoring capacity. That’s why it’s important to choose a tool that’s flexible and scalable. That way, it will be possible to add new devices and users without technical limitations.
Stability
It verifies that RMM software is stable. Some solutions provide remote access through third-party software and this can affect connection performance as each tool has its own features and data transfer speed. Therefore, it is best to select a platform that offers integrated remote access to optimize responsiveness and avoid interruptions.
Device compatibility
The tool should be prepared to monitor the activity of a wide variety of devices and computer systems that support SNMP protocols. This includes, but is not limited to, servers, routers, switches, printers, IP cameras, etc.
Seamless integration with PSA tools
The integration of RMM and PSA improves the workflow of MSPs.
PSA tools automate and manage tasks related to the provision of professional services such as invoicing, ticket management, time registration, etc.
For example, issues detected during remote monitoring can automatically generate tickets in the PSA system for technicians to review the device’s incident history and keep track.
Time spent applying corrective action can also be automatically recorded by PSAs, allowing for more accurate billing.
Security
Make sure that the RMM software you plan to purchase is properly licensed and meets security standards. It should provide features such as data encryption, multi-factor authentication, system access via VPN, or blocking inactive accounts.
Support
Finally, before deciding on an RMM solution, check that the vendor offers good post-implementation support. Check the references and opinions of other customers to know the quality of the service and make sure that you are making a good investment.
Conclusion
SMBs are increasingly digitized and rely on a wide variety of software to run their day-to-day operations. As enterprises migrate their infrastructures to the cloud, MSP providers need remote access solutions to end-to-end management of their customers’ assets.
There are different RMM tools that allow you to monitor the performance of your systems in real time and perform support and maintenance actions. One of the most complete ones is Pandora FMS Command Center, a specific version of the Pandora FMS platform for monitoring MSP and which has been designed to work in IT environments with a high volume of devices. It is a secure and scalable solution that helps managed service providers reduce workload and expand their customer base.
In addition, it has a specific training plan for IT teams to get the most out of all the advanced features of the software.
Many companies that work with Pandora FMS Command Center have already managed to reduce their operating costs between 40% and 70% thanks to task automation and reduced incidents.
It’s time to increase your business productivity and offer your customers exceptional service. Contact our sales team to request a quote or answer your questions about our tool.
On this exciting journey, we celebrate the successes of our team over the course of an incredibly productive year. From solving 2677 development tickets and 2011 support tickets to spending 5680 hours on projects and operations, each metric represents our shared dedication and success with our valued customers, which are the engine of our growth.
We reinforced our commitment to security by becoming an official CNA in collaboration with INCIBE (National Cybersecurity Institute of Spain). This prestigious achievement placed Pandora FMS, Pandora ITSM and Pandora RC as the 200th CNA worldwide and the third CNA in Spain. Our recognition as CNA (Common Vulnerabilities and Exposures Numbering Authority) means that Pandora FMS is now part of a select group of organizations that coordinate and manage the assignment of CVE (Common Vulnerabilities and Exposures), uniquely identifying security issues and collaborating on their resolution.
During this year, we experienced an exciting brand unification. What started as Artica at Pandora FMS has evolved into a single name: Pandora FMS. This transition reflects our consolidation as a single entity, reinforcing our commitment to excellence and simplifying our identity.
Globally, we excelled at key events, from Riyadh’s Blackhat to Madrid Tech Show. In addition, we expanded into new markets, conquering China, Cameroon, Ivory Coast, Nicaragua and Saudi Arabia.
We proudly highlighted the technological milestone of the year: the creation of the MADE system (Monitoring Anomaly Detection Engine), the result of our collaboration with the Carlos III University of Madrid. Presented at the ASLAN 2023 Congress & Expo in Madrid, MADE uses Artificial Intelligence to monitor extensive amounts of data, automatically adapting to each management environment. This innovation sets a radical change in monitoring by getting rid of the need for manual rule configuration, allowing the adaptation to data dynamics to be fully autonomous.
This year was not only technical, but also personal. From the fewest face-to-face office hours in 17 years to small personal anecdotes, every detail counts.
Let’s celebrate together the extraordinary effort and dedication of the whole team in this new stage as Pandora FMS! Congratulations on an exceptional year, full of success in every step we took!
SSH stands for “Secure Shell.” It’s a network protocol used to securely access and manage devices and servers over an unsecured network. It provides an accurate form of authentication as well as encrypted communication between two systems, making it especially useful in environments where security is a concern.
SSH is commonly used to access remote servers through a command line interface, but can also be used to securely transfer files (through SFTP or SCP). It uses encryption techniques to protect transmitted information, making it difficult for third parties to intercept or manipulate data during transmission.
One of the main advantages of SSH is its ability to authenticate both the client and the server, which helps prevent man-in-the-middle attacks and other security threats. SSH replaces older, less secure methods of remote access, such as Telnet, which transmits information in an unencrypted manner, making it susceptible to interception and data theft.
SSH is an operating system independent protocol. Although it was conceived for UNIX environments, it is present in operating systems such as OSX (Mac) and in the latest versions of Microsoft Windows servers. SSH is, de facto, the standard for connecting to servers by command line.
It uses port 22/TCP, but can be configured to listen and connect over different ports. In fact, it is considered a good security practice to change the default listening port to avoid being identified by remote scanning tools.
The trajectory of OpenSSH dates back to 1999 and is closely linked to the original software called “SSH” (Secure Shell), created by Tatu Ylönen in 1995. SSH is a network protocol that enables secure connection and remote control of a system through a command line interface.
In its early days, SSH was proprietary software and although it was available for free for non-commercial use, it required licenses for use in commercial environments. This led to the creation of several open source SSH implementations to fill the gap in terms of accessibility and software licensing.
In this context, the OpenSSH project was initiated by Markus Friedl, Niels Provos, Theo de Raadt, and Dug Song in December 1999. The creation of OpenSSH was carried out in response to a series of events that included the release of the SSH protocol source code by Tatu Ylönen and concerns about ownership and licensing of existing proprietary software.
The initial goal of the OpenSSH project was to create a free, open-source protocol that was compatible with existing versions, especially SSH-1 and SSH-2. OpenSSH also sought to circumvent the licensing restrictions associated with proprietary SSH deployments.
As the project progressed, it became the de facto implementation of SSH on Unix- and Linux-based systems. OpenSSH’s growing popularity was due to its open source code, ability to provide safe communication, and features such as strong encryption, key-based authentication, and secure file transfer capability (SFTP).
OpenSSH also benefited from collaboration with the free and open source software community. Over the years, it has undergone continuous improvements, security updates, and functional extensions, making it an essential tool in remote system administration and network security.
In short, OpenSSH emerged as a response to the need for a free, open-source SSH implementation. Over the years, it has evolved to become the most widely used SSH implementation on UNIX and Linux systems and remains a key element in the security of communication and system administration in distributed environments.
Remote command execution with SSH
SSH not only provides a way to interactively access the shell of a remote machine, it can also be used to execute remote commands on a system, with the following syntax:
ssh user@host:/path/ofthe/command
SSH is frequently used in scripts for the automation of all types of actions and processes, for that it requires automatic authentication by means of certificates, since, by default, it will require the user to enter a password manually and interactively through the keyboard.
Security at SSH
SSH stands for Secure Shell, so security is part of SSH’s foundational design.
SSH also has the ability to create TCP tunnels that allow a host to be used to create a kind of dedicated VPN, between two IPs, that can be bidirectional. It is what is known as “TCP Tunnel” and that when misused, can be a security problem.
SSH allows automatic authentication through certificates, which allows a user to connect to a system through SSH without knowing the password. To do this, the public key of a digital certificate must be copied to the server, so that you identify that user through their certificate. This is an advanced option that allows command execution automation through SSH, but which presents inherent risks to any automation.
What are the differences between Telnet and SSH?
SSH and Telnet are two network protocols used to access remote systems, but there are significant differences in terms of security and features.
SSH is the current standard for remote access in all types of environments. Telnet, on the other hand, is older and less secure, and its use is discouraged, unless it is impossible to use SSH.
Security
SSH: It provides a safe environment for communication between two systems. All data, including usernames and passwords, are encrypted before being transmitted, making it much more difficult for an attacker to intercept and understand the transmitted information.
Telnet: It transmits data, including login credentials, in an unencrypted form. This means that if someone has access to the network between the client and the server, they can easily capture and read the information.
Encryption
SSH: It uses encryption to protect data during the transmission. Encryption algorithms in SSH can be configured to meet the latest security standards.
Telnet: It does not provide encryption, which means that all information, including passwords, are transmitted insecurely.
Authentication
SSH: It supports several authentication methods, including the use of passwords, public key, and token-based authentication.
Telnet: Depending on your settings, it generally uses only usernames and passwords for authentication.
Ports
SSH by default. SSH uses port 22, unlike Telnet, which uses port 23. However, these ports can be changed at any time.
Top SSH customers
Listed below are some of the best-known SSH customers on the market.
OpenSSH
OpenSSH (Linux, macOS, Windows with WSL) and other operating systems such as BSD or communications devices that support a version of OpenSSH.
OpenSSH is a free and open source implementation of the SSH protocol. It comes pre-installed on most Linux distributions and is widely used in Unix environments.
It is highly reliable, secure, and the default choice on many Unix-based operating systems, as well as being 100% free.
Putty
PuTTY is a free and open source SSH client for Windows and is therefore very popular. Although it was initially designed for Windows, there is also an unofficial version called “PuTTY for Mac” that works on macOS, there are also alternative versions for Linux.
It’s lightweight, easy to use, and can be run as a portable app with no installation required. However, it lacks a powerful interface, does not allow sequence recording, and in general, lacks more advanced features that you may find in other “visual” SSH clients. It also doesn’t have a specific interface for file transfer.
Of all the options, PuTTY is the most basic one, but at least it’s a visual interface, unlike the standard operating system’s SSH client that’s free, but where all the “features” are command-line-based.
Downloads and Updates
It can be downloaded from its own web, although there are several sites in parallel that offer alternative versions for Mac and even Linux.
Price & Licenses
It’s free and under an OpenSource license, so you may modify its code and compile it on your own.
BitVise
Bitvise SSH Client is a solid choice for Windows users looking for an easy-to-use and secure SSH client. Its combination of an intuitive interface, advanced file transfer features, and robust security makes it a well-liked tool for remote system management and safe file transfer.
SSH Server
BitVise offers both an SSH client and an SSH server. Generally, Windows systems do not use SSH so it can be a very good option to implement it, despite the fact that the latest versions of Microsoft Windows Server already implement it. It is an excellent option for implementing SSH in older Windows versions, as it supports a wide selection of versions, almost since Windows XP:
Windows Server 2022
Windows 11
Windows Server 2019
Windows Server 2016
Windows 10
Windows Server 2012 R2
Windows Server 2012
Windows 8.1
Windows Server 2008 R2
Windows Server 2008
Windows Vista SP1 or SP2
Windows Server 2003 R2
Windows Server 2003
Windows XP SP3
SSH Tunneling and Port Forwarding
It allows SSH tunnel configuration and port forwarding, which is useful for securely redirecting network traffic over SSH connections.
Advanced Session Management
Bitvise SSH Client offers advanced options for session management, including the ability to save session configurations for quick and easy access to frequently used servers.
Session Log and Audit
It provides a detailed session log, which can be useful for auditing and activity tracking purposes.
Proxy Support:
Bitvise SSH Client supports several proxy types, allowing users to bypass network restrictions and connect through proxy servers.
Only for Windows, it is priced at around 120 USD per year.
SecureCRT
It is available for all platforms: Windows, macOS, and Linux. A functional demo can be downloaded from their website at https://www.vandyke.com.
SecureCRT is a commercial client that offers support for multiple protocols, including SSH. It provides an advanced graphical interface, scripting and automation functions, and is widely used in enterprise environments.
Terminal Emulation
It offers terminal emulation for a wide variety of types, including VT100, VT102, VT220, ANSI, among others. This ensures effective compatibility with different remote systems and devices.
Secure File Transfer
SecureCRT includes support for secure file transfer protocols, such as SCP (Secure Copy Protocol) and SFTP (Secure File Transfer Protocol). This allows users to securely transfer files between local and remote systems. To manage file transfers, use an additional product called SecureFX (with an additional license fee).
Automation and Scripting
It makes it easy to automate tasks by running scripts. It supports different scripting languages, such as VBScript, JScript, and Python, providing flexibility in process automation.
Efficient Session Management
SecureCRT offers an efficient session management interface that allows users to easily organize and access previous connections. It also makes it possible to import and export sessions for easy configuration transfer between systems. It allows advanced session configuration, including authentication options, function key configuration, port forwarding, among others. This gives users precise control over their remote sessions.
SSH Key Integration
SecureCRT supports key-based authentication, which means users can manage and use SSH keys for safe authentication without relying on passwords.
Additional Protocol Support
In addition to SSH, SecureCRT also supports other protocols such as Telnet, rlogin, and Serial. This makes it a versatile tool for different network environments.
Price & Licenses
A full version for one user, including safe transfer features (SecureFX) is about $120 per year.
ZOC
ZOC Terminal is an SSH client and terminal emulator that offers advanced features for users who need a powerful and versatile tool to work with SSH remote connections. It is also compatible with other protocols such as Telnet and Rlogin, which extends its usefulness in different environments not only as an SSH client but also as a Telnet client.
ZOC is compatible with Windows and macOS and publishes regularly updated versions. A demo version can be downloaded from their website at https://www.emtec.com.
Terminal Emulation Functions
ZOC supports multiple terminal emulations, such as xterm, VT220, TN3270, and more. This allows users to connect to a variety of remote systems and mainframes.
File Transfer
It includes secure (and insecure) file transfer features, such as FTP, SFTP (SSH File Transfer Protocol) and SCP (Secure Copy Protocol), allowing users to securely transfer files between the local and remote system. The feature is included in the product itself.
Automation and Scripting
ZOC makes it easy to automate tasks by running scripts. It supports different scripting languages, such as VBScript, JScript, and Python, providing flexibility in process automation. It also allows you to record a key combination and play it back to, for example, automate login sessions that require the use of sudo or su.
Session Management
The ability to manage and organize sessions is crucial for those who work with multiple connections. ZOC offers an efficient session management interface that allows users to easily organize and access previous connections. You can have a catalog of systems where you can easily connect.
Price & Licenses
The basic license is around 80 USD, but its free version allows you to work easily, except for the somewhat annoying popup at the beginning.
Pandora RC: Alternative to using SSH
Pandora RC (formerly called eHorus) is a computer management system for MS Windows®, GNU/Linux® and Mac OS® that allows you to access registered computers wherever they may be, from a browser, without having direct connectivity to your devices from the outside.
Security
For greater security, each agent, when configured, may have an individual password that is not stored on the central servers of Pandora RC, but each time the user wishes to access said machine, they will have to enter it interactively.
Remote access without direct connection
One of the most common SSH issues is that you need to be able to access the server IP. With Pandora RC, it’s the server that connects to a cloud service and so it’s available from anywhere, without the need for a VPN or complex firewall rules.
Integrated with Pandora FMS
It integrates natively with Pandora FMS monitoring software, so that it is possible not only to monitor the servers, but to access them directly from the same interface, without the need to install SSH clients, remember passwords or generate duplications.
Pandora RC has a remote control system through access to the Desktop in a visual way. In both cases, a web interface is used to operate with the remote server, whether it is Windows, MacOS or Linux. It also provides a file transfer mechanism and process/service management. All integrated into one WEB application:
The Principle of Least Privilege, also known as PoLP, is a computer security rule that states that each user or group of users must have only the necessary permissions to perform their corresponding tasks.
In other words, the less power a user has, the lower the chances of them having a harmful impact on the business.
When a user has too many permissions, they are more likely to make mistakes or fall victim to an attack. For instance, users with access to servers could install malware or steal sensitive information.
How is it applied?
PoLP can be applied to any computer system, either on-premise or in the cloud.
What if a user needs to do something they can’t normally do?
The Principle of Least Privilege states that each user should have only the necessary permissions to perform their tasks. This practice helps protect company systems and data from cyberattacks.
However, there are circumstances where a user may need to circumvent security restrictions to perform some unplanned activity. For example, a certain user may need to create records for a new customer.
In these cases, the system administrator may grant the user temporary access to a role with greater privileges.
How is this done safely?
Ideally, the system administrator should create a job that automatically adds the user to the role and, after a defined time, removes them from the role.
For example, the administrator could grant user privileges for two hours and then automatically remove the privileges after that time.
This helps ensure that the user only has access to the necessary permissions for as long as they need them.
What about user groups?
Overall, it is safer to grant permissions to groups of users than to individual users.
This is because it is more difficult for an attacker to compromise an entire group of users than a single user.
For example, if John is an accountant, instead of granting John template creation privileges, the administrator could grant those privileges to the group of accountants.
What about processes or services?
The Principle of Least Privilege also applies to processes and services.
If a process or service works with an account, that account should have as few privileges as possible.
This helps reduce the damage an attacker could cause if they compromised the account.
Continued Importance in a Changing World
A large number of companies, following the COVID pandemic, significantly increased the number of employees working from home. Before, we only had to worry about computers within the company. Now, the security of every laptop or mobile phone accessing your network can be a security breach.
To prevent disasters, we must create security standards and train staff to prevent them from entering prohibited sites with company computers or computers that access our company. That’s why you should avoid giving administrator privileges and applying PoLP on users as much as possible. That is why a trust 0 policy is applied, giving the least amount of privileges as possible. If the user is not authenticated, they are not given privileges.
IT staff should check the security of laptops carried by the user and see how to prevent attacks from reaching enterprise or cloud servers coming from our staff working remotely.
Implementation Difficulties
However, applying the minimum security privilege is nowadays quite complex. Users with an account access countless different apps.
They may also have to access web applications that rely on Linux servers, so roles and privileges must be created in different applications. It is very common for several basic features not to work with the minimum cybersecurity privileges, so there is the temptation to grant extra privileges.
Giving minimum privileges to a single application is already something complicated. Granting PoLP to several systems that interact with each other becomes much more complex. It is necessary to carry out safety quality controls. IT engineers should do security testing and patch security holes.
Privileged accounts: Definition and Types
Privileged accounts or super accounts are those accounts that have access to everything.
These accounts have administrator privileges. Accounts are usually used by managers or the most senior people in the IT team.
Extreme care must be taken with such accounts. If a hacker or a Malware manages to access these passwords, it is possible to destroy the entire operating system or the entire database.
The number of users with access to these accounts must be minimal. Normally only the IT manager will have super user accounts with all privileges and senior management will have broad privileges, but in no case full privileges.
In Linux and Mac operating systems, for example, the superuser is called root. In the Windows system it is called Administrator.
For example, our default Windows account does not run with all privileges. If you want to run a file with administrator accounts, right-click on the executable file and select the option Run as Administrator.
This privilege to run as an administrator is only used in special installation cases and should not be used at all times.
To prevent a hacker or a malicious person from accessing these users, it is recommended to comply with these security measures:
Use a long, complex password that mixes uppercase, lowercase, numbers, and special characters.
It also tries to change the password of these users regularly. For example, changing the password every month or every two months.
It does not hurt to use a good anti-virus to detect and prevent an attack and also to set a firewall to prevent attacks by strangers.
Always avoid opening emails and attachments from strangers or entering suspicious websites. These attacks can breach accounts. Where possible, never browse with super user accounts or use these accounts unless necessary.
Privileged Cloud Accounts
Today, a lot of information is handled in the cloud. We will cover account management on major platforms such as AWS, Microsoft Azure, and Google Cloud.
AWS uses authentication type Identity and Access Management (IAM) to create and manage users. It also supports multi-factor authentication (MFA) which requires 2 ways to validate the user and thus enter, thus increasing security.
On AWS there is a root user who is a super user with all privileges. With this user create other users and protect it using it as little as possible.
Google Cloud also provides an IAM and also the KMS (Key Management Service) that allows you to manage keys.
Depending on the cloud application, there are super users who manage databases, analytics systems, websites, AI and other resources.
If, for example, I am a user who only needs to see table reports from a database, I do not need access to update or insert new data. All these privileges must be carefully planned by the IT security department.
Common Privileged Threat Vectors
If the PoLP is not applied, if a hacker enters the system, they could access very sensitive information to the company by being able to obtain a user’s password. In many cases these hackers steal the information and ask for ransom money.
In other situations, malicious users within the company could sell valuable company information. If we apply the PoLP, these risks can be considerably reduced.
Challenges to Applying Least Privilege
It is not easy to apply the PoLP in companies. Particularly if you have given them administrator privileges initially and now that you learned the risks you want to take the privileges away from them. You must make users understand that it is for the good of the company, to protect its information and that great power comes with great responsibility. That if an attack happens to the company, the reputation of the employees themselves is at stake as well as that of the company. Explain that safety is up to everyone.
Many times we give excessive privileges due to the laziness of giving only the minimum cybersecurity privilege. But it is urgent to investigate, optimize and reduce privileges to increase security.
Another common problem is that having restricted privileges reduces the productivity of the user who ends up being dependent on their superior for lack of privileges. This can cause frustration in users and inefficiency in the company as a whole. You must seek to achieve balance in terms of efficiency without affecting safety.
Benefits for Safety and Productivity
By applying the principle of granting restricted access, we reduce the attack surface. The chances of receiving a malware attack are also reduced and less time is wasted trying to recover data after an attack.
For example, Equifax, a credit company, fell victim to Ransomware in 2017. This attack affected 143 million customers. Equifax had to pay $700 million in fines and reparations. It also had to pay compensation to users.
It reduces the risk of cyberattacks.
It protects sensitive data.
It reduces the impact of attacks.
Principle of Least Privilege and Best Practices
In order to comply with the standards, it is advisable to carry out an audit and verify the privileges of users and security in general. An internal verification or an external audit can be done.
You may carry out security tests to see if your company meets those standards. Below are some of the best-known standards:
CIS is a Center for Information Security. It contains recommendations and best practices for securing systems and data globally.
NIST Cybersecurity Framework provides a National Institute of Standards and Technology security framework.
SOC 2 provides an assessment report of a company’s or organization’s security controls.
Least Privilege and Zero Trust
Separating privileges is giving users or accounts only the privileges they need to reduce risk. Just-In-Time (JIT) security policies reduce risks by removing excessive privileges, automating security processes, and managing privileged users.
JIT means giving privileges only when you need them. That is, they should be temporary. For example, if a user needs to access a database only for 2 hours, you may create a script that assigns privileges during this time and then remove those privileges.
To implement the JIT:
Create a plan with security policies.
Implement the plan by applying the PoLP and JIT with controls that may include multi-factor access and role access control.
It is important to train employees on safety and explain these concepts so that they understand not only how to apply them but why to apply them.
And finally, it is important to apply audits. This topic was already discussed in point 10.
It is also convenient to monitor permissions to see who has more privileges and also see what resources are accessed, to see if adjustments need to be made to them.
Solutions for the Implementation of Least Privilege
As mentioned above, to increase security, segment the network to reduce damage if your security is breached. Segmenting the network is dividing the network into small subnets.
The privileges granted to users should also be monitored.
Finally, security policies must be integrated with technologies to create an administrative plan according to the software you have.
How to Implement Least Privilege Effectively
To implement the principle of granting access, the proposed system must be implemented on test servers. Personnel should be asked to test actual jobs in the system for a while.
Once the errors are corrected or user complaints are resolved, it is up to you to take the system into production with minimal privileges. A trial period of at least one month is recommended where users test the system and have the old system at hand.
In most cases, the old and new systems coexist for months until the new system is approved with the least privileged security implemented.
Conclusion
The Principle of Least Privilege: A Simple but Effective Measure for Computer Security.
In an increasingly digital world, IT security is critical for businesses of all sizes. Cyberattacks are becoming more frequent and sophisticated, and can cause significant damage to businesses.
One of the most important steps businesses can take to protect their systems and data from cyberattacks is to apply the Principle of Least Privilege. The Principle of Least Privilege states that each user should have only the necessary permissions to perform their tasks.
Applying the Principle of Least Privilege is a simple but effective measure. By giving users only the necessary permissions, companies reduce the risk of an attacker compromising sensitive systems and data.
Tips for applying the principle of least privilege:
Identify the permissions needed for each task.
Grant permissions to groups of users instead of individual users.
Information Technology (IT) support, also known as technical support, is essential for the successful and efficient operation of organizations in the digital age. It helps ensure the stability, productivity and security of your systems and those of the people who depend on them.
Its importance lies in several key aspects such as maintenance of the technological infrastructure (this includes servers, networks, operating systems, software, hardware and other essential components); and ensure business continuity, implement and maintain security measures (such as firewalls, antivirus and intrusion detection systems); periodic updating and maintenance of the software, implementation and management of data storage systems, backup and recovery of data in case of failures; resource optimization (such as server capacity management), keep up to date with the latest technological trends and evaluate how these can benefit the organization and provide data and analysis that help to decision-making.
The 5 levels of IT support: description, functions and skills
IT Support Level 0: Self-service
IT support level 0, often called “self-service,” is the initial level of technical support offered to users so they can solve technical problems on their own without needing to interact with a support technician. This tier support focuses on providing users with the tools, resources, and documentation needed to address common technical issues on your own. Some key aspects of IT Support Tier 0 include:
Self-service portal.
Knowledge base.
Guided self-service.
Online community.
Diagnostic tools.
Training.
Automation.
IT Support Level 1: First person-to-person contact (basic support)
Level 1 IT support, also known as “first person-to-person contact” or “basic support”, focuses on solving the simplest and most common technical problems that do not require advanced technical knowledge. Common features and responsibilities of tier 1 support are described below:
Helpdesk.
Incident logging and tracking.
Troubleshooting common problems.
Documentation and updating of the knowledge base.
Coordination with other teams.
IT Support Level 2: Technical support
IT Support Tier 2, also known as “technical support” or “advanced support”, handles more complex and technical issues that go beyond the capabilities of Tier 1. Some of the main features and responsibilities of tier support 2 are:
Root cause analysis.
Development and maintenance of technical documentation.
Interaction with suppliers and manufacturers.
Training and mentoring of level 1 staff.
Proactive monitoring and maintenance.
Participation in IT projects.
IT Support Level 3: Expert support
IT Support Level 3, also known as “expert support” or “high level support,” is responsible for addressing the most complex and challenging issues that require deep technical knowledge and expertise. The most outstanding features and responsibilities of tier support 3 are:
Research and development.
Design and implementation of advanced solutions.
Participation in strategic projects.
The development of policies and procedures.
Crisis management.
IT Support Level 4: Third Party Support
Level 4 IT support, also known as “third-party support” or “external support,” is reserved for extremely complex issues or situations where specialized expertise is required, which goes beyond what an organization can offer internally. Common features and responsibilities of tier support 4 are described below:
Technology vendor support.
Development of customized solutions.
Technology integration.
Participation in security audits and reviews.
Service contracts coordination and management.
Supplier relationship management.
Trend analysis and strategic recommendations.
Establishing a tiered help structure
Implementing a tiered support structure involves careful planning and execution to ensure efficient technical assistance. Among the main steps to establish a tiered help structure is the choice of the appropriate IT Service Management (ITSM) platform, which is scalable and customizable.
Once the ITSM tool has been chosen, a self-service platform or a dedicated web portal must be configured there and the IT support levels of the organization must be clearly defined. In addition, the ITSM platform must include process automation, such as ticket routing, incident prioritization or reporting; providing updated documentation at each support level; tools to measure the performance of the IT structure and demand management to plan workloads.
Finally, to create an effective structure it is essential to establish effective communication channels and perform periodic evaluations to adjust the structure and processes to the changing needs of the organization.
Conclusion
Implementing a tiered help structure in an IT environment brings multiple benefits to the organization.
Benefits of Implementing IT support levels
Support levels enable efficient distribution of support requests, ensuring that issues are addressed at the appropriate level for resolution. This operational efficiency results in an improvement of user satisfaction and in cost savings by ensuring that technical resources are used more competently.
On the other hand, quick management of critical incidents provided by the help structure by levels, escalating the problems according to their nature to the different levels of support, allows to guarantee the continuity of the business. Finally, sharing documentation and knowledge allows capacity building among company personnel.
Adapting the structure to the needs of the organization
It is important to note that there is no single and universally applicable IT levels support structure. Each organization has specific needs and requirements, so it is essential to adapt the structure to its particular circumstances taking into account the size and complexity of the organization, the nature of the operations, that it carries out according to the industry to which it belongs, the needs of the users, both internal and external, of the company; the economic and human resources that the organization has and the technological changes that take place and that require a flexible infrastructure capable of adapting to technological and business evolutions.
Frequently Asked Questions
Summary of frequent questions about IT support and careers in this field
What is IT support for?
IT support is a very useful tool, both for companies and individuals, to receive assistance in any of the tasks to be carried out in their corresponding IT environments. It guarantees that they will be able to meet their goals or continue to offer services to their customers even if they suffer hardware, software or network failures.
What are the IT support levels?
Level 0: Self-Service
Level 1: Basic support
Level 2: Technical support
Level 3: Expert support
Level 4: Third party support
How do I start my career in IT support?
Of course, to get a job in this field requires technical knowledge of systems and processes. To begin with, you could complete related courses or get one of the necessary certifications.
What is remote IT support?
Remote IT support allows support technicians to provide their services to customers more quickly and effectively through remote control, email or chat. Even at a distance, they are able to diagnose any problem and provide the steps to follow to solve it.
What are the skills to work in IT support?
Of course, dealing with clients will always require professional and effective communication skills. Additionally, the ability to effectively troubleshoot and keep up with all IT news is critical for any professional IT.
Surely you may have at one time or another received an email warning of an outstanding invoice, a parcel shipment that you did not expect or a warning from the bank about suspicious activity in your account. These messages usually adopt an alarming tone and provide you with a link to a website that you must visit right away to verify your personal information or to complete payment information. Caution! This is a “phishing” attempt, one of the most popular scam methods on the Internet!
Phishing is a form of cyberattack that uses technology and social engineering to breach user security.
The term comes from the word “fishing”, since cybercriminals employ bait tactics waiting for users to “bite” or fall into the trap. They usually aim to get hold of financial information, payment service passwords (such as PayPal), or login credentials.
Actually, phishing is nothing new. The first cases of this type of fraud date back to the mid-1990s, when a group of fraudsters posed as employees of the AOL company to steal confidential customer data. Already in the 2000s, attacks began to specialize, focusing mainly on the banking sector.
Over the years, scams have become more sophisticated and, despite advances in cybersecurity, phenomena such as the rise of teleworking or the fraudulent use of AI have contributed to the rise of new ways of phishing.
Phishing as a source of concern
Anyone can become a victim of phishing. Even though cybersecurity systems are getting more powerful by the day, scammers have also honed their skills and organized themselves into small teams, specializing in social engineering tactics.
Companies often become the preferred target of these cybercriminals who try to steal your sensitive data or trick intermediary charges into making unauthorized transfers. A fairly common example of phishing is vendor invoice fraud, in which fraudsters impersonate trusted business partners to request payment for an outstanding invoice.
Even more disturbing are cases like the one we saw at the beginning of 2020 in the magazine Forbes in which a Japanese company was the victim of an elaborate scam in which the generative AI was used to clone the voice of a manager and authorize a transfer of 35 million dollars.
Audio cloning, audiovisual deep fakes and, in general, the use of the latest technology for criminal purposes pose a great threat and, at the same time, a challenge for cybersecurity companies.
Risks associated to phishing attacks
Financial losses have an immediate impact, but there are other long-term consequences that phishing victims can experience:
Reputational damage: Data breaches can erode customer trust, causing permanent damage to the company’s reputation.
Service outage: A cyberattack can cripple the company’s computer systems, especially if it involves ransomware. It all starts by downloading a malicious file included in the phishing messages. Once in the system, it encrypts critical files and blocks access to business-critical information.
Fines and penalties: Violation of data protection regulations (such as GDPR) may result in sanctions by authorities.
It is important to be prepared to deal with these threats using robust cybersecurity solutions and internal employee awareness programs as the main weapons to prevent phishing attacks.
Relevant statistics and data
Email fraud already accounts for 27% of economic losses for cybersecurity breaches and is responsible for 90% of data breaches, according to the report Cybersecurity Threat Trends 2021 (CISCO). This is mainly because phishing campaigns have become massive and scammers use hundreds of emails to reach more people.
Key elements in a phishing attack
Luckily, phishing messages are usually quite clumsy and recipients quickly realize that they are facing a scam, but sometimes they are so customized that they cast doubt on whether they are legitimate or not.
To gain the trust of their victims, fraudsters impersonate institutions, banks or companies that offer their services over the Internet.
Most of these fraudulent emails consist of:
An unknown sender, with generic email extensions (Gmail, Hotmail, etc.) or names that resemble those of official companies, but with strange words that we cannot identify.
A generic greeting (“Dear customer”, “Dear friend”) since cybercriminals generally do not know the identity of the recipient.
An urgent request for our personal information (ID, credit card number) under the pretext of solving an issue.
An external link that leads to a fraudulent website with the same logo, design and colors of the brand they intend to impersonate. On this landing page you will be prompted to update your details to continue. Here is where information is stolen.
There is also the possibility that the email contains an attachment infected with malicious software (malware, ransomware). If you download it, it will compromise the security of the system.
It is important to be cautious and learn to recognize these phishing signals to minimize risks.
Types of phishing
There are currently over 10,000 forms of phishing (as reported by Wikipedia). These are some of the best known embodiments.
Traditional phishing
It is the most common form of email fraud. It is based on the random issuance of emails impersonating the identity of a trusted company or institution. Messages include links to fraudulent websites or infected files.
Spear phishing
While traditional phishing is a random scam, spear phishing targets a specific person, usually an influential position within the company. To earn their trust, cybercriminals conduct extensive research on the Internet, collecting personal data from social networks such as LinkedIn, where they check information such as age, location or position within the company.
Whaling
In whaling, the target is important people within the company or executive positions (CEO, CFO, etc.). Scammers investigate their prey for weeks and send highly personalized emails, related to critical business issues.
Smishing
Fraudulent messages are sent via text messages (SMS) or WhatsApp. For example, we received a notice from our bank reporting an unauthorized purchase with our card with a link to change the PIN and login details. If YOU do, we will have fallen into the trap.
Vishing
It comes from the union of “voice” and “phishing”. In this case, the scam is done by phone call. A typical example is technical service fraud where scammers call to report a computer failure that doesn’t actually exist and convince us to install a Trojan that will steal your data.
Angler Phishing
It is a new tactic that consists of creating fake profiles on social networks with the name of prestigious institutions and companies. The goal is to steal sensitive data from other users.
How to detect Phishing attacks?
Recognizing a phishing message is not always easy, but there are some indications that may make us suspect that the request is unusual.
Alarmist tone: They often convey urgency and urge the user to act immediately. Cybercriminals use emotions such as fear or curiosity and use intimidation tactics to make us act irrationally.
Grammatical errors: Many phishing messages contain spelling and grammatical errors as they were written by non-native speakers. Anyway, nowadays many scammers use tools like Chat GPT to correct their texts, so we must be wary even of messages without spelling mistakes.
Suspicious links or unsolicited attachments: Does the sender ask you to click on a link? Does it include alleged unpaid bills or fines that you can’t identify? This is most likely a cyberattack.
How to prevent a Phishing attack?
Do not open messages from unknown senders.
Do not provide your personal information through a link in an email.
Don’t download suspicious attachments.
Hover over the link and check if the url starts with https. This indicates that the site has a safe certificate.
If despite these precautions you fell into the trap and provided your data, change the passwords of the affected accounts as soon as possible and report the scam to the local police. You may also contact the Internet User Security Office of INCIBE (National Institute of Security) to investigate the fraud.
Protecting your organization from phishing
IBM assures in its report Cost of a Data Breach Report 2021 that it can take an average of 213 days for a company to warn that it was the victim of a phishing attack. During this time, cybercriminals will access all kinds of confidential information: database passwords, trade secrets, access credentials to the corporate network… That is why it is important to be prepared and work proactively to stop the threat of phishing.
Some preventive measures:
Employee Awareness
Make cybersecurity part of your company’s organizational culture and create campaigns to warn your employees of the risks of Internet scams. A good measure is to implement a phishing simulation software to train them and teach them to differentiate an authentic email from a fraudulent one.
Implementing email security solutions
The first line of defense against a phishing attack is the anti-spam filter built into email. Make sure it’s up to date with the latest versions and security patches. You may also configure email authentication policies as Domain-based Message Authentication, Reporting, and Conformance (DMARC) to reduce the risk of phishing.
Endpoint monitoring and protection
Endpoints are the end devices (computers, tablets, smartphones) connected to the network. EDR solutions have been designed to monitor and detect the presence of malware on these endpoints.
Unlike antiviruses that work with previously identified patterns, EDR solutions are more advanced since they give automated and real-time responses to contain the attack. They use technologies such as AI and machine learning capable of detecting anomalous behaviors, such as the execution of malicious scripts.
Endpoint protection is a basic cybersecurity measure, but should be combined with other solutions such as network traffic monitoring or safe remote access solutions such as Pandora RC.
How does Pandora RC help improve remote access security?
More and more companies are adopting policies of teleworking or hybrid work. It is a reality that poses new challenges in terms of cybersecurity. Remote workers operate in less secure environments than those under the supervision of IT teams.
Tools like Pandora RC help monitor your systems by offering remote support and quick assistance if a phishing attack is suspected.
Other ways Pandora RC can help prevent cyberattacks:
It generates 100% local passwords avoiding vulnerabilities in centralized systems.
Remote connections must be pre-approved.
It uses dual authentication access policies. This reduces the risk of unauthorized access, as users have to validate their identity in two steps.
It is a flexible and scalable solution. In addition, it is available as a SaaS or On-Premise solution for companies that want to have more control over their infrastructures.
Other tips to prevent phishing attacks in the business environment
As phishing techniques become more sophisticated, the need for protection is increasing. Therefore, it is not a bad idea to keep in mind some basic tips:
Try to stay up to date on new scams, follow the news in the media, and read tech blogs like Pandora FMS blog.
Use strong passwords on your accounts that include a combination of numbers, letters, and special characters. Never choose personal data such as date of birth, cities or pet names for your passwords; phishers could guess this information by checking your social media.
Use a multi-factor authentication (MFA) system to add an extra layer of security to your connections. That way, if a hacker gets your login credentials, they would still need to know the code sent to your mobile to access your accounts.
Installing a firewall is critical to blocking unauthorized access to sensitive information. Make sure it’s properly configured and only allows safe transactions.
Keep your browser and operating system up to date as cybercriminals often take advantage of vulnerabilities in outdated systems.
Prevents access to sensitive information over public Wi-Fi networks. Many of these networks lack encryption protocols and transmitted data could be intercepted. Turn off the option to automatically connect to open Wi-Fi networks on your mobile.
Make automatic backups of company data to be able to recover information in the event of an attack. We recommend them to be immutable backups (they cannot be deleted or modified). This ensures that copies are protected and can be restored even if a ransomware attack takes place.
Conclusion
As we mentioned at the beginning, phishing has existed since the beginning of the Internet and will probably evolve and we will learn about new forms of this form of cyberattack. Although we must be vigilant in the face of these threats, slowing technological development is not the solution. The key is to adopt cybersecurity measures and educate users to minimize risks and create a safe working environment.
Cloud Computing is a service offered by several software providers paying a rent either by the hour, month or use of said service. They can be virtual machines, databases, web services, or other cloud technologies. These services are on remote servers provided by companies such as Google, Microsoft and Amazon among others that for rental or in some cases free of charge, provide such services. It is very convenient to have these services, since from a mobile phone or a not very sophisticated machine, you can have access to important services of all kinds just by having access to the internet.
The most common services provided in the cloud are as follows:
Storage in the cloud. Where the service allows multiple files, images, or other data to be stored in the cloud. It’s kind of like an internet-connected super hard drive.
Cloud Databases. You may access servers or databases such as SQL Server, PostgreSQL, MySQL, Oracle, etc. Note that you no longer need to access the entire server with the operating system (which is also possible). NoSQL databases, which are databases that do not use a relational database, can also be accessed. Instead of using tables, it uses documents or value keys to save the information.
Data Lake. The Data Lake service is, as the name suggests, a data lake. You may have structured, unstructured and semi-structured data. These services are used to manage what we know as Big Data. That is, lots of information. Today, data can no longer be handled in traditional databases exclusively without very large amounts of information. That is why other storage media such as Data Lakes are used.
Data analysis. Tools for analyzing data are also provided. There are tools for reporting, analytics using Machine Learning and other technologies.
Software in the cloud. There is the possibility of programming in different languages using cloud services. There are platforms to upload the code and websites.
Data Integration Services. Services such as AWS Glue, Google Cloud Data Fusion and Azure Data Factory among others, are services that allow you to integrate data. That is, copying data from one database to another or to a text file, moving data from a Data Lake to a database, etc.
Network Services. Networking services help connect on-premise applications with cloud applications. These services provide connectivity, security, and scalability. Some services offer gateways between the local network and the cloud. There is also the Virtual Network Gateway service. It connects the virtual network and the cloud. Another common service is the Load Balancer which distributes traffic between servers. There are also other Networking services such as application links, traffic handlers, etc.
Other Services. There are an infinite number of cloud services such as Machine Learning, AI, IoT…
How Cloud Computing Works
Saving is important. Instead of spending money on a good server or infrastructure, you may directly rent these cloud computing services. While the costs of renting cloud services from major vendors like Azure, AWS, and Google may seem high for small and medium-sized businesses, there are savings in staff.
A smaller team of IT professionals is required to maintain applications in the cloud. No time is wasted on hardware or many other aspects of security. While cloud service providers are not 100% responsible for security, much of the responsibility lies with them. They take care of the replications, of changing the hardware. Through a simple payment you may make your database server support more people connected simultaneously. That, in a local environment, would imply the purchase of new expensive servers and migrating information from one place to another.
Changing old hard drives, renewing servers, hardware problems, all of that is solved with the cloud, where you no longer have to worry about that aspect. Basically, it’s paying for the service and using it.
Services available
Some basic services are Microsoft 365 offering MS Word in the cloud, Excel, Word, PowerPoint, Outlook, OneNote, Publisher and Teams among other cloud applications. For example, documents in Excel are no longer saved on the hard drive but in the cloud. That is, on Microsoft Azure, servers to which you connect from your machine using the Internet.
Google offers Google Workspace which is similar to Microsoft 365. For example, it provides Google Sheets (a kind of online Excel), Google Docs (similar to MS Word), Gmail (similar to Outlook for emails), Google Slides (similar to MS PowerPoint).
Here are some of the many applications in the cloud. However, the cloud goes much further. It can offer Windows Servers, Linux. Databases of all kinds, whether relational or NoSQL, analytics services, IoT, Devops, websites, application programming platform, data analytics service, Machine Learning, APIs, cloud software and much more.
Examples of Cloud Computing
In everyday life we have been using cloud services for a long time. For example, Hotmail was the first service to use cloud technology. The concept of the cloud was not used then, but emails were stored on remote servers. Then came Yahoo’s mail services, Gmail.
Eventually Microsoft 365 arrived where it was already possible to use Word, Excel, PowerPoint, etc. using cloud technology. Then with AWS, Azure, Google Cloud and other providers, there are endless cloud services already mentioned above.
Source of the term Cloud Computing
Many people ask: what is the cloud? The term cloud computing is actually a metaphor. Since the 1960s, a cloud has been used to represent networks. Since 2000, the word has become popular and in a way indicates that the network is in heaven. That is, it is not within your physical reach but in another place that you may access through the internet.
History of Cloud Computing
As early as the 1960s, to represent networks, a cloud was used to represent them when they were connected to computers. However, it was not until the 1990s that the term began to be used to describe software as a service (SaaS). Through the service, machines connected to the internet without having to manage it from their computers.
However, the term became popular starting in 2000 with the rise of virtual machines and network computing. Cloud computing encompasses the multiple services offered on the network.
Importance of the Cloud
Large companies are taking their chances on the cloud. Microsoft for example upgraded its technology certifications to the cloud. The technologies located in the physical company have already been removed from the list of Microsoft certifications. Amazon on the other hand started in the cloud and was a pioneer. The trend is to spend less on an IT team and spend more on the rental of cloud services. Every year, the use of cloud services will grow more. According to Gartner, in 2025, 51% of IT services spending. They will be invested in the cloud.
Leading Cloud Providers
The following table shows the top cloud service providers and their market percentage:
As it can be seen in the table, AWS remains the leader and Microsoft maintains a second place. Google is in third place.
Key Elements of Cloud Computing
There are several types of services, which are IaaS, PaaS and SaaS. Below, we describe each one:
IaaS (Infrastructure as a Service) provides access to cloud services such as servers, storage, and networking. In this type of service, users are responsible for installing, configuring and managing the software and applications that are used.
PaaS (Platform as a Service) provides a complete platform for developing, running, and managing applications. In Paas, users are responsible for developing the application, however, the cloud provider is responsible for the underlying infrastructure and services.
SaaS (Software as a Service) provides access to complete applications over the Internet. The user does not have to install or manage the software, as all this is handled by the cloud provider.
Multi-Cloud Computing
Large companies usually choose to purchase different services from different cloud service providers. It is very common for a company to have services in Microsoft, Google and AWS. This is due to different factors such as price, IT service technical skills, some special offers from vendors, etc. Fortunately, major vendors are not very different from each other in their services.
Benefits of Cloud Computing
The main benefit is that users will not waste time on hardware maintenance, buying hardware, scaling and migrating servers. Business and IT teams will focus on business and applications. They’re not going to waste a lot of time on computer installations and configurations.
Advantages and disadvantages of Cloud Computing
As advantages, we already talked about a work reduction in software installation, security, installation time and hardware purchase. However, we hardly talked about the disadvantages.
In many cases, they are very expensive services. It is very common to hear jokes from people who say they went bankrupt for forgetting to turn off cloud servers. And there are services so expensive that they are paid by the hour, which, if you forget to turn them off, the cost increases considerably.
For example, suppose you have a cloud service that costs $100 an hour. $800 per day for 8 hours of use. However, imagine that the employee who uses it, forgot to turn off the machine in the cloud, that can make the service charge you $2,400 a day instead of $800. Another problem is that staff must be trained because if a hacker gets in the cloud, they can access all business information, which would make your company and its computers utterly vulnerable.
Widespread Adoption of Cloud Computing
There is a clear upward trend in the use of cloud services. In 2020, according to Gartner, 20% of the workload was handled by the cloud. In 2023, this figure doubled. Despite increased competition from cloud providers, the demand for cloud services and the benefits of companies offering these services are steadily increasing.
Challenges and Future of Cloud Computing
There are several challenges of cloud computing. IoT, or the internet of things, handles sensors. One may detect for example the status of the machines, maintain inventory, review production, track products. The use of cloud APIs, artificial intelligence services, is increasing. The cloud provides quite a few services and these are constantly increasing.
Conclusion
Cloud computing offers a host of services such as: data analysis, artificial intelligence services, web pages, application server, development platforms, DevOps and lots of others. The trend is to migrate much of the on-premise infrastructure to the cloud.
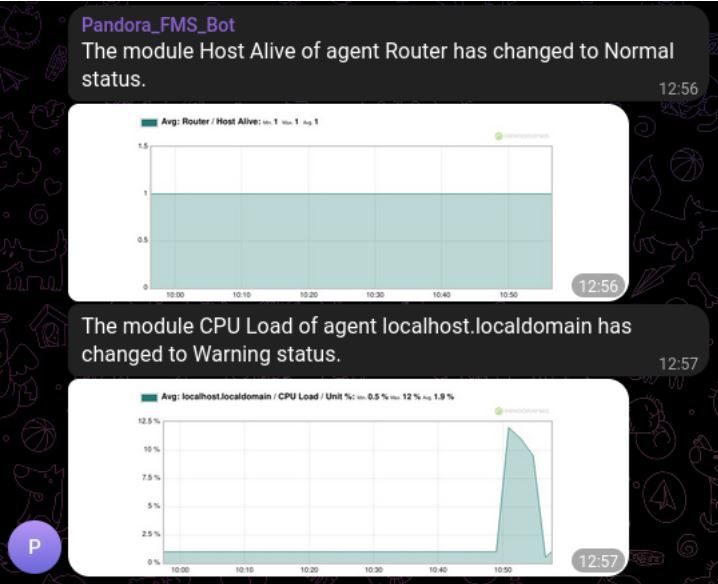
For environments where you have the need to know immediately if any issues arise, such as production environments, security or critical resources of your company, this Pandora FMS integration with Telegram is absolutely perfect, as it is the answer to that required immediacy, as well as the possibility of offering exact information about the location and cause of the problem, thanks to the powerful Pandora FMS system of alerts and macros.
Likewise, being a messaging service based on telephone communications through the data network, it guarantees your technicians, managers and on-call operators that they will find out aboutany problem at the exact moment it appears, without the need to access a computer or manually check their email.
Thanks to the plugins of your library and the flexible alert system offered by Pandora FMS, we will show you how to configure your monitoring tool to send instant messages whenever a problem is detected.
First of all, you must start from the necessary environment, whose requirements are:
Pandora FMS environment running on Linux, in this case we will use Rocky Linux 8, the distribution recommended by the manufacturer.
First of all, create the Telegram bot that will be in charge of sending messages. From the Telegram account you wish to use, you will have to interact with the user BotFather using the “/start”command:
Then use the comman “/newbot” to create your bot.
It will ask you for the name you wish your bot to have. Here specify the name you wish for your bot. It is important for the name to end with “bot”, for example Pandora_FMS_telegram_bot.
By sending you the name, if it is not in use, it will confirm that the bot was properly created, with a link to your chat and give you a Token that is important for you to save to set up the alert later.
Group Setup
Now enter the bot that you just created in an existing group you may have or a new one that you create, to receive your alerts.
The next step is to add another bot called GetIDs Bot to the same group in order to get the group identifier. By adding it, it will leave you a message with the ID of your group, and you should also take note of that for later.
With all of this you will already have your Telegram ready to receive alerts.
Integration with Pandora FMS (versions 773 and earlier)
First you should start by downloading our plugin Telegram bot CLI.
It will download a zip file called telegram-bot-cli.zip, which you should decompress.
Inside, you will find a file called “pandora-telegram-cli.py” which must be added to your Pandora FMS server in the path “/usr/share/pandora_server/util/plugin”.
Now, from the terminal of your server, install the Python3 dependencies (if you do not already have them) by means of the command “dnf install python3”:
Once installed, run the plugin to verify that it is running, through the command “python /usr/share/pandora_server/util/plugin/pandora-telegram-cli.py”:
We will now move on to Pandora FMS server console.
Go to the “Management > Alerts > Commands” section and click “Create”:
The command that we will use is for executing the plugin that you downloaded, with the arguments -t, -c and -m. It is important for the argument -m to be enclosed in quotation marks “”.
In the field of argument -t, Bot Token, enter the token of your bot.
In the field of argument -c, Chat ID, enter the ID of the group that bot “GetIDs Bot” provided you with.
And in the -m field, Alert Message, enter the alert message that you want your bot to send to the group. You may use all the alert macros you need, some examples are:
_module_: Name of the module that triggered the alert.
_agentalias_: Alias of the agent that triggered the alert.
_modulestatus_: Status of the module when the alert was triggered.
_agentstatus_: Status of the agent when the alert was triggered.
_data_: Data of the module that triggered the alert.
_timestamp_: Time and date the alert was triggered.
For example, you could use this message (which we will enter in field3): “The module _module_ of agent _agentalias_ has changed to _modulestatus_ status”
.
Once all this is filled in, click “Create”.
Now access the “Management > Alerts > Actions” section of your Pandora FMS console and click “Create” to create your action.
Enter the name you want your action to have, select the group, the alert command that you created previously and choose a Threshold. All the fields will be filled in automatically and click “Create”:
Now access the “Management > Alerts > List of Alerts” section and configure the alert for the Agent and Module you want.
In this case select that when the “Host Alive” Module of the “Router” agent goes into critical state, your previously created “Telegram Message” action will be executed:
If your module goes into critical state, you will receive this message to your Telegram group:
When your alert recovers you will receive a message like this:
Integration with Pandora FMS (versions 774 and later)
In version v7.0NG.774, the Telegram plugin of your library has been added by default to Pandora FMS alert, with a standard basic configuration.
If you access the Management > Alerts > Commands section, you will have a command called “Pandora Telegram”:
When accessing it, you will see that the command that will execute your alert is already configured.
Fill the -t “TOKEN” parameter of the command with the token given to you by BotFather and save the command:
After this, access the Management > Alerts > Actions section and access Pandora Telegram action.
At the bottom, add the Chat ID of your group that gave you the bot “GetIDs Bot” In the Triggering and Recovery sections, you may modify the message to your liking using the alert macro as you saw previously, and click “Update”:
Once saved, enter the Alert List menu from Management > Alerts > List of Alerts and create a new alert.
Select the agent and module, the action you updated “Pandora Telegram”, the template you want and create the alert:
Once your alert is triggered, you will receive your message by Telegram:
Sending alerts with data graphs
In our integration of Pandora FMS alerts and Telegram, you may add to the message a graph with the latest data of the module that triggered the alert, this applies both for version 773 and earlier and for 774 and later. You will be able to send graphs in your alerts by adding a call to the API of your Pandora FMS server to the script you used previously.
The first step that you must configure on your server is access to Pandora FMS API in the “Setup > Setup > General Setup” section, in the “API password” field you will have the API password and in the “IP list with API access” enter the IPs that need access or you may provide access to any IP (*).
Now edit the command that you had previously created to add the necessary data to send the graph. You need to add the following parameters:
–api_conf: Here indicate the configuration parameters of the API of your server, it is important to fill in the fields ” < >“:
“user=,pass=,api_pass=,api_url=http:///pandora_console/include/api.php”.
Example: “user=admin,pass=pandora,api_pass=1234,api_url=http://10.0.5.100/pandora_console/include/api.php”
–module_graph: Parameters of the module from which you will retrieve the graph, in this case there is two of them:
module_id: Where the ID of the module that triggered the alert is entered. In this case use the alert macro_id_module_ so that it is always filled in with the module ID of the alert.
interval: Total time interval shown in the graph, in seconds. We will use 3600 seconds by default, the equivalent of 60 minutes or 1 hour but you may configure the interval that best suits you.
The resulting full command will be as follows:
Command:
And field configuration:
And save the changes.
When the alert is triggered, you will receive the message with the data graph of your module:
We are all aware of the importance of attracting new customers for business growth purposes, but focusing solely on this goal is not actually the best decision. Delivering quality customer service is also key to success. For that reason, many companies that sell their products or services over the Internet have decided to implement an after-sales support service as a fundamental part of their business.
How to make yourself stand out among your competitors with a good after-sales support service?
More than a century ago, the Japanese businessman and philosopher Konosuke Matsushita, known for being the founder of Panasonic and one of the promoters of the “Japanese economic miracle”, laid the foundations of a revolutionary business philosophy for his time. Matsushita was based on concepts such as social contribution, teamwork, customer focus and technological innovation as differentiating factors. He wrote several works throughout his life, projecting his particular vision on business and society. Regarding after-sales support, he was of the opinion that: “After-sales service is more important than assistance before the sale, because it is through this service that permanent customers are achieved.”
These regular customers can really become your best brand ambassadors, so they should be pampered, so that they feel satisfied and share their positive experiences or make new purchases and hires.
How to offer a customer-centric after-sales service?
One of the biggest difficulties that companies encounter when managing customer service is how to convey closeness and proximity in a service as automated as IT support and offered remotely?
In the past, when there was no Internet, customers had to call a call center to solve their doubts or report any problems. Today, IT support centers use tools like chatbots that save human teams a lot of time. The use of these virtual assistants grew dramatically during the pandemic, allowing companies to respond to very high activity peaks and continue to offer 24/7 services.
However, by returning to normal, users are demanding a more conversational and less transactional customer service. Most of them rate chatbots positively as a way to get quick answers to their questions, but they don’t want machine interactions to completely replace people. For example, McKinsey’s “Next in Personality 2021” report reveals that 71% of customers expect businesses to offer custom interactions and 76% get frustrated when this doesn’t happen.
Finding the perfect balance between automation and human support is vital to offer a fast, efficient after-sales support service based on customer needs. You cannot swim against the tide or try to put a brake on digitization. On the contrary, we must rely on the advantages of technology by integrating it into the company’s IT support to access information in a unified way and know which requests can be automated and which need personalized attention.
How to integrate the IT support center to provide customers with good after-sales service?
IT support center integration needs to be planned carefully to ensure orderly and efficient business workflow.
Some essential steps for a successful integration are as follows.
Implementing a service management system (ITSM)
To manage any type of incident or complaint, it is essential to have a structured framework in which the policies to be followed by the support department are defined.
Professionals in this area are responsible for coordinating IT services with business goals. In addition, they train the team and define which tasks can be automated.
Create an IT support infrastructure
Companies that receive a high volume of requests may be in critical situations if they don’t have the tools that allow them to create dynamic workflows.
In this sense email is a painful management tool since it does not allow you to do things as basic as prioritizing important requests, keeping track of them, or escalating them to a higher level when the frontline support team is not able to solve them.
If you try to offer an after-sales support service through this means, you will soon see that the email inbox becomes saturated until it becomes a catch-all. No employee will know where to start!
Do you already know about Pandora ITSM Ticketing Helpdesk? This tool is all you need to make things easier for the support team and build customer loyalty.
As the name suggests, Ticketing Helpdesk works through a ticketing system. Each time a customer makes a request through the platform, a new ticket is opened with their data, date and subject of the incident.
Tickets are automatically cataloged according to their status: new, pending, solved, etc. You may also prioritize those that require immediate action, define automation rules or transfer complex cases that could not be solved to higher support levels.
Helpdesk Ticketing is a flexible tool and ready to work in an omnichannel environment. It can be easily integrated with other IT infrastructure tools such as project managers or CRM, to avoid process redundancy and take advantage of all the information available to improve the operation of other departments and the after-sales service itself.
Use the information collected to optimize customer service
As already mentioned, Ticketing Helpdesk collects query data, analyzes it and generates custom reports with relevant information such as:
Number of tickets closed
Number of tickets that remain open
Average ticket resolution time
Most common incidents
Performance of each agent (customer feedback)
Tickets that were escalated to higher levels
Keeping track of these metrics is very useful to know the long-term performance of the service and detect possible anomalies that would go unnoticed when analyzing isolated data.
It also ensures compliance with contractual agreements related to the service (SLA) such as downtime and support response capacity (for example, resolution of incidents in 24 hours). Respecting these agreements is important for building customer trust. In addition, non-compliance involves financial compensation that companies must assume. With the Helpdesk tool you may manage this key information and create automatic alerts if the service remains inactive for a long time.
Finally, in addition to automatic reporting, Pandora ITSM Ticketing Helpdesk also collects information from satisfaction surveys that users may answer by email or via a web form. It is a reliable way to know if the service is working as expected and the agents in charge of the support area effectively solve customer problems.
Still unsure whether Pandora ITMS will meet your expectations?
Try it for free for 30 days. You do not need a credit card, only advanced knowledge in the IT area and some free time to become familiar with all its features.
Does the support strategy set the foundation of business growth?
A solid support strategy not only guarantees the success of the company, but becomes an essential piece for its survival in a competitive environment.
Technological evolution has given a new dimension to the meaning of growth in the IT field.
In the constant search for innovative strategies to drive their development, IT leaders recognize the indisputable importance of technology in the evolution of a company.
Within this context, support and customer service present themselves as crucial elements to enable a company to:
Keep the continuity of its operations.
Optimize the productivity of their user and customer base.
Fulfill their commitments.
Encourage customer loyalty.
Business optimization through remote support: Savings and efficiency
Time, a sometimes priceless resource, reaffirms its position as the most valuable asset in business management.
In the art of managing time efficiently, lies the potential of saving considerable sums of money, since processes are streamlined and executed in fewer hours.
In this context, the use of remote support tools makes a tangible difference.
If we compare Traditional Support and Remote Support, we will soon reveal the impact of our choice in terms of costs.
Based on an analysis conducted by the Help Desk Institute, the financial disparity between solving an incident at the physical site and addressing it remotely is evident.
Although these data come from the United States, their usefulness as a reference for savings estimates around the globe is unquestionable:
Deploying remote support can reduce costs per ticket by a staggering 69%!
Damn wise Yankees!
Optimize your Service Desk: Cost reduction through Mean Operating Time (MOT)
Your Information Technology (IT) Department usually houses a series of indicators that trace the pulse of the support strategy implemented.
Among these indicators, the Average Handle Time (AHT) stands out.
This metric reveals the average length of time a support analyst works on a Service Desk ticket.
There is a correlation between the cost per ticket and the associated management time.
The speed in solving a ticket translates into a decrease in the related cost.
Every minute spent by an agent has an economic value, so solving it in 20 minutes is different from solving it in 40 minutes.
Likewise, the difference between a problem being solved at the first level or needing to be escalated to a higher level specialist has an impact on expenses, given that salaries vary markedly.
Thus, the First Call Resolution and First Level Resolution metrics determine the duration of ticket management and, consequently, the associated costs.
The approach of solving more tickets at the first contact with the customer, and addressing incidents from the initial support levels, entails unavoidably a reduction in the cost per ticket, a strategy that leads to considerable savings.
Remote support tools: The catalyst for efficiency and savings
The Corporate Remote Support capability is an essential tool for support departments, enabling them to securely and remotely connect to customer devices and equipment.
The premise is clear.
Take note:
Streamline incident management and safeguard the continuity of IT services and business operations
Within this context, one of the most valuable levers offered by a corporate remote support tool lies in its ability to reduce support costs, improving the Average Operating Time per ticket metric.
Are you looking to enhance efficiency in customer service?
Here comes the art of solving in the First Contact
Well, the time has come to focus on the First Call Resolution metric.
This indicator reflects the percentage of cases that are solved on the first contact between the customer and the Service Desk.
You need an accurate and structured solution with which you may quickly diagnose the incident, discarding of course outdated methods and taking an approach to accelerate support in a practical and efficient way.
If it is necessary to escalate the case to an advanced level technician, you must have a function that ensures that the solving process continues in the first interaction with the customer.
This approach avoids interruptions in the call or chat with the customer, as well as pausing the ticket and registering all the notes of the first contact, among other cumbersome tasks.
With this solution, the process is sped up by inviting the relevant technician, allowing the problem to be addressed immediately.
Imagine the significant time saved by smoothly inviting the right technician, resulting in successful resolution in the first interaction.
Shift-Left strategy: Key to reducing costs and freeing up resources in IT
One of the most notable trends in the Service Desk domain is the ongoing implementation of a “shift-left” strategy.
In the current era, the generation and maintenance of a competitive advantage is inseparable from this continuous improvement.
Let’s go back a second to the previous point and get deductive:
The hourly cost of specialist technicians far exceeds that of tier 1 analysts.
If we look at the average cost of solving tickets according to the support level in America, the disparity between the resolution at the first level (22 USD) and at the third level (104 USD) is evident.
This difference becomes almost five times higher.
Therefore, by focusing on strengthening the shift-left strategy and seeking to solve a higher number of tickets from the initial support levels, we will achieve two vital goals:
Reducing costs per ticket: This action directly contributes to optimizing operating expenses.
Freeing up high-value resources: By decreasing the burden on advanced technicians, they are given more time to engage in high-impact activities within the IT department.
So the remote support tool emerges from the waters as an invaluable ally to take the shift-left strategy to new heights.
Conclusions
In the technological maelstrom in which we live, great IT leaders have discovered that constant growth demands facing formidable challenges.
That’s when the Service Desk shines as an essential pivot.
We explored how support strategies shape the corporate expansion landscape and how remote assistance becomes an effective pillar for the evolution of the Service Desk.
Savings and efficiency rooted in these practices are not just goals, but tangible realities.
What’s the moral of the story?
Of course, this is a great article:
In cosmic ballet, time is the undisputed protagonist.
Smart investment in remote support tools not only cuts expenses, but adds seconds to the dance, unlocking untapped potential.
Thus, the road to optimization is paved with savings and smiles.
The clock is ticking, and we, with ingenuity, are speeding towards tomorrow!
BOOM!
Would you like to find out more about how Pandora FMS can help you?
What is remote access and how has it transformed work dynamics around the world? Let’s dive in, explore and discover together how this innovative practice has reshaped conventional work structures and opened up a whole range of possibilities!
Remote access or remote connection, itself, is a virtual portal that links your work tasks to the physical location of your choice. Instead of being tethered to a boring desk in an office, this technology allows workers to access computer systems, files, and resources from anywhere with an Internet connection. *Picture wearing your swimsuit and typing from the Maldives.
At the heart of this revolution is the ability to interact with platforms and data through virtual interfaces, which blurs the boundaries between the traditional grid office and a more flexible work environment (and with the possibility of an afternoon at the beach bar!).
What is remote access for?
The function of remote access transcends the limits of mere convenience. It has proven to be a crucial tool for companies and workers in different circumstances. During exceptional times, such as that global pandemic, that everyone seems to have forgotten, the way we worked as we knew it changed completely. In fact, this technology became a lifeline for business continuity. A notable example is in Spain, a large and free country, where the adoption of teleworking spiked surprisingly, with 80% of companies implementing remote access to maintain productivity in the midst of chaos.
Remote connection: Go beyond geographical borders
As it is obvious, the impact of remote access is not limited to a single region. Colombia, for example, has experienced a staggering 400% increase in the number of remote workers compared to previous years. This underlines and highlights how the adoption of this practice has transcended geographical borders and has become an essential step in the transformation of the working world.
Safe remote access: A tool for security and collaboration
In a scenario where cybersecurity is a constant priority, remote access rises as a neat yet elegant solution. For those who handle sensitive or valuable information, this method provides a safe alternative to local storage on personal devices. By authenticating on enterprise platforms, workers can access data without compromising their integrity or that of the company. Security, therefore, becomes one of the indisputable advantages of remote access. Peer collaboration is enhanced by remote access, as physical barriers are no longer obstacles to communication and teamwork. Video conferencing and task management tools can be activated with ease, enabling interaction and workflow no matter the distance. Remote access technology also plays a vital role in correcting errors and delivering important projects. Even if team members are not physically present, their contribution can flow consistently and effectively, ensuring project efficiency and responsiveness in the ever-changing world of work.
Labor productivity: Transforming business dynamics
In the fabric of the work evolution, remote access has become a common thread that unites productivity with flexibility at work. As we explore this revolutionary practice further, the many benefits it offers to businesses and their workers, as well as the fundamentals of how it works, are revealed. Remote access not only redefines the way we work, but it also drives unparalleled business efficiency. Among its most notable benefits, there are substantial time and money savings. While the initial investment in remote access software may seem like an expense, financial and operational rewards are significant. By getting rid of commuting time, workers can quickly immerse themselves in their tasks, while businesses save on electricity and supply costs. The virtual office stands as a sustainable and economic alternative, where it is only necessary to turn on a computer or tablet, enter the credentials and be ready to work.
Components and operation
Remote access is built on the convergence of three key elements:
Software.
Hardware.
Network connectivity.
Currently, these items are routinely synchronized through a Virtual Private Network (VPN)which creates a safe link between users and systems through wired network interfaces, Wi-Fi connections, or even the Internet. The VPN plays a momentous role in establishing a connection between individual users and private networks. Once the user enters the software, it encrypts the data traffic before directing it through the Wi-Fi network. This process is known as a “VPN tunnel”, which ensures the privacy of the flow of information. The data is then decrypted and sent to the specific private network. For this process to be successful, both the computer from which the user connects and the one seeking access must be equipped with compatible communication software. Once the user connects to the remote host, access is granted to a virtual desktop that replicates the conventional work environment.
Successful implementation of remote access
The journey to a successful implementation of remote access in an enterprise is an exciting journey that requires meticulous planning and attention to detail. As you embark on this journey, here are four key tips that will guide you through a smooth and safe transition.
1. Training
Training is the foundation upon which a successful implementation of remote access is built. Providing your employees with a clear understanding of how it works and how to use it effectively is essential. An organized approach, planned by areas and departments, ensures that everyone is on the same page. By encouraging open communication, doubts can be solved and obstacles overcome more easily. Remember that an investment in training not only boosts productivity, but it can also increase the company’s profit margin by 24%.
2. The right tools
Equipping your employees with the necessary tools is a crucial step. Make sure everyone has a desktop or laptop with the remote access software installed. It’s critical to check your team’s preferences and provide viable alternatives. Each contributor must have a user configured with VPN connectivity to ensure safe access.
3. Remote access security
Security is the pillar that underpins any successful company. *Safety and the coffee machine. In the world of remote access, it is reinforced by two-factor authentication. This multi-factor authentication approach adds an additional layer of protection, reducing vulnerability to security breaches and information leaks. Options such as physical token, mobile phone authentication, or biometrics, such as fingerprinting, are effective ways to ensure that only authorized people have access to sensitive information.
4. Connectivity
The safe and efficient connectivity is the backbone, which is not a pillar, we have already used that analogy before, of a successful implementation of remote access. Installing a wireless access point backed by a robust firewall is a critical step. Leading enterprise firewalls not only protect against cyber threats, but also offer advanced capabilities such as network monitoring and support for mobile connections. These firewalls can be a vital defense to ensure information integrity and maintain operational continuity.
Exploring the Horizon: Remote access tools
As you get deeper into deploying remote access, there is a world of tools available to make this change effective and beneficial for your organization. Compiling a list of options and comparing their features can help you make informed decisions. Each tool has its own advantages, so it’s important to find the one that fits the size of your company, the number of collaborators, and the type of industry you’re in.
We advise you Pandora RC
As a culmination of our exploration in the world of remote access, we present a revolutionary solution that simplifies and enhances this essential practice: Pandora RC, a computer management system that supports MS Windows®, GNU/Linux ® and Mac OS®, is the bridge that connects users with their computers anywhere and at any time, all through a web browser and without the need for direct connectivity. Rooted in careful planning and effective implementation, Pandora RCreveals its magic with a simple process. Before you can remotely access a device, you need to install an agent and register it on the central Pandora RC server. This process requires a valid user on the platform. Once the agent is configured with a user and activated, it will be provisioned and ready for remote connection.
The user portal will display the provisioned devices, each identified with a unique Key ID. This identifier, designed for accurate identification, ensures collaboration between users and enables efficient tracking in internal inventory systems.
Safety is critical at Pandora RC.
Each agent can have an individual password configured during installation or later. This password is interactively entered at each access, ensuring that sensitive information is protected and not stored on Pandora RC central servers. Pandora RC architecture ensures seamless connectivity. Agents connect to servers on the internet, and if necessary, they can be configured to use a proxy in case they cannot connect directly.
Conclusions
In a world where technology transcends boundaries and creates new horizons, remote access stands as an open door to productivity and flexibility. This concept has transformed global labor dynamics, blurring physical barriers and redefining how and where we work. Remote access has proven its vitality in exceptional situations, as it did in the pandemic and will do so in the apocalypse, by maintaining business continuity and enabling businesses to thrive in changing environments. From Spain to Colombia, mass adoption has marked a milestone in labor evolution, showing how collaboration and efficiency know no geographical boundaries. Security, a constant concern in the digital age, is addressed with advanced authentication and encryption solutions in remote access. In addition, this practice makes remote collaboration easier, driving seamless videoconferencing and workflows. The successful implementation of remote access requires training, adequate tool supply, enhanced security, and robust connectivity. This process can be catalyzed by solutions such as Pandora RC, which has taken the remote access experience to the next level, democratizing the connection with machines and getting rid of location limitations. Ultimately, remote access not only changes the way we work, but redefines efficiency, security, and collaboration in today’s workplace landscape. A digital revolution that invites us to navigate towards a future where productivity has no borders and flexibility is the standard.
Increase team collaboration quality and speed in emergencies with Pandora FMS and ilert’s ChatOps features
Pandora FMS is an excellent monitoring system that helps collect data, detect anomalies, and monitor devices, infrastructures, applications, and business processes. However, more than monitoring alone is needed to manage the entire incident lifecycle. ilert complements Pandora FMS by adding alerting and incident management capabilities. While Pandora FMS detects anomalies, ilert ensures that the right people are notified and can take action quickly. This combination helps reduce the mean time to resolution (MTTR) and minimize the business’s impact.
While Pandora FMS and ilert are reliable and robust foundations for your system’s resilience, the magic of team collaboration and real-people decisions happens in chats. This trio of tools is indispensable in today’s business world. In this article, we will provide practical recommendations on evolving your ChatOps and enhancing the speed and quality of incident response.
ChatOps is a model that connects people, tools, processes, and automation into a transparent workflow. This flow typically centers around chat applications and includes bots, plugins, and other add-ons to automate tasks and display information.
As a model, ChatOps means that all team communication and core actions are taking place right in a chat tool, which eliminates the need to switch between the services and makes it possible to orchestrate the work from one platform. As there is a variety of chat tools on the market, there are, for sure, two of the most commonly used among IT teams. Those are Slack and Microsoft Teams. As for the available data, they have 18 million and 270 million users, respectively, and those numbers are growing consistently for both companies.
As there is a wide variety of implementations of the ChatOps model to everyday work, we will concentrate specifically on how to manage incidents through ChatOps.
ChatOps and Incident Management: What is it all about?
The fusion of monitoring and incident management platforms with ChatOps is a manifestation of modern IT operations aiming to optimize efficiency, speed, and collaboration. By marrying these paradigms, organizations can capitalize on the strengths of the tools, leading to streamlined incident resolution and enhanced operational visibility.
At the core of ChatOps lies real-time collaboration. When an incident arises, time is of the essence. Integrating ChatOps with an incident management platform ensures that all team members—be it developers, support, or management—are immediately aware of the incident. They can then collaboratively diagnose, discuss, and strategize on remediation steps right within the chat environment. This kind of instant cross-team collaboration reduces resolution time, ensuring minimal service disruption.
Here are other advantages that integrated ChatOps provides in times of incident response.
Centralized information flow
ChatOps can funnel alerts, diagnostics, and other relevant data from various sources into a single chat channel. This consolidation prevents context-switching between tools and ensures everyone has access to the same information.
Team awareness
Everyone involved in the incident response has a shared view of the situation. This shared context reduces miscommunication and ensures everyone is aligned on the incident’s status and the response strategy.
Detailed overview
Every action taken, command executed, and message sent in a chat environment is logged and timestamped.
Accountability
With each chat action being attributed to a team member, there’s clear accountability for every decision and command. This is especially valuable in post-incident reviews to understand roles and contributions during the incident.
Automation
Through chat commands, responders can trigger predefined automated workflows. This can range from querying the status of a system to initiating recovery processes, thereby speeding up resolution and reducing manual efforts.
Accessibility
With many ChatOps platforms being available on both desktop and mobile, responders can participate in incident management even when away from their primary workstation, ensuring that expertise is accessible anytime, anywhere.
9 Tips on How to Squeeze Maximum out of ChatOps in Times of Incidents
ChatOps provides a synergistic environment that combines communication, automation, and tool integration, elevating the efficacy and efficiency of incident response. But what exactly do teams need to uncover the full potential of their chats?
We won’t dive deep into instructions on how to connect Pandora FMS with the ilert incident management platform, but you can find related information in Pandora FMS Module Library and a step-by-step guide in ilert documentation. Find below a list of best ChatOps practices for organizing your workflow when an alert is received.
Use dedicated channels
Create dedicated channels for specific incidents or monitoring alerts. This helps to keep the conversation focused and avoids cluttering general channels. And don’t forget to set a clear name for those channels. In ilert, the pre-build title includes the name of the monitoring tool and the automatically generated number of an alert, for example, pandorafms_alert_6182268.
Allow users to report incidents via your chat tool
Enable all users to report incidents through Slack or Microsoft Teams using pre-set alert sources for each channel. This approach empowers teams to have a structured method for reporting concerns related to the services they offer within their dedicated channels.
Decide on what channels should be private
Most chat tools provide functionality to create public channels that are searchable across an organization and can be viewed by all team members, and private where only specific people can be invited. Here are a few reasons why you might want to create a private channel:
Sensitive data exposure. Such as personal identification information (PII), financial data, or proprietary company information.
Security breaches. In the event of a cyberattack or security compromise, it’s important to limit knowledge about the incident to a specialized team. This prevents unnecessary panic and ensures that potential adversaries don’t gain insights from public discussions. You can read more on how to prevent data breaches in the article “Cyber Hygiene: Preventing Data Breaches.”
High-stakes incidents. If the incident has potential grave repercussions for the organization, such as significant financial impact or regulatory implications, it’s beneficial to restrict the discussion to key stakeholders to ensure controlled and effective communication.
Avoiding speculations. Public channels can sometimes lead to uncontrolled speculations or rumors. It’s best to keep discussions private for serious incidents until the facts are clear and an official narrative is decided upon.
Keep all communication in one place
Ensure that all decisions made during the incident are documented in the chat. This assists in post-incident reviews.
Pin important messages
Use pinning features to highlight essential updates, decisions, statuses, or resources so they’re easy for anyone to find.
Keep stakeholders informed
Ensure you keep your team in the loop and update all incident communication, including public and private status pages, in time.
Use chats in post-mortem creation
The real-time chat logs in ChatOps capture a chronological record of events, discussions, decisions, and actions. During a post-mortem creation, teams can review this combined dataset to construct a comprehensive incident timeline. Such a detailed account aids in pinpointing root causes, identifying process bottlenecks, and highlighting effective and ineffective response strategies.
Regularly clean up and archive
To maintain organization and reduce clutter, regularly archive old channels or conversations that are no longer relevant. Avoiding numerous channels in your list will also speed you up when the next incident occurs.
Provide regular training for all team members
The more familiar your team is with tools, alert structure, chat options, and features, the quicker you will be when the time comes. Trigger test alerts and conduct incident learning sessions so that everyone involved knows their role in the incident response cycle.
There are notification options in a monitoring application as flexible as Pandora FMS, but regardless of how many options it includes, it is not a specific application to cover the complexity of the notification flows of a complex organization, which requires integrating many systems that generate notifications. It is not the same detecting a process down, receiving an asynchronous event through a WEB API or processing an email, just to mention three possible alert sources in a complex environment. Pandora FMS is good at monitoring and there are hundreds of plugins published in Pandora FMS public module library.
In addition, receiving an email or SMS is easy today, now the complex thing is to provide each user with their favorite notification system (SMS, email, voice call, Whatsapp, Telegram) and for the configuration to be fast, easy and centralized. Anything is possible, but it takes time and is subject to failure. Do you want the notification to fail because an API changed? Can you really afford not to receive a notification?
That’s why ilert makes the most sense to you.
It is not because Pandora FMS cannot send notifications directly, it is because sometimes you just need to implement a convergence of notifications from other sources, sometimes you do not have time to implement the complexity of a complex notification workflow that includes push technologies such as Whatsapp or Telegram and you may want to delegate this to a specialized cloud provider, such as ilert.
For all purposes, ilert works as a notification funnelthat collects all notifications from different sources, once received, and thanks to a very complete scaling system, workflow rules, group/user system and notifications, it develops all necessary actions, regardless of the notification sources, their format, frequency or structure.
ilert can also be integrated with your ITSM or used to enrich alerts. It can also be integrated with Pandora ITSM.
Setup in 5 minutes
Signing up for ilert takes less than 30 seconds. The next step is to configure users to receive different types of notifications: voice call, SMS, Whatsapp, Telegram or email. From this account you may receive notifications from Pandora FMS or from a script, from another application or from workflows as manual and wide ranging as receiving an email. The API in ilert is flexible, simple, and allows you to get your project up and running in minutes.
Setting up the user (and how you want to receive notifications)
The first thing is to configure a user (if you already have one created, configure/enable the different notification methods). Let’s look at this example, where email sending (by default), SMS, voice calls and Whatsapp are configured:
To activate each of the systems, it will ask you to activate it. To do it through Whatsapp, it notifies you through your cell phone to ask for confirmation, and you just have to click. The same goes for voice calls, SMS, email, etc. You don’t have to install or do anything.
Each user has their own notification systems. User groups (teams) can be created and groups can be notified. There is the possibility of creating rules for notification, scaling, etc. The power of ilert lies in how it manages notifications from third parties.
The notification “order” or priority is established in the notification screen of the configuration of each user:
Configuring notification escalation
If you edit the values that come by default, you will see that it is a set of simple rules. It allows you to define the alert escalation flow, based on people. Each person/user has already configured their notification system (SMS, call, etc.).
Since all the scaling logic (time windows, repetitions, workflows) is in ilert, do not forget that the “alert sources” send you multiple alerts, ilert will help you filter and sort out things.
Creating notification sources
Here is where the interesting begins. Let’s define how you may add alerts to ilert. To show the power of ilert, not only are we going to integrate Pandora FMS, but we are going to integrate two other very different sources: generic emails and another for use in an API from a script.
ilert alerts using an email as source
This is one of the easiest. As simple as sending an email to a specific address, and that will launch an alert. To that end go to Alert sources > Create new alert source and then filter the results by “mail”:
Use that source (email) and fill in some data:
If you have not yet created a “Team”, you may create it later. Accept the following screen with default values and finally configure the email to which you will send the notifications:
In a very similar way, create a “Pandora FMS” data source, which comes by default in the ilert alert source library.
After following all the steps, it will return some data that you will need to integrate the alert with Pandora FMS:
Now it’s the time to “connect” your Pandora FMS with ilert, for that you will need the API Key. You may use ilert in any Pandora FMS version (even the older ones), but since version 775 it already comes “as standard” integrated into the action system. We are going to describe how to implement it from scratch, perfect if your version is older. If you already use a Pandora FMS 775 or higher, you may skip almost all of the following steps (command creation, action creation) and you may directly edit the action that comes by default with Pandora FMS for ilert to set the API Key generated in the previous step.
To create an ilert notification with Pandora FMS, follow these three steps: Create a command, an action and associate an alert template with that action.
Create the command in Pandora FMS to call ilert
Download the script from Pandora FMS’s own plugin library, at https://pandorafms.com/library/ilert-integration/. In Pandora FMS 775 and later, it is already installed as standard, you do not have to follow this step (we also use our own version of the integration, which is a little more complete). To see how to install/use the ilert tool itself, just keep reading
For that you have to enter the pandora server by shell, download the file, decompress it and add it to the indicated path. It is summarized in the following commands (executed as root):
cd /tmp
wget https://pandorafms.com/library/wp-content/uploads/2022/11/pandorafms_ilert.sh.zip
_field1_ : ilert alert source API key. _field2_ : Type of the created event. Can be “alert” or “resolved”. _field3_ : Title of the event. _field4_ : Description of the event.
Once created, it will be available as a command:
Creating an action using the ilert command
We are going to create an action, which is like the alert, it will execute the command (with certain parameters) for each specific case. We are only going to create a certain case (action), but you could define several if you needed to. In there we will configure only field 1 (API Key), copied from the ilert configuration and field 2 (alert type), specifying “Alert” when it is triggered and “Resolved” when it is recovered.
That way, any use you make now of the “ilert General” action will already contain the APIKey and you will not need to specify it.
Creating an alert using the ilert action
Create an alert about a module (in this example, a disk one), which uses your command through the newly created action:
ilert Alerts using a generic external API as source
Imagine that Pandora FMS process itself can not be activated because the database failed, how would you notify it?, well, also with ilert!
For this purpose, create a hook via API, so that it can be called from any script.
First create an API as an alert source:
When you finish configuring it, it will return a reference to be able to use it:
To enter a notification into ilert, just run this command from any shell:
curl -X POST -H “Content-Type: application/json” \
-d ‘{“apiKey”: “il1api10230c21209d93294006a2fa47528fae069bc8f2f0820e”,”eventType”: “ALERT”,”alertKey”: “Pandora General Alert”,”summary”: “Something goes wrong”}’ https://api.ilert.com/api/events
The only thing you will have to replace is apiKey by your own. Only with this execution you may launch an alert to ilert from any script. It is a perfect way to make sure, for example, that if everything fails, at least you will know that everything failed. If you do not know how to make that script, you may check Pandora FMS community, in addition to being experts in monitoring, we master Linux.
What does an ilert alert look like?
By e-mail:
By SMS:
By WhatsApp:
And of course, in the ilert control interface where you may do many things with the alert:
Advanced uses of ilert: event correlation with Pandora FMS
With Pandora FMS one can monitor 20 servers or 2000. It is easy to imagine that if you happen to have dozens of metrics on each server, assigning an alert to each and every module can be a burden. We have tools like policies or the bulk operations manager to assign hundreds of alerts in one go, but even so, it’s complex and cumbersome.
The perfect solution in these cases is to assign alerts by “concepts”, let’s see some cases:
Assign an alert when MySQL processes fail, without looking at which machines they are on. To do this, you would assign alerts on any failure event of a specific module, regardless of the agent.
Assign an alert when something happens in modules marked with a label, for example “Critical Infrastructure”.
Assign an alert when something happens in any data source of a group of systems that belong to a group, for example “Production environment”.
Assign an alert when complex conditions are met, for example: “Failure of any MySQL process” in “the group of production machines”.
Assign more complex conditions, such as the previous ones, using logical operators (AND, OR, NOT, XOR…) in time windows.
For this there are event alerts or event correlation alerts. They work on the events generated by modules, not on the modules but on their data. This allows operating on more generic concepts, not on specific data, since a fail event of a MySQL process is the same in one machine as in another (if the module is called the same), the same as a fail event is a fail event, no matter the agent or no matter the module. Therefore, applying rules on events is much more efficient and intuitive than doing it on modules.
Example of defining an event correlation alert.
If you also add ilert to the event alerts, you can further optimize the process, because ilert has additional logic that you may use together with that of Pandora FMS. With Pandora FMS it is possible to set special day calendars, scheduled downtimes or time slots, you may also set escalation rules and many other things, but ilert allows you to do so on alerts from other data sources that are not integrated with Pandora FMS.
It has again made the headlines due to its decision to downsize, adding a new wave of layoffs to the approximately 10,000 employees who were terminated earlier in the year.
While sales department layoffs are common when companies are looking to reduce their costs, it’s not the only department affected:
Hiring, marketing, and customer service functions also often bear the brunt when the revenue becomes uncertain.
A clear example of this trend was evidenced in Crunchbase, a business data platform.
After announcing its recent downsizing, it was possible to see in a spreadsheet the departments in which the startup considered that they could cut some expenses:
Sales
Customer service
Marketing
Hiring
Even Crunchbase News, a team that encouraged the dissemination of relevant news, was affected by this decision
It is worth mentioning that the situation is personal for some, such as those who participated in the construction of the team while working in the company and still retain shares of the company.
*We will call them “Martyrs”.
Despite this seemingly ingrained trend, the landscape of tech layoffs is showing signs of change.
A detailed analysis of Layoffs.fyi, a database that tracks downsizing in the tech sector, reveals an interesting trend in the making.
Since the peak of layoffs in January 2023, the number of tech workers affected by them has been steadily decreasing.
This suggests that companies are finding new approaches to maintaining financial stability while retaining the talent that drives innovation in the sector.
*Good thing someone cares, right?
As we move into this era of constant technological transformation, the future of tech layoffs looks uncertain.
Will companies be able to find a balance between the need to adjust expenses and talent preservation?
Will layoffs become a less frequent measure?
These questions will remain at the heart of the debate as companies seek to adapt to an ever-changing environment and strive to ensure a sustainable future for both their businesses and their employees.
Impact of layoffs in the technology sector during 2023
As we get through the year 2023, the tech sector has witnessed a significant trend when it comes to the number of workers laid off.
Analyzing the figures collected on Layoffs.fyi, it is clear that the beginning of the year was gloomy for many employees in the industry.
During the month of January, a staggering total of 89,554 workers were unemployed due to adjustments made by different companies.
However, the figures began to show signs of change in February, when the number of layoffs dropped noticeably to 40,011.
This decrease continued in March, with a total of 37,823 employees affected by the downsizes in that month.
The month of April brought with it a new decrease in layoffs, standing at 19,864 workers.
As we moved towards the end of the year, the downward curve continued, reaching 14,858 layoffs in May and falling further to 10,524 in June.
These figures reflect a positive change in the trend of technology layoffs throughout the year.
It seems that companies have been looking for other alternatives to keep their operations in the midst of economic difficulties.
*Minipoint for companies.
The steady decline in layoffs suggests that companies are adopting a more cautious and strategic approach to adjust their costs, rather than resorting to mass layoffs as a first option.
This outlook could be a sign that tech companies are adapting to an ever-changing environment, finding more sustainable ways to manage their human resources.
In addition, the reduction in layoffs may be a response to the growing awareness of the importance of talent and innovation in the development of the technology sector.
As we head into the second half of the year, it will be interesting to see how this trend evolves.
Will the decrease in technological layoffs continue, or will there be unforeseen factors that can reverse this positive trend?
The future remains uncertain, but data suggests that the tech sector has learned its lessons from the past and is seeking a more stable and balanced future for its employees and their sustainable growth.
Conclusions: New management era. Reduction of layoffs in the technological field
The era of technological layoffs has undergone a significant transformation over the course of the year 2023.
Although the beginning of the year was characterized by a worrying number of dismissed workers, the figures have shown a constant decrease in the subsequent months.
This change in trend suggests that tech companies are rethinking their approach to reducing costs and managing their human resources.
Traditionally, layoffs in the tech sector have impacted departments such as sales, marketing, hiring, and customer support.
*Wow, always marketing, ALWAYS! KEEP IT UP, COMRADES!
**I’m marketing
However, this practice seems to be giving way to a mindset more focused on retaining talent and preserving innovation.
Companies may be recognizing the strategic value of having highly skilled and engaged employees in a highly competitive environment.
Layoffs.fyi’s analysis has provided valuable insights into the evolution of the employment situation in the technology sector.
The sustained decline in layoffs from January to June has been encouraging and has raised the question of whether companies are taking more balanced and responsible approaches to addressing economic challenges.
The new era of job stability in the technology sector represents not only a change in management practices, but also an opportunity for companies to redesign their vision for the future.
Prioritizing talent investment and fostering a business culture that values creativity and collaboration can be the key to maintaining a competitive edge in an ever-changing tech world.
However, the future remains uncertain, and it is possible that economic conditions and other unforeseen factors could alter this positive trend.
It is critical that companies continue to be agile and flexible in their approach to adapting to changing circumstances.
*Please, tech companies, don’t be so cold towards your employees.
As a good technology superhero you will know that in the world of troubleshooting, there is an approach that goes beyond simply fixing superficial symptoms. We call this approach “Maximum Heroics” or Root Cause Analysis (ACR), a charming method that seeks to unravel the mysteries behind an incident.
Through the RCA, the causal factors of an incident are examined, and why, how and when it happened are broken down in order to prevent it from repeating itself and ensure smooth continuity.
Anticipate issues, optimize your systems and processes with RCA
Imagine this post-apocalyptic scenario: a system breaks down or undergoes an unexpected change, surprising all of those who depend on it.
This is where RCA comes into play, as an indispensable tool to fully understand the incident and what triggered it.
Unlike simple troubleshooting, which focuses on taking corrective action once the incident took place, RCA goes further, seeking to uncover the root cause of the problem.
Sometimes RCA is also used to investigate and understand the performance of a particular system, as well as its superiority performance compared to other similar systems.
However, in most cases, root cause analysis focuses on problems, especially when they affect critical systems.
Through a RCA, all the contributing factors to the problem are identified and connected in a meaningful way, allowing a proper approach and, most importantly, preventing the same adversity from happening all over again.
Only by getting “to the root cause” of the problem, rather than focusing on surface symptoms, you may find out how, when and why the problem arose in the first place.
There is a wide range of problems that warrant a root cause analysis and they might come from a variety of sources, from human errors to physical system failures to deficiencies in an organization’s processes or operations.
To sum up, any type of anomaly that affects the optimal functioning of a system may require the implementation of an RCA.
Whether it’s faulty machinery in a manufacturing plant, an emergency landing on an airplane or a service interruption in a web application, investigators embark on a journey to uncover the hidden layers of each incident, in search for the ultimate solution.
Pursuing Continuous Improvement: The advantages of Root Cause Analysis
When it comes to maintaining the integrity and smooth operation of an organization, root cause analysis becomes an invaluable ally.
With the primary goal of reducing risk at all levels, this revealing process provides vital information that can be used to improve system reliability.
But, what exactly are the objectives and advantages of performing a root cause analysis??
First, root cause analysis, as we already know, seeks to identify precisely what has actually been happening, going beyond the superficial symptoms to unravel the sequence of events and root causes.
Understanding what is needed to solve the incident or taking advantage of the lessons learned from it, taking into account its causal factors, are some other key objectives of RCA.
In addition, repetition of similar problems is avoided, leading to an improvement in the management quality.
Once these goals are achieved, an RCA can provide a number of significant benefits to an organization.
First, systems, processes and operations are optimized by providing valuable information about the underlying problems and obstacles.
In addition, repetition of similar problems is avoided, leading to an improvement in the quality of management.
By addressing problems more effectively and comprehensively, you may deliver higher quality services to your customers, thereby generating customer satisfaction and loyalty.
Root cause analysis also promotes improved internal communication and collaboration, while strengthening the understanding of the underlying systems.
In addition, by quickly getting to the root of the problem instead of just treating the symptoms, the time and effort spent on long-term resolution of recurring problems is significantly reduced.
Moreover, this efficient approach also reduces costs by directly addressing the root cause of the problem, rather than continually dealing with unresolved symptoms.
More importantly, root cause analysis is not limited to a single sector, but can benefit a wide range of industries.
From improving medical treatment and reducing workplace injuries, to optimizing application performance and ensuring infrastructure availability, this methodology has the potential to drive excellence in a variety of systems and processes.
The Foundations of Root Cause Analysis: Principles for Success
Root cause analysis is a versatile enough methodology to adapt to various industries and individual circumstances.
However, at the core of this flexibility, there are four fundamental principles that are essential to ensure the success of RCA:
Understand the why, how and when of the incident: These questions work together to provide a complete picture of the underlying causes.
For example, it is difficult to understand why an event occurred without understanding how or when it happened.
Investigators must explore the full magnitude of the incident and all the key factors that contributed to it taking place at that precise time.
Focus on underlying causes, not symptoms: Addressing only symptoms when a problem arises rarely prevents recurrence and can result in wasted time and resources.
Instead, RCA focuses on the relationships between events and the root causes of the incident.
This approach helps reduce the time and resources spent solving problems and ensures a sustainable long-term solution.
Think prevention when using RCA to solve problems: To be effective, root cause analysis must get to the root causes of the problem, but that is not enough.
It must also enable the implementation of solutions that prevent the problem from happening all over again.
If RCA does not help solve the problem and prevent its recurrence, much of the effort will have been wasted.
Get it right the first time: A root cause analysis is only successful to the extent that it is performed properly.
A poorly executed RCA can waste time and resources and even make the situation worse, forcing investigators to start over.
An effective root cause analysis must be carried out carefully and systematically.
It requires the right methods and tools, as well as leadership that understands what the effort entails and fully supports it.
By following these fundamental principles, root cause analysis becomes a powerful tool for unraveling the root causes of problems and achieving lasting solutions.
By fully understanding incidents, focusing on underlying causes and taking a preventative approach, organizations can avoid repeat problems and continuously improve their performance.
Ultimately, root cause analysis becomes the foundation upon which a culture of continuous improvement and excellence is built.
A Range of Tools: Methods for Root Cause Analysis
When it comes to unraveling the root causes of a problem, root cause analysis offers a variety of effective methods.
One of the most popular approaches is the 5 whys, where successive “why” questions are asked to get to the underlying causes.
This method seeks to keep probing until the reasons that explain the primary source of the problem are uncovered.
While number five is only a guide, fewer or more “why” questions may be required to get to the root causes of the problem initially defined.
Another method widely used in RCA is the “Ishikawa Diagram”, also known as “Cause and Effect Diagram” or “Fishbone Diagram”.
In this approach, the problem is defined at the head of the fishbone, while the causes and effects unfold at the branches.
The possible causes are grouped into categories that are connected to the backbone, providing an overview of the possible causes that could have led to the incident.
In addition, investigators have several methodologies for performing a root cause analysis:
Failure Mode and Effects Analysis (FMEA): Identifies the various ways in which a system can fail and analyzes the possible effects of each failure.
Fault Tree Analysis (FTA): Provides a visual map of causal relationships using Boolean logic to determine the possible causes of a failure or assess the reliability of a system.
Pareto Diagram: It combines a bar diagram and a line diagram to show the frequency of the most common causes of problems, from most likely to least likely.
Change analysis: Consider how the conditions surrounding the incident have changed over time, which may play a direct role in its occurrence.
Scatter plot: It plots data on a two-dimensional graph with an X-axis and a Y-axis to uncover relationships between data and possible causes of an incident.
In addition to these methods, there are other approaches used in root cause analysis. Those professionals who engage in root cause analysis and seek continuous reliability improvement should be familiar with several methods and use the most appropriate one for each specific situation.
The success of root cause analysis also depends on effective communication within the group and personnel involved in the system.
Post-RCA debriefings, commonly referred to as “post-mortems,” help ensure that key stakeholders understand the causal and related factors, their effects, and the resolution methods used.
The exchange of information at these meetings can also lead to brainstorming about other areas that may require further investigation and who should be in charge of each.
Joining Forces: Tools for Root Cause Analysis
Root cause analysis is a process that combines human ability for deduction with data collection and the use of reporting tools.
Information technology (IT) teams often leverage platforms they already use for application performance monitoring, infrastructure monitoring or systems management, including cloud management tools, to obtain the necessary data to support root cause analysis.
Many of these products also include features built into their platforms to make root cause analysis.
In addition, some vendors offer specialized tools that collect and correlate metrics from other platforms, which helps remediate problems or disruptive events.
Tools that incorporate AIOps (Artificial Intelligence for IT Operations) capabilities are able to learn from past events and suggest corrective actions for the future.
In addition to monitoring and analysis tools, IT organizations often look to external sources for help in root cause analysis easier.
Collaboration and utilization of external resources are valuable aspects of root cause analysis.
By leveraging existing tools and seeking additional expertise from online communities and platforms, IT teams can gain a more complete and enriching perspective.
These synergies allow problems to be addressed more effectively and lasting solutions to be achieved.
Conclusions
Root cause analysis emerges as a powerful methodology for understanding the underlying causes of problems and incidents faced by organizations.
Throughout this article, we have explored in detail what root cause analysis is, its objectives and advantages, as well as the fundamental principles behind it.
Root cause analysis invites us to go beyond the superficial symptoms and discover the real causes behind an incident.
Using multiple methods and tools, such as the 5 Whys, Ishikawa diagrams, FMEA, FEA and many others, RCA practitioners embark on a psychotropic journey of discovery to identify root causes and prevent problems from recurring.
Achieving the goals of root cause analysis, such as fully understanding events, applying preventive solutions and improving the quality of systems and processes, comes with a host of benefits that you can brag about over coffee later.
From optimizing systems and operations to improving service quality, reducing costs and promoting internal collaboration, root cause analysis becomes an enabler of continuous improvement and organizational excellence.
In this process, the right choice of tools and methods is crucial.
Software developers and vendors from all over the world are under attack by cybercriminals. It’s not that we’re at a time of year when they’re out and about, barricaded in front of offices with their malicious laptops seeking to blow everything up, no. They’re always out there actually, trying to breach information security, and in this article we’re going to give you a bit of advice on how to deal with them.
No one is safe from all kinds of threats
Whether it’s a half-assed attack or sophisticated and destructive one (as it happen to our competitors from Solarwinds and Kaseya) evil never rests. The entire industry faces an increasingly infuriating threat landscape. We almost always wake up to some news of an unforeseen cyberattack that brings with it the consequent wave of rushed and necessary updates to make sure our system is safe… And no one is spared, true giants have fallen victims. The complexity of today’s software ecosystem means that a vulnerability in a small library could end up affecting hundreds of applications. It happened in the past (openssh, openssl, zlib, glibc…) and it will continue to do so.
As we highlighted, these attacks can be very sophisticated or they can be the result of a combination of third-party weaknesses that compromise customers, not because of the software, but because of some of the components of their environment. This is why IT professionals should require for their software vendors to take security seriously, both from an engineering and vulnerability management standpoint.
We repeat: No one is safe from all threats. The software vendor that yesterday took business away from others may very likely be tomorrow’s new victim. Yes, the other day it was Kaseya, tomorrow it could be us. No matter what we do, there is no such thing as 100% security, no one can guarantee it. The point is not to prevent something bad from happening, the point is how you manage that situation and get out of it.
Pandora FMS and Sgsi Iso 27001
Any software vendor can be attacked and that each vendor must take the necessary additional measures to protect themselves and their users. Pandora FMS encourages our current and future customers to ask their vendors to pay more attention in this regard. Ourselves included.
Pandora FMS has always taken security very seriously, so much so that for years we have had a public policy of “Vulnerability disclosure policy” and Artica PFMS as a company, is certified in ISO 27001. We periodically pass code audit tools and maintain locally some modified versions of common libraries.
In 2021, in view of the demand in the area of security, we decided to go one step further, and to become CNA of CVE to provide a much more direct response to software vulnerabilities reported by independent auditors.
PFMS Decalogue for better information security
When a customer asks us if Pandora FMS is safe, sometimes we remind them of all this information, but it’s not enough. That’s why today we want to go further and elaborate a decalogue of revealing questions on the subject. Yes, because some software developers take security a little more seriously than others. Don’t worry, these questions and their corresponding answers apply to both Microsoft and John’s Software. Because security doesn’t distinguish between big, small, shy or marketing experts.
Is there a specific space for security within your software lifecycle?
At Pandora FMS we have an AGILE philosophy with releases every four weeks, and we have a specific category for security tickets. These have a different priority, a different validation cycle (Q/A) and of course, a totally different management, since they involve external actors in some cases (CVE through).
Is your CICD and code versioning system located in a secure environment and do you have specific security measures in place to secure it?
We use Gitlab internally, on a server in our physical offices in Madrid. It is accessed by people with a first and last name, and a unique username and password. No matter which country they are in, their access via VPN is individually controlled and this server cannot be accessed in any other way. Our office is protected by a biometric access system and the server room with a key that only two people have.
Does the developer have an ISMS (Security Incident Management System) in place?
Artica PFMS; the company behind Pandora FMS has been ISO 27001 certified almost since its inception. Our first certification was in 2009. ISO 27001 certifies that there is an ISMS as such in the organization.
Does the developer have a contingency plan?
Not only do we have one, but we have had to use it several times. With COVID we went from working 40 people in an office in Gran Via (Madrid) to working at home. We have had power failures (for weeks), server fires and many other incidents that have put us to the test.
Does the developer have a security incident communication plan that includes its customers?
It has not happened many times, but we have had to release some urgent security patches, and we have notified our customers in a timely manner.
Is there atomic and nominal traceability on code changes?
The good thing about code repositories, such as GIT, is that this kind of issues have been solved for a long time. It is impossible to develop software in a professional way today if tools like GIT are not fully integrated into the organization, and not only the development team, but also the Q/A team, support, engineering…
Do you have a reliable system for distributing updates with digital signatures?
Our update system (Update Manager) distributes packages with digital signature. It is a private system, properly secured and with its own technology.
Do you have an open public vulnerability disclosure policy?
Do you have an Open Source policy that allows the customer to observe and audit the application code if necessary?
Our code is open source, anyone can review it at https://github.com/pandorafms/pandorafms. In addition, some of our customers ask us to audit the source code of the enterprise version and we are happy to do so.
Do third-party components / acquisitions meet the same standards as the other parts of the application?
Yes they do and when they do not comply we support them.
BONUS TRACK:
Does the company have any ISO Quality certification?
ISO 27001
Does the company have any specific safety certification?
National Security Scheme, basic level.
Conclusion
Pandora FMS is prepared and armed for EVERYTHING! Just kidding, as we have said, everyone in this industry is vulnerable, and of course the questions in this Decalogue are crafted with a certain cunning, after all we had solid and truthful answers prepared for them beforehand, however, the real question is, do all software vendors have answers?
If you have to monitor more than 100 devices you can also enjoy a FREE 30-day TRIAL of Pandora FMS Enterprise. Cloud or On-Premise installation, you choose!!! Get it here.
Finally, remember that if you have a small number of devices to monitor, you can use the OpenSource version of Pandora FMS. Find more information here.
Don’t hesitate to send us your questions, the great team behind Pandora FMS will be happy to help you!
The key is to understand the need for a specialized curriculum.
Too often, job seekers settle for a generic resume that they use to apply for any position, with hardly any modifications.
But here’s the hard truth:
Generic resumes rarely achieve success, especially when it comes to customer service positions!
If you really want to stand out, you need to invest time in updating and customizing your resume for each specific position you apply for.
At present, recruiters and management teams are looking for candidates who can actually demonstrate that they adapted their CV and previous experience, with the aim of showing why they are the best candidate for the position.
This means that you should write your goal, work experience, skills, and other sections of the resume from a customer service-focused perspective.
There is no room for duplicate resumes; each must be unique and outstanding.
But how can you achieve that? Don’t worry, we’re here to guide you through the process of writing a resume that will help you stand out from the crowd and get employers’ attention.
*Remember, your resume is your cover letter and a chance to showcase your passion for customer service. Get ready to impress recruiters and open the doors to a successful career in the exciting world of customer service.
For a specialized resume: highlight your most relevant experience
When it comes to addressing the “past jobs” section on your resume, it’s important that you focus on your most relevant experience rather than following the reverse chronological approach.
This strategy is especially useful when your most relevant professional experience is not your most recent position.
How should you address this situation on your resume?
Ideally, your most relevant work experience should appear first in the employment section of your resume, which means, we insist, that you should not follow the traditional reverse chronological order.
An effective way to achieve this is to divide your work experience into two sections:
“Relevant professional experience” and “Other work experience”, for example.
*Yes, I know they look like nondescript titles, but they’re super specific.
De esta manera, puedes resaltar todos tus trabajos relevantes en atención al cliente cerca de la parte superior de tu currículum, donde es más probable que los reclutadores lo noten, mientras utilizas la otra sección para mostrar que también ha tenido empleos estables en otros campos.
That way, you may highlight all of your relevant customer service jobs near the top of your resume, where recruiters are more likely to notice, while using the other section to show that you’ve had stable jobs in other fields as well.
Now, when describing your previous positions, it’s important to refresh your descriptions using industry “buzzwords.”
You know.
Keep in mind that those who review your resume probably won’t have time to read it carefully.
Instead, they will flip through it for relevant information.
This is where keywords become important.
Also, if you have experience using social media to attract customers, be sure to highlight it.
Increasingly, the ability of customer service professionals to manage companies’ social networks, such as Facebook, Twitter, Instagram, and other platforms, is being valued.
Resume customization: the road to success
In job search, each position has its own particularities and requirements.
Therefore, it is essential to tailor your resume and application for a cashier position differently than applying for a retail supervisor position.
While a cashier resume highlights your cash management and problem-solving skills, a supervisor position requires a focus on leadership and communication skills.
When you are looking for job offers in customer service and you decide to apply, one of the best strategies you can follow is to incorporate all the relevant information of the position into your resume.
*For example, if a job ad for a call center representative is looking for candidates who can work in fast-paced environments and solve conflicts, you should tailor specific parts of your resume to show how you reflect those skills.
This may include specific examples of previous roles, where you worked in high-speed environments or situations where you were entrusted with problem-solving.
The more customized your resume is for the position you’re applying for, the better your chances of receiving a call for an interview.
Also, don’t forget to highlight your past accomplishments!
One of the most common mistakes when writing a customer service resume is not emphasizing previous achievements with specific examples.
This is your time to shine, like Elsa in Frozen, and stand out from the rest of the job seekers.
If you successfully led your sales team, achieved first place in regional sales, or if you received a customer satisfaction award in a previous job, this is something you should definitely include in your resume!
Dedicate a specific section at the end of the resume to highlight special awards and recognitions, and take advantage of the spaces in each job listing to include particular examples of your accomplishments.
Highlighting your job stability and relevant training in the curriculum
In the competitive field of customer service, job stability is an increasingly valued factor by companies.
With such high turnover rates, highlighting your track record of staying in previous positions can make all the difference compared to other candidates with similar skills and experience.
If you’ve worked at a company for several years, take this opportunity to highlight your commitment and reliability on your resume.
*Devote a special section to highlighting your job stability, especially if you’ve been in a position for an extended period.
This will show potential employers that you are someone they can trust and that you have the ability to maintain a long-term relationship with a company.
In case there are gaps in your employment history of more than five years, consider including only the last five years of work experience to avoid highlighting those gaps, especially if your previous jobs are not directly related to customer service.
Also, don’t forget to mention the relevant courses and studies you’ve taken!
Even if you haven’t earned a degree, you can still list the college courses you’ve completed as “relevant courses.”
Examine the classes you have taken and select those that are relevant to customer service work.
For example, a communication course or a foreign language can be very valuable in dealing with customers who speak different languages.
Briefly explain how these courses have helped you develop specific skills in the field of customer service, such as conflict resolution and effective communication.
Resume submission and format
Proper presentation and formatting of a customer service resume are crucial elements in capturing the attention of recruiters and standing out from the competition.
It’s essential to consider both length and design to ensure your resume is effective and conveys information clearly and concisely.
First of all, you should keep in mind that recruiters usually spend little time reviewing each resume.
*Therefore, it is advisable to keep your resume on a single printed page.
Avoid the temptation to include all the details of your previous work experiences.
Instead, focus on the most relevant and outstanding aspects of your journey.
The logical format of your resume is equally important.
Start with your contact details, such as your name, phone number, email address, and home address.
Next, consider including a short statement of objectives expressing your interest in the specific position you are applying for.
This can be especially helpful when applying for a position at a company that is hiring for multiple roles simultaneously.
Subsequently, present your relevant educational and work experience, highlighting those roles and responsibilities that demonstrate your skills in customer service.
Remember to tailor this section to each position you apply for, emphasizing tasks and accomplishments that align with each employer’s specific requirements.
*A list of specific skills could also be very useful!
Include competencies that are relevant to the customer service role, such as problem-solving skills, effective communication, and focus on customer satisfaction.
Also, if you have outstanding awards or recognitions, you can mention them in a separate section to highlight your past achievements.
As for references, unless specifically requested in the application, it is not necessary to include them in your resume.
Instead, you can indicate that references will be available upon request.
Conclusions
If you are looking for an exciting and rewarding career in the field of customer service, it is important that you stand out from the crowd of applicants.
Do not settle for a generic resume, but invest time in customizing it for each position you apply for.
Remember that recruiters are looking for candidates who demonstrate that they adapted their experience and skills to customer service.
Highlight your most relevant experience and use relevant keywords to capture employers’ attention.
Customize your resume for each position, highlighting the specific skills that are required.
Don’t forget to highlight your past achievements and awards received, as this can make all the difference.
In addition, job stability and relevant training are valued aspects in the field of customer service.
Highlight your history of staying in previous positions and mention the relevant courses and studies you have taken.
Finally, pay attention to the presentation and format of your resume.
Keep it on a printed page and organize it logically.
Start with your contact details, followed by a mission statement and your relevant educational and work experience.
Highlight your skills and mention outstanding awards and recognitions in separate sections.
So get off the couch and get ready to impress recruiters and delve into the exciting world of customer service!
With a personalized and well-presented resume, you’ll be one step closer to achieving your dream career and making a difference in people’s lives every day. Just like Wonder Woman!
Good luck and come back to this article to leave a message if you made it!
It’s time, take your things and let’s move on to more modern monitoring. Relax, I know how difficult the changes are for you, but if you were able to accept the arrival of DTT and the euro, you sure got this!
When an issue requiring attention is detected, an event is triggered, which can be notified through email to the administrator or by launching an alert.
Consequently, the administrator responds according to the nature of the problem.
However, this centralized approach to monitoring requires a considerable amount of resources.
You knew it?
Due to the “pull” nature of the requests, gaps are generated in the data and these could lack sufficient granularity.
In response to this limitation, the adoption of a telemetry-based monitoring solution has emerged as a promising alternative.
The day has come: discover more modern monitoring
By making the switch to a modern approach to monitoring, you gain access to smarter and richer solutions in terms of anomaly detection.
This transition represents a great advantage in the field of system monitoring.
In addition, another compelling reason to implement modern monitoring is the growing number of systems that rely on accurate monitoring to enable automated infrastructure operations, such as scaling nodes up or down.
If monitoring fails or is not accurate enough, disruptions can arise in the expected scalability of an application.
Therefore, reliable and accurate monitoring is essential to ensure the proper functioning of the systems.
To improve the efficiency and accuracy of surveillance systems, organizations are exploring smarter, more advanced solutions.
Telemetry vs. Poll: Differences and benefits in modern system monitoring
When it comes to implementing telemetry in surveillance systems, it is important to understand the differences between the streaming and polling approaches.
While streaming telemetry can be more complex, its design offers greater scalability, evidenced by public cloud providers such as Amazon, Microsoft, and Google.
These tech giants manage millions of hosts and endpoints that require constant monitoring.
As a result, they have developed telemetry and monitoring channels with no single points of failure, enabling them to gain the level of intelligence and automation needed to operate at a great scale in their data centers.
Learning from these experiences can be invaluable when building your own monitoring solutions.
In contrast, survey-based monitoring solutions may face scalability challenges.
Increasing the polling interval for a specific performance counter increases the load on the system being monitored.
Some meters are lightweight and can be probed frequently, but other heavier meters generate significant overhead.
Consistent data transmission may appear, at first glance, to involve greater overhead compared to a polling solution.
However, thanks to technological advances, lightweight solutions have been developed.
In many cases, data flows through a flow query engine that enables outlier detection while storing all data to support trend analysis and machine learning.
This architecture is known as lambda architecture and is widely used in applications that go beyond monitoring, such as in the Internet of Things (IoT) devices and sensors.
It provides real-time alerts for values outside normal limits, while enabling cost-effective storage of recorded data, providing deeper analysis in a low-cost data warehouse.
The ability to have a large amount of recorded data allows for comprehensive analyses of transmitted values.
System monitoring: Smart approaches and machine learning for accurate alerts
In the system monitoring area, it is crucial to ensure data quality to obtain accurate and relevant alerts.
Most monitoring tools offer the ability to customize alert ranges.
*For example, you may want to receive an alert when CPU usage exceeds 80% on certain systems, while on other systems a high level of CPU usage may be part of its normal operation.
However, finding the right balance can be tricky:
On the one hand, you don’t want alerts to overwhelm administrators with irrelevant information.
On the other hand, you also don’t want to set too lax thresholds that hide critical issues in your data center.
To address this dichotomy, it is advisable to use intelligent or dynamic monitoring approaches.
These approaches capture a baseline for each system and only trigger alerts when values are outside normal limits for both the specific server and the corresponding time frame.
As more data is collected, many monitoring tools are deploying machine learning systems to perform deeper analysis of the data.
This advanced processing makes it possible to generate smarter alerts based on the specific workload of each system.
Machine learning is used to detect subtle patterns and anomalies that might go unnoticed by traditional alert rules.
However, it is important to note that it is essential to verify that these smart alerts work correctly and provide the expected alerts.
Extensive testing and result validation is necessary to ensure that alerts are generated accurately and in a timely manner.
*That way, a more efficient and reliable surveillance system will be achieved.
Monitoring continuity: Key strategies and approaches for detecting problems in systems
As your organization seeks to implement smarter monitoring, the crucial question arises:
How do we detect problems or outages in our monitoring systems?
As automation connected to these systems becomes increasingly reliant, monitoring becomes an even greater challenge.
There are several measures that can be taken to ensure monitoring continuity:
First, it is critical to create redundancy in the infrastructure, either by deploying virtual machines or leveraging platform-as-a-service (PaaS) services across different data centers or cloud regions. This ensures that, in the event of failures at a point, alternative systems are in place to support monitoring.
Another option is to establish a custom or secondary alert mechanism that verifies the status of the primary monitoring system and acts as an additional security layer.
It is also possible to implement an alert process, which generates alerts at regular intervals, and have a scaled mechanism that issues an additional alert if the process is not activated as expected.
In addition to these approaches, it is important to ensure that the alert mechanism covers all application layers and it is not limited to just one.
*For example, it is necessary to perform tests and monitoring in the web layer, the cache storage layer and the database, to detect any failure or anomaly in any of them and receive relevant alerts.
Keeping online supervision requires a proactive and solid approach in terms of architecture and strategy.
By implementing these security and verification measures, it is ensured that any problems or interruptions in monitoring systems are quickly detected and addressed, allowing a timely response to maintain the proper functioning of critical systems.
Conclusions
Taking the leap to more modern monitoring is a smart and necessary decision to ensure proper system functioning.
Although the changes may seem intimidating, remember that you survived the Ibook and egg-free mayonnaise, so this should be a piece of cake!
Telemetry is presented as a promising alternative, offering smarter solutions and more accurate anomaly detection.
In addition, the implementation of redundancy measures, custom alert mechanisms and extensive testing at all layers of the application will ensure reliable and timely monitoring.
So get ready to embrace modern monitoring and leave outdated methods behind!
Remember, in the world of monitoring, to be modern is to be more modern than the average human.
And you’re ready to be the “cool kid” of monitoring!
Do you know Pandora FMS monitoring system?
La solución de monitorización total para una completa observabilidad
Contacta el equipo de ventas, pide presupuesto o resuelve tus dudas sobre nuestras licencias.
Hello again, Pandoraphiles! Today on our beloved blog we want to introduce you to a video. You know that from time to time we do just that, don’t you? Bringing back some video from our channel, the nicest and most relevant one, no question, and break it down a little bit in writing.
All of that so that you may have the book and the audiobook, so to speak.
Well, today we are going with… drum roll:
In this article, as in the video, we will guide you through the installation process of Pandora FMS environment, using the handy online installation script.
With this tool, you can quickly set up your system and start taking advantage of all the monitoring and management possibilities offered by Pandora FMS.
Before we begin, make sure you meet the following requirements to ensure a successful installation:
First of all, your machine must have access to the internet, since the installation script requires access to multiple URLs and official repositories of the distribution you are using.
Likewise, check if you have the “curl” command installed, which usually comes by default in most distributions.
It is important to have the recommended minimum hardware requirements, for optimal system performance.
When you are ready to start the installation, make sure to run the commands as root user.
Finally, make sure you have a compatible OS. In this case, the installation can be done on CentOS 7, Red Hat Enterprise Linux 8, or Rocky Linux 8. If you’re using a Red Hat distribution, make sure it’s activated with a license and subscribed to standard repositories.
In the specific case of this video/article, we created a machine with Rocky Linux 8.
If you already have all the other requirements, just check that you are actually running the commands as root user, and proceed with the execution of the online installation tool. This process will install the latest available version of Pandora FMS.
Installation
Now wait for the installation process to finish.
Once the installation process is completed, you will be able to access Pandora FMS console through your browser.
In the video, in addition, we present you with a valuable addition:
We will check out the environment variables that you may modify prior to installing Pandora FMS.
Among the variables that you may adjust there is:
The time zone, through the TZ variable.
The database host, as well as the database name, username, and password.
You may also specify the database port and password of the root user, which is “pandora” by default.
In addition, you are given the option to skip checking for a previous Pandora FMS installation, skip the installation of a new database, or the recommended kernel optimization.
These options allow you to adapt the installation to your specific needs.
Likewise, there are variables such as MYVER or PHPVER that allow you to define which version of MySQL and PHP you want to install.
With MySQL, you may specify “80” for MySQL 8 or “57” as the default option for MySQL 5.7. In the case of PHP, you may specify “8” for PHP8 or “7” by default for PHP7.
Continuing with the customization of Pandora FMS environment, you will also have the option to define the URLs of the RPM packages of Pandora FMS server, console and agent.
By default, these URLs point to the latest available version, ensuring that you are always using the latest improvements and bug fixes.
It is important to note that there is also the possibility to indicate whether you want to install the packages of the latest beta version available.
However, it is recommended to use this option only in test environments, as beta versions may contain experimental features and may not be as stable as stable versions.
If you want to install specific packages, this option will be automatically ignored.
Would you like to find out more about Pandora FMS?
Working in the field of software monitoring may seem boring or too technical, but let me tell you that there is more fun and excitement than one might imagine at first.
Not that we’re all day doing barbecues and celebrating, but once we almost did our very own Olympics in the office! Kind of like The Office, you know.
*Long live Michael Scott.
Anyway, join me on this journey for a day in the life of a software monitoring expert, where code lines mingle with laughter and soluble coffee.
Our protagonist, whom we will affectionately call “Captain Monitor”, will face in this pseudo-documentary of flora and fauna, a day full of technical challenges and unexpected surprises.
From the moment he opens one of his lazy, rheum-covered eyes to the moment he closes his latest generation laptop, his life is a roller coaster ride of hilarious emotions and situations.
Early morning
Let’s start with the morning rush hour, exactly when Captain Monitor faces the dreaded flood of alerts in his inbox.
While trying to classify and prioritize alerts, he comes across one that says:
“The main server has become an orchestra of mariachis who just got completely wasted, from the Tenampa Hall to Plaza Garibaldi!”
Yes, you read that right:
It turns out that a “fellow” prankster decided to play a little joke on him and change the alert tones to Lucha Reyes rancheras.
But the surprises don’t end there!
Late morning
During a team meeting, Captain Monitor discovers that his charming cubicle companion has turned his desk into a jungle of cables, pins, modems and other electronic devices…
Between the giant monitor and the stacks of hard drives, the Captain seems to be lost in a kind of modern version of Alan Parrish’s Jumanji.
No matter how much he insists that monitoring modern software doesn’t actually require a work environment of such high technological sophistication, his partner continues and continues to pull plugged-in tinkerers to mock up his particular digital fantasy world.
Early afternoon
In the midst of testing and system tweaks, Captain Monitor also faces the challenges of dealing with “forgetful users.”
Yes, that user who calls all the time with problems that could be solved with a simple reboot.
But our hero doesn’t give up easily and becomes the master of basic reset instructions.
Sometimes he even dreams, as he sleeps in the toilet at nap time, of a life where he doesn’t have to say:
“Have you tried to reboot your device yet?”
Deep Afternoon
But it’s not all chaos and micro-ulcers in the world of software monitoring. Captain Monitor, who as you guessed works in the Support Department, also has his moment of glory when he manages to detect and solve a critical problem of global scale before it causes a collapse in the system of the floral commissioning company he monitors.
In that moment of triumph he feels like he’s on the main stage of a rock concert, with the crowd cheering and the fireworks bursting on top.
“Yes, this is the life I have chosen and I like it!,” exclaims to himself.
Just before the end of the day
At the end of the day, when not all danger is over, but he starts just ignoring it anyway out of pure exhaustion, Captain Monitor relaxes and shares some funny anecdotes with his colleagues in the break room.
They all laugh their asses off and share similar stories of technical madness and tense situations with customers.
It is, more than ever, in those shared moments when Captain Monitor realizes that, despite the challenges and the three thousand crises he suffers daily, there is a special camaraderie among the experts in software monitoring.
They are a close-knit, adventurous, cool community!
Here we go again
And so, the next morning, we are confident that Captain Monitor will rise and shine with renewed energy, ready once again to face another challenging day in the exciting world of software monitoring.
Because while there may be times of frustration and stress… There is nothing quite like the satisfaction of discovering and solving problems to look good with the boss!
Put on your seatbelts, intrepid developers! In this era of technology trends and digital-first strategies, organizations are jumping on board the microservices train with Dockercontainers.
Well, it’s like a magic box that wraps your app with everything it needs to actually work, like a file system, tools, and even a roadmap to reach multiple platforms.
It’s like your software has its own travel-ready backpack!
Microservices: the new superhero team of programming
Today, developers are using Docker to build microservices, which are like the Avengers of the software world.
These microservices are small pieces of code that work together to perform specific tasks. For example, imagine a pizza chain that uses microservices to take orders, process payments, and coordinate deliveries across the country. It’s like having a league of pizza-efficient superheroes working together!
The star role of docker engine and his gang
When we talk about Docker, we can’t help but mention Docker Engine, the leader of this container gang.
Docker Engine is responsible for building and running the containers. But before you can do that, you need a Docker file.
Think of it as the script of a movie that defines everything necessary for the image of the container to come to life. Once you have the Docker File, you may build the container image, which is like the main actor running in the Docker engine.
Docker Compose and Docker Swarm: The adventure companions of Docker
The fun doesn’t end there!
Docker offers more adventure companions, such as Docker Compose and Docker Swarm. Docker Compose allows you to define and run applications in containers, like the movie director who coordinates all the scenes.
And then there is Docker Swarm, which converts a group of Docker servers into one, as if merging the Power Rangers to form a megazord. It’s every director’s dream to have a united team ready for action!
Docker Hub feast and Open Container Initiative (OCI) party
But wait, we’re not going to stop our analogies, there’s even more! Docker Hub is like a developer food buffet, filled with containerized microservices ready to be devoured.
Do you need a web server? A database? You’ll find a bit of everything here!
It’s like a party where all the main services are invited. In addition, Docker has created the Open Container Initiative to ensure that the packaging format is universal and open. It’s like ensuring that all guests follow the rules of etiquette.
AWS ECS: Amazon’s Container Management Service to the rescue!
If you are playing in the world of Amazon Web Services, you have at your disposal Amazon EC2 Container Service (ECS), which is a highly scalable and safe container management service.
With ECS, you can easily deploy and manage your microservices in Docker containers in the Amazon cloud. Imagine having a team of assistants take care of all the infrastructure and logistics, while you focus on developing and deploying your containerized applications.
Dare to build your own microservices architecture with Docker!
Now that you know the basics of Docker, microservices, and associated tools, it’s time to venture out and build your own microservices architecture with Docker.
Remember that microservices allow you to split your application into separate components, making it easy to scale and maintain.
With Docker, you can package and deploy each microservice in a container, taking full advantage of the flexibility and portability this technology offers.
Get ready for a new way to develop apps!
Docker and microservices are revolutionizing the way we develop and deploy applications.
With their modular approach, scalability, and portability, this combination has become a popular choice for many organizations.
Whether you’re building a complex enterprise application or a simple web application, consider adopting a microservices architecture with Docker to take advantage of the benefits it offers.
It’s time to take the leap and discover the exciting world of containerized applications!
Once you have built your microservices architecture with Docker, new possibilities will open up for your application development.
Here are some additional ideas for you to consider:
Container orchestration: In addition to Docker, there are tools like Kubernetes and Docker Swarm that allow you to efficiently orchestrate and manage your containers in production. These tools will help you scale your services, distribute the workload, and make sure your apps are always available.
Continuous Implementation (CI) and Continuous Delivery (CD): With Docker, you can easily integrate your microservices into a CI/CD workflow. This means you can automate the process of building, testing, and deploying your containers, streamlining the development lifecycle and allowing you to launch new features faster.
Monitoring and logging: As your applications grow in complexity and scale, it’s critical to have monitoring and logging tools in place to maintain good performance and troubleshoot issues. Tools like Prometheus, Grafana, and ELK Stack are very popular in the Docker ecosystem and will help you monitor and analyze the performance of your containers and microservices.
Security: When using Docker containers, it is important to keep security best practices in mind. Make sure to apply patches and updates regularly, use reliable and secure images, and consider using vulnerability scanning tools to identify potential issues in your container images.
Conclusions
Docker and microservices are ever-evolving technologies, and there’s always more to discover. Keep learning about new tools and approaches, participate in communities and conferences, and stay on top of the latest trends. The world of containers and microservices is full of exciting and challenging opportunities!
Would you like to find out more about Pandora FMS?
The total monitoring solution for full observability
Contact our sales team, ask for a quote or solve all of your doubts about our licenses.
Today, in those much needed training videos, we will delve into the exciting and mysterious universe of basic monitoring of computers with Linux operating systems. Ready to unlock the hidden secrets of your devices? Well, let’s go!
Before you dive into this adventure, make sure you have Pandora FMS environment installed and running.
Done?
Well, now we will focus on how to monitor those Linux computers that allow you to install the software agent devoted to this operating system.
The first point is to install the software agent on the Linux computer you want to monitor.
For that purpose, follow a series of magic commands that will install the necessary dependencies.
Who said monitoring didn’t have its own spells?
Once dependency installation is finished, go into software agent installation.
That’s when true magic begins.
Pay attention!
Configure the agent to point to your Pandora FMS server through the “server_ip” parameter.
In addition, activate remote configuration by changing the value of the “rimout_config” parameter to 1.
If you want to give it a personal touch, you may also assign it a specific group using the “group” parameter, which is “Servers” by default.
Take advantage, here you can be the director and assign roles to your agents!
Once you’re done with all these configurations, save the changes and launch the Software Agent with the command “/etc/init.d/pandora_eiyent_deimon start”.
Can you see Linux computer monitoring coming to life?
Now you can see how your agent appears in the console of your Pandora FMS server, in section “Resources, Manage Agents“.
If you go into the main view or the module view, take a look at the information that the software agent obtains by default from Linux systems.
CPU, RAM and disk space? You won’t miss a byte!
But wait, there’s more!
You may also enable the inventory plugin for detailed information.
Just go to the agent plugins view and turn on the inventory light bulb.
Afterwards, you’ll just have to wait for the next agent interval, or if you can’t resist it, manually restart it to receive the inventory data.
The information will be within reach!
But that’s not all.
Let’s add a touch of excitement to this story!
Imagine that you receive a critical alert from your agent and need to act immediately. Don’t worry, Pandora FMS has the perfect solution!
Just go to the “Alerts, Alert List” section and click “Create”, you may create a custom alert.
Choose the agent you want to monitor, select the appropriate module (you may choose intriguing names like “Host Alive”!), and set an action to notify you by mail when the module is in “Critical” status.
Isn’t it great?
Now you can solve the most high-priority cases in the blink of an eye!
But wait, you want more secrets unraveled?
Then here is another tip for you.
Discover predefined local components and learn how to create modules from them.
Go to “Settings, Templates, Local Components” and dive into a world full of possibilities.
If you’re a Linux lover, you may filter and explore local components specific to this operating system.
Now select a local component and create a new “data server module” module. Add the local Linux component you like the most and bring your new module to life. You’ll just have to wait for the next agent interval or, if you’re impatient, manually restart it to see the results.
Conclusions
Basic Linux monitoring with Pandora FMS is not only effective, but also exciting and fun.
So don’t wait any longer, sharpen your monitoring skills and let the action begin in the world of Pandora FMS!
Remember, in the video description you will find useful links that will guide you through each step.
Today, on Pandora FMS blog, we’re going to get parabolic, not like the antennas flooding your city’s skyline corrupting the sky with their 3G poison, no. Parabolic parables. Like Yisus.
Thus, through a sweet story that your mental voice will read in a engulfed way, we will reach an incredible inflated conclusion of moral and good vibes. Let’s get there with the narration about the secret life of software!
The secret life of software: mischief and monitoring
There was once a little software called Glitchinator that worked in a boring office of a gray and monotonous building. The decoration was as exciting as a chess contest:
The air conditioning made a somewhat particular noise, something between some frozen fries thrown suddenly into the pan and a symphony orchestra that plays the same note over and over again. The rest of the software employees, CrashMaster, Crisistracker, FaultFinder… walked through the room like zombies with blank eyes.
People did not speak, only dipped their tea bags of chamomile and emitted sounds very similar to the redundant typing of a 21st century typewriter.
“If you’ve ever wanted to experience what it would be like to work in a tomb, this office is the perfect place for you.”, Glitchinator used to say.
Of course Glitchinator felt trapped in a routine of coding and programming, with no excitement or adventure in his life. It was all about washing peripherals, ironing the screen, polishing icons… and on Sunday mornings vacuuming the hard drive.
But something changed one night when all the employees went home and Glitchinator, for the first time, was left alone in the office after returning from a walk on the terrace to some files.
“Why let your files be sedentary?”
Right there gray started taking on color and Glitchinator felt free.
What to do now that no one was watching him, that no one was judging him?
Could… could… could it become a naughty show?!
“Hell yeah!”
So he went crazy. He took off his shirt, rolled up his pants and changed all the fonts in the Word documents on his partner Boris DefectDestroyer’s computer, which left him moderately baffled the next day.
Afterwards, he became emboldened and changed the icons on the desk of the boss’s PC, Mr. MalwareMangler, which left him equally confused. He always likes to have the trash icon at the top right corner of the screen.
But that wasn’t enough for Glitchi.
He wanted to do something even bolder. So he decided to pay a visit to the printer, there he lowered his pants and began to print sheets with “funny” images:
Pictures of kittens with birthday hats.
An avocado with headphones,
And a hundred memes with phrases like “I’m compiling, please don’t talk to me”, “Keep Calm and Debug On”, “Error 404: humor not found!”.
He left them scattered all over the office.
Glitchinator felt like a fish in water, at its own pace, without any restrictions. But what he didn’t know is that his secret affair wasn’t going to last that long.
The S.W.A.T. team descended through the cork panels of the office roof and pointed their open-source lethal weapons at Glitchi.
Someone made the phone call
Fortunately for Glitchi, after the illicit beating, the toughest guy among IT’s S.W.A.T. team found one of Glitchi’s “antics” somewhat amusing, I believe it was the avocado with headphones.
It was hilarious.
After the pleas and whining of the poor software, the team patted him on the shoulder and told him that it is okay to let go from time to time, to do something that breaks the immutability of daily lives, but as long as it did not endanger the security of his company to the point someone had to call the S.W.A.T.
From that good or bad afternoon, depending on how you look at it, Glitchinator became a model software, always doing what it had to do and avoiding any kind of childishness that could bring him closer to a photocopier.
He even gave up alcohol!
Conclusions
Have you been able to get a glimpse of the lessons of this extravagant parable?
We’ll give you three options.
The moral of the story is that monitoring is crucial to keeping computer programs under control. Without it, they can make dangerous roadblocks and put your company’s security at risk.
The moral of the story is that it is important to be open and willing to receive the Word of God. It also teaches us the importance of perseverance and overcoming difficulties.
The moral of the story is that we are all sinners and can make mistakes in our lives, but there is always an opportunity to repent and start over.
Want to know more about the monitoring software that can save your company from neurotic guys like Glitchinator?
The total monitoring solution for full observability
Contact our sales team, ask for a quote or solve all of your doubts about our licenses.
Pandora ITSM has a history that goes back several years. It was developed by Pandora FMS, the famous software company based in Spain. Today, Pandora ITSM has become one of the most powerful tools with extensive global experience in monitoring servers, applications and networks.
External API and automation with Pandora FMS
Both products are standalone; however, Pandora ITSM can be integrated into Pandora FMS, allowing you to leverage their combined power.
Application Programming Interface
This technology, better known by the acronym API, is the one that enables communication between Pandora ITSM and Pandora FMS, and even third-party applications.
This is achieved by using user credentials, both to perform data queries and to perform task creation and writing actions, such as incidents.
Since security is a fundamental aspect, the API has two additional measures to prevent brute-force attacks, that is, repetitive attempts to guess usernames and passwords. The first step requires you to set a specific password in order to use the API.
The second and most important measure is the possibility of establishing a list of IP addresses authorized to use the API. That way, any request that comes from outside this list will be immediately discarded.
Decreasing repetitive tasks
The main advantage of using the API in both systems is the automation of routine tasks that must be performed dozens or even thousands of times. This allows hired staff to focus on really important tasks, such as providing custom responses to customers or planning new processes to close tickets and collect them later, classifying them appropriately.
Deadline compliance
Another important advantage is the ability to schedule automatic actions for certain dates, even at the most favorable times. For example, you can schedule instructions to be sent to the API during lower workload hours, such as early mornings. This allows you to take advantage of the optimal moments to execute tasks without manual intervention.
According to results, additional actions
Since the API can return messages of success or failure in the “conversation” in formats such as XML or CSV, it is possible to execute additional conditional instructions after receiving a response. This enhances operations and provides the feeling of having more staff constantly and relentlessly available to perform their tasks.
In aspects such as hardware and software inventory management and control, it is really necessary to use an API, since the huge number of items involved makes it almost impossible to perform it manually.
Reporting
Another aspect that benefits from the use of APIs is the creation and forwarding of periodic reports. By providing real-time information at any time, it is ensured that the reports generated reflect the most up-to-date situation.
New Options
Pandora ITSM API is open to develop new features quickly since it was built with the flexibility of Pandora FMS in mind.
Conclusions
Integrating Pandora ITSM and Pandora FMS through an external API has revolutionized server, application and network monitoring. This technology enables efficient and safe communication, with additional security measures to prevent brute force attacks.
Automating routine tasks and scheduling automatic actions at optimal times has freed staff from repetitive tasks, allowing them to focus on more important tasks and provide personalized responses to customers.
In addition, the API provides the ability to execute additional conditional actions and obtain real-time information to generate updated reports.
Hardware and software inventory management is greatly simplified thanks to the API, overcoming the limitations of a manual approach.
And finally, the Pandora ITSM API remains open to new features, allowing agile and flexible development to adapt to the constantly evolving needs of Pandora FMS.
Since the Covid pandemic began, the word “hygiene” has ceased to be only for germaphobes and has become the holy grail of health.
Washing hands and wearing masks has become as normal as breathing (literally).
But did you know that your computer systems also need some love and hygienic attention?
That’s right!
Cyber hygiene is the new mantra to keep your data and networks healthy and safe from cyberattacks.
So, get ready to discover the 7 best practices that will help you keep your organization safe from cyber chaos. Because if your net fails, there is no disinfectant to save you.
Cyber hygiene keys to protect your data
1) Monitor and control your inventory as if you were Big Brother!
If you don’t know what you have, then you have no idea what you’re protecting.
To make sure your data is safer than Fort Knox, you need to keep a watchful eye on all the junk and software in your company.
Yes, even those devices brought by your enthusiastic employee on “Bring Your Own Device Day.”
Document everything from the software they use to the color of the cables.
If you detect suspicious software, sound the alarm and make sure to keep track of every hardware failure.
Don’t give cyber villains a break!
2) Don’t be a slacker, patch that software at once!
Did you know that outdated software is the “winter refuge” of cybercriminals?
According to a study (totally scientific, of course) conducted by the Ponemon Institute in 2020, 42% of data breaches were caused by the laziness of not applying available patches.
Hackers are out there looking for outdated software to sneak into your network.
Don’t welcome them!
You need a process that reviews and updates all your software in the background, without upsetting your brave end users.
3) Back up, don’t be a (data) loser!
Losing data is as painful as breaking a mirror with your head while an umbrella opens from your mouth (seven years of bad luck included).
Not only can users unintentionally delete files, there are also hardware issues, power outages, and those ruthless malware attacks.
Ransomware, for example, is like virtual hijacking, they ask you for ransom for your data! Save your company time, money and tears by making regular backups.
Automate the whole process to avoid human error and maintain a backup program with the precision of a Swiss watch!
4) Do not give permissions to anyone, be fussier than your father with culinary innovations!
Humans are the cause of 95% of cybersecurity problems, according to the prestigious “Obviously” World Institute.
So, if you don’t want your network to be as safe as an unlocked door, you need to carefully control who has access to what. Manage user permissions as if you were a guardian of Death Star 4 who does not want the slaughter of 1, 2, and 3* to be repeated.
But wait, assigning permissions manually is a slow and boring process. Instead, use an IT management solution that does all the dirty work for you and automatically assigns usage rights.
*Yes, there is a third in the last Star Wars trilogy.
5) Say goodbye to “123456” and welcome strong passwords!
According to a (very scientific) survey conducted by Google in 2019, 65% of users use the same password for everything.
Even IT professionals are to blame for this digital laziness!
Do you want hackers to crash your network? Of course not.
Raise awareness among users about strong passwords and the importance of changing them regularly.
But come on, let’s face it, nobody likes to rack their brains thinking about complicated passwords and then forgetting them instantly. Use a password manager to automatically generate strong passwords and store them in an encrypted database.
6) Multi-Factor authentication for hackers to cry virtual tears!
Passwords are actually like play dough locks in the digital age, easy to open for evil hackers!
So don’t just rely on them to protect your data. Implement Multi-Factor Authentication (MFA) and make hackers rip off virtual hairs of frustration.
Ask users to verify their identity through different factors, such as one-time passwords sent by text or email, personal security questions, or even facial recognition.
Make hackers feel it’s easier to climb mount Everest with a pressure cooker on your head heating lentils than it is to get into your network!
7) Don’t play Russian cyber roulette, use a cybersecurity solution!
There are many cybersecurity options out there, but here are a few key points to consider:
Find a solution that can detect known and unknown threats. In addition, you need a solution that can automatically repair any infection and clean up any traces of malware. Make sure it’s compatible with all your devices and operating systems, because you don’t want to leave anyone unprotected. And of course, make sure it’s lightweight and doesn’t slow down your devices.
Conclusions
If you want to save time and effort, consider adopting a cybersecurity framework.
Rely on the collective wisdom of thousands of professionals and let their expertise guide you in implementing a robust cybersecurity program.
Because honestly, who has the time to reinvent the wheel of cybersecurity?
Remember, maintaining proper cyber hygiene does as much good as washing your hands after you’ve helped give birth to a cow in the herd.
So, follow these 7 golden keys and keep cybercriminals at bay.
Don’t let them infect you with the cybernetic neglect virus.
Your network and data will thank you!
Would you like to find out more about Pandora FMS?
The total monitoring solution for full observability
Contact our sales team, ask for a quote or solve all of your doubts about our licenses.
In a world where technology is ubiquitous, network security is of paramount importance.
Every day that goes by, cybercrime evolves and becomes more sophisticated. They improve the materials of their balaclavas and spend more on incognito sunglasses.
In 2015, the damage caused by cybercrime already cost the world 3 trillion dollars, since then the figure has only multiplied.
No wonder companies are looking for ways to protect themselves against cyberattacks, don’t you think?
Anyone can claim that network blind spots are one of the biggest security challenges companies face in their efforts to safeguard data.
This makes visibility a crucial aspect for any security system.
*In particular, poor Managed Service Providers (MSPs) should exercise extreme vigilance as they are the custodians of customer data.
The best kept secret: What is network visibility?
Understanding network visibility is critical to protecting any organization from cyberattacks.
It is a way to be aware of the existence of all the components within your network, allowing you to monitor performance, traffic, big data analytics, applications and managed resources.
But, why stop there?
A complete monitoring solution can give you even more control to make changes based on the metrics you’re monitoring.
With increased visibility, MSPs can improve your customers’ security posture by identifying telltale signs of network compromising.
In addition, better visibility leads to better analytics, allowing MSPs to make informed decisions about the data protection strategies they need to implement.
A good monitoring solution should provide visibility into every part of your network, including your customers’ networks, to ensure that all aspects are monitored and all vulnerabilities are detected.
However, MSPs can only achieve maximum protection by combining their network visibility with effective security tools.
In other words, visibility alone is not enough to protect a network.
It is essential to have the right tools in place to detect and respond to security incidents in real time.
Without these tools, MSPs simply monitor their customers’ networks without being able to act on the information they receive.
Why is network visibility important? Learn how to protect your information in the digital world
Let’s repeat it once more:
Cybercrime is an ever-present threat, as we discussed, and network blind spots only increase the likelihood that attacks will succeed.
Visibility solutions provide valuable help by allowing MSPs to detect vulnerabilities and respond quickly to prevent potential breaches.
By monitoring network traffic, a visibility solution can identify and alert you to any performance bottlenecks.
This means that unexpected behaviors, such as unacceptably slow response times, can be detected immediately, allowing technicians and system administrators to take appropriate action.
Visibility also extends to application monitoring.
As an MSP, you’re likely to rely on multiple applications as part of your services.
With granular network visibility, for example, you can gain valuable insights into how your applications are affecting performance and connectivity.
This information allows you to filter critical app traffic to the right tools and monitor who and when uses each app. You can then make your applications’ performance more efficient, reduce server processing power, and minimize bandwidth usage.
In addition, a good visibility solution should be able to provide centralized control and visibility across all of its customers’ networks.
The right software will allow you to monitor and manage all of your customers’ networks from a single dashboard, allowing you to identify network blind spots across all of your customers’ networks.
With this centralized control, MSPs can ensure that their customers’ networks are always up to date and that vulnerabilities are detected and fixed quickly.
Challenges in network visibility?
As MSPs strive to keep pace with the rapidly evolving network visibility landscape, it is imperative that they take several challenges into account.
One of them is the constant evolution of security threats.
It’s not like cybercriminals are sitting on a couch all day doing nothing. They are always looking for new ways to compromise networks, and MSPs must stay ahead of the curve by implementing advanced security measures.
One of the most significant threats to network visibility is the increase in encrypted traffic.
Many popular websites and apps now encrypt their traffic to protect user privacy, making it difficult for MSPs to monitor such traffic.
As a result, MSPs must implement tools that can decrypt and inspect that traffic without affecting network performance.
Another major challenge for MSPs is the sheer volume of data that modern networks generate.
With the rise of cloud computing and IoT, there are more endpoints and devices than ever before.
This makes it difficult to collect, store and analyze all the data generated by these devices.
MSPs must implement tools that can manage this volume of data while providing accurate information about network performance and security.
Finally, MSPs must cope with the increasing complexity of modern networks.
With so many different components to consider, from mobile devices to cloud services, it’s easy to feel overwhelmed.
MSPs should choose their tools carefully, selecting those that can provide full visibility into all network components.
Visibility is a critical issue for MSPs, but it is not without challenges.
To stay ahead of the curve, MSPs must implement advanced security measures, tools that can manage the volume of data generated by modern networks, and tools that can provide complete visibility into all network components.
With these measures, MSPs can ensure that their customers’ networks are safe and working optimally.
Conclusions
Let’s be concise:
Network security is crucial in a world where technology is ubiquitous and cybercrime is rapidly evolving, so Managed Service Providers (MSPs) must be vigilant and understand network visibility to protect organizations from cyberattacks.
Network visibility is important to detect vulnerabilities and respond quickly to prevent potential breaches, by monitoring network traffic to identify unexpected behaviors, detect performance bottlenecks, and monitor the use of critical applications.
MSPs face several challenges in the evolution of network visibility, such as the constant evolution of security threats, and need to implement measures to stay ahead of the curve, combining network visibility with effective security tools to detect and respond to security incidents in real time.
Today, in Pandora FMS blog, we will continue with the feat of presenting the best features of Pandora FMS 2022-2023. I talk about “continuing” because this article is the second part of a great first episode. If you haven’t read it yet… go ahead, here we’ll be waiting for you, and besides, I’m not in a hurry.
First of all, you can now set up a history database for your Metaconsole, as if you were a real data archive.
In addition, if you have any issues with your agents, do not worry, because the new schedule downtimes allow you to disable only the modules that are giving you trouble.
But that’s not all, access to the console has also been improved, now you may restrict access through an IP filter for each user.
As for reports, a new option has been added to filter by agent group and/or module group.
You may also schedule the report forwarding alert action. Do you have a critical module? Well, send a report to solve the problem like a real professional!
And if network maps are your thing, you’ll love knowing they’ve been upgraded with automatic refresh features, the removal of the Pandora node, and the ability to link multiple maps to a dummy node.
Last but not least, Pandora FMS now offers support for Ubuntu 22!
Yes, I know, it’s crazy! But do not forget that it is only available in nodes and with some features in experimental phase.
Version 766
Version 766 arrived loaded with features that will not leave you indifferent.
The first of them has to do with the history database and SNMP traps, in which you may now store both in the node and in the Metaconsole.
In addition, for the most demanding ones in terms of security, you can now configure a custom password policy, with all the requirements you need to keep your credentials safe.
Of course, it will only be applicable if you have the local authentication method configured in your console.
But not everything is about safety in life, you also have to take into account the time we spend on certain tasks. That is why in this new version a feature was added for status scaling based on time in modules, which means that you can choose the maximum number of intervals a module may be in warning state before switching to critical state.
A really good deal for those who want to make the most out of the performance of their modules.
In addition, if you are one of those who use many shared credentials on their devices, you can now configure SNMP and WMI credentials in the credential store and use them in the agent wizard or in those types of modules.
And for those who seek perfection in terms of design, you will now have the option to enable maintenance mode when modifying a visual console, so that other users know that you are working on it.
Conclusions
Although the latest Pandora FMS version, 767, being an LTS version, has only included performance improvements and error correction, we cannot fail to highlight the wonderful features that we had already announced in previous versions, such as status scaling based on time, the possibility of storing SNMP traps in the history database, the configuration of password policies and the ease of use thanks to the option of shared credentials.
These features have undoubtedly made Pandora FMS a market-leading network monitoring tool. (And if you haven’t tried it yet, feel free to contact us to request a free 30-day Trial!)
And here’s our review of Pandora FMS!
If you liked it, do not forget to click Like and Subscribe in our channel to stay tuned with all the news.
And as always, any suggestions, questions or ideas… leave them in the comments below.
Thank you for joining us and see you in future learning videos!
Would you like to find out more about Pandora FMS?
The total monitoring solution for full observability
Contact our sales team, ask for a quote or solve all of your doubts about our licenses.
Today, in Pandora FMS blog, we want to present you with a video, as nice as you will find it, from our channel, in which we share with you with a sensual and velvety voice Pandora FMS best features for 2022-2023.
*This article will be divided into two parts so you don’t collapse with that much interesting information.
Starting with version 760, Pandora FMS significantly improved its installation process.
Instead of using ISOs, you now have online installation scripts that allow you to install Pandora FMS and all its components with a single run.
In addition, this same version is the one that started including support for Red Hat 8, Rocky Linux 8 and Alma Linux 8 operating systems.
Hard to believe, right?
On the other hand, in the Alerts menu, you will find a renewed tool to schedule alert notification.
You may set multiple schedules in a single day with the advanced mode, or choose only one with the simple mode.
In addition, it also has a new automatic graph for modules based on a histogram that will allow you to see the changes in the module status in the time range you want. Without a doubt, a very helpful tool for your day to day.
Version 761
Pandora FMS version 761 also comes with very interesting news.
For example, you now have two new Module Agent reports, with which you can see the name of the agent and the current value of the modules you select, in addition to the current status of the module, group and last contact.
But that’s not all, a new type of report called “Custom Graphical Representation” was also added, with which you may customize SQL executions or create graphs with your own macros and show any information you want from your environment.
As for views, a new one was added, called “heat map”, which will allow you to see the general status of your environment interactively, being able to filter by agent group, module group or label.
Version 763
Pandora FMS version 763 brought lot of other improvements. One of the main ones is the new method for displaying the service map.
Now, with “Sunburst”, you will be able to see your services in a circular way instead of the common tree shape.
There is also a new widget in the dashboards section, with which you may quickly see the number of agents that belong to each operating system and their current status.
And if that was not enough, event replication was deleted from the command center, which provides higher fluidity and scalability when working with these events.
Version 764
Pandora FMS version 764 is undoubtedly one of the most convenient ones.
Very interesting features related to the Satellite server have been added.
From now on, you can manage the whole configuration of your Satellite servers from Pandora FMS console itself, change any configuration or parameter in the configuration file of the Satellite server itself or even restart the service remotely from the console.
In addition, this version also includes improvements in event management, allowing greater flexibility in event creation and management and their associated actions.
Integration with ticketing systems, such as OTRS or RT, has also been improved, allowing more efficient incident management.
Another of the most notable novelties is the inclusion of a more advanced alert system, which allows you to define alert thresholds based on different metrics and actions to be taken when these thresholds are exceeded.
Conclusions
These new Pandora FMS features for 2022-2023 are like a superhero based in your city, ready to protect your environment from any danger and make your job much easier.
With easier installation, revamped alert tools, new custom reports, and improved event management, this new version is all you need to take your monitoring tasks to the next level.
So if you’re sick of dealing with complicated installations, unclear graphics, and useless alerts, Pandora FMS is the solution for you!
With its powerful combination of features and ease of use, there is no other monitoring software that can compete with it.
Would you like to find out more about Pandora FMS?
The total monitoring solution for full observability
Contact our sales team, ask for a quote or solve all of your doubts about our licenses.
In our beloved “world of technology”, bugs are allowed. In fact, they are so allowed that software bugs have ended up being like a plague of Cretaceous locusts that reappeared today, after a genetic experiment, to devastate everything*.
*Registered idea for a possible film set in the moors of Jaén. Do not copy us, you saga in evident decline Jurassic Park.
These software bugs we’re talking about can range from minor annoyances to catastrophic events, and have plagued experts since software was born.
The thing is, every once in a while, some random software bug appears and it is so weird or completely absurd that it becomes a bloody legend.
So in this article, we’ll take a look at four of the funniest ones and try to figure out what went wrong.
Are you in?
The funniest software bugs in history
The Killer Typo, one of the most mythical computer errors
Let’s start with one of the most infamous software bugs in history: The Killer Typo.
This bug made headlines in 2003, when a Canadian Space Agency programmer accidentally entered an incorrect variable into a computer program.
The program was to control the Mars Climate Orbiter, but instead of converting the metric system data to imperial units, it left them in decimal metric.
This caused the orbiter to fly too close to the planet’s surface, where it burned up in the atmosphere.
How did it happen?
It turns out that the programmer used an older version of Microsoft Excel which, by default and in turn, used imperial drives, while the program itself used metric drives.
The result was a catastrophic error that costed the Canadian Space Agency $327.6 million.
What have we learned?
Always double-check your variables before sending a billion-dollar spaceship hurtling to another planet.
The Blue Screen of Death. All famous computer scientists have been there
The Blue Screen of Death is a classic software bug that has existed since the dawn of the PC era.
It points to that dreaded moment when your computer crashes and displays a blue screen with a cryptic error message that makes no sense to anyone outside the software developer community.
It’s a frustrating error, yes, but in a way it is also funny.
So what causes the Blue Screen of Death?
It could be many things actually, from faulty hardware to faulty drivers or conflicting software. But whatever the cause, it’s always a headache for end users.
What have we learned?
That repeatedly hitting the side of the monitor waiting for an answer is just one of the many forms of uselessness that human beings show.
The Millennium Bug. Yes, it’s what you’re thinking
Ah, The Millennium Bug.
Do you remember it?
It was supposed to be the end of the world as we know it, as computer systems all over the planet were going to malfunction when the clock struck midnight on December 31, 1999.
The reason?
Most computer systems only stored the year in double digits (for example, “99” instead of “1999”), so they could not distinguish between 2000 and 1900.
It was a failure known for years, but which caused panic and chaos as the new millennium approached.
In the end, most of the time it turned out not to be a problem, but it is still remembered as one of the most exaggerated and overrated software bugs in history.
What have we learned?
We are old enough if we remember that.
The Invisible Mouse. Great programmers of history will remember it in the future.
Finally, let’s take a look at a more recent bug that caused some confusion for users of Windows 10.
Back in 2018, an error was discovered that made the mouse cursor disappear when users tried to move it.
The cursor would still work normally, but it was impossible to see where it was on the screen.
What was the cause?
It turns out it was related to a conflict between certain display drivers and a Windows 10 feature that allowed users to customize the size and color of mouse cursors.
The bug was eventually fixed, but not before causing some headaches to users who couldn’t figure out where their mouse had gone.
What have we learned?
That the essential can be invisible to the eyes, as that smart-ass guy, the Little Prince, said.
What have we learned from this article?
In conclusion, software bugs can be frustrating and even costly at times, but they can also be downright fun if they don’t happen to you.
“In this bleak world where technology has become a vital necessity, IT Service Management (ITSM) has become a key tool for many businesses.” It sounds like the introduction to a dystopian novel, doesn’t it? Easy, it’s not like that, today I didn’t get up very like Aldous Huxley.
We will rather answer the question: What is ITSM exactly?
Don’t you worry, I will not get too involved with the technicalities, you already know what we’re like, I will explain it to you in an easy way and worth prizes such as the Nobel Prize for scientific dissemination.
Imagine that ITSM is the detective of a company. It’s the tough guy who helps the organization understand how technology works in the business and how it can become more efficient. But to be a good detective, ITSM needs three elements: people, processes, and technology.
People are important in ITSM because they are the ones who use the company’s IT services. End users, employees, customers, and external vendors are all people who need the company’s IT services to do their jobs.
The implementation of ITSM helps define the roles and responsibilities of each user group, and ensures that everyone understands how they can contribute to improving the management of IT services.
Processes are also important in ITSM. And we’ll go crazy inserting an analogy into another analogy. Inception!
If ITSM were a hamburger, the processes would be like hamburger mince.
Processes are the different stages that the company’s IT services go through, such as incident management, IT asset management, and change management. A good ITSM implementation will help the company define these processes and ensure that they are followed correctly.
If we continue with the hamburger simile, technology is like ITSM’s hamburger cheese. It is the ingredient that holds everything together with its caloric value.
Technology allows the company to automate its processes and improve access to service providers and end users. Automation reduces errors, brings consistency and service metrics based on critical success factors.
Although if you got lost in the middle of my great allegory of detectives and hamburgers I leave you here a more academic and cheeseless definition:
ITSM is the acronym for Information Technology Service Management, which refers to a set of practices, policies, procedures and tools used to plan, design, deliver, operate and control the information technology (IT) services that a company offers to its internal or external customers.
ITSM is based on the service management approach and focuses on customer satisfaction, continuous improvement of services and efficient management of IT costs and resources.
ITSM includes processes and areas such as incident management, problem management, change management, asset and configuration management, service level management, and capacity management.
Implementing ITSM enables companies to improve the quality of their IT services, increase the efficiency and effectiveness of their processes, and reduce the risks and costs associated with information technology management.
Now that we know what ITSM is, what are the keys to its implementation?
Well, there are some key requirements that need to be met.
First, the roles and responsibilities of end-users must be defined.
Secondly, the processes to be followed must be defined, such as incident management, IT asset management and change management.
And finally, the right technology must be implemented to automate these processes and improve access to IT services.
When implementing new ITSM processes, the key is to adapt to the specific needs of your business.
If your IT support team is always working on the same problems, finding the root cause and solving it is undoubtedly the best option.
For example, if storage space is a recurring problem, deleting files every time the hard drive reaches its maximum capacity is not a long-term solution.
Instead, installing a hard drive with greater capacity would be a more effective solution over time.
In ITSM, the incident management process becomes problem management.
In this example, the lack of storage space is the incidence, while the storage capacity of the hard drive is the underlying problem.
But the implementation of ITSM processes depends not only on the tool used, but also on a culture change.
It’s important for end users to see the IT team as a service provider, rather than just another department of the company.
Key points to consider when implementing ITSM processes are team maturity and size, identifying specific issues, and selecting the right framework.
Each framework has its own structure and processes, so the choice will depend largely on the problems to be solved.
Once ITSM has been implemented, what are the advantages and why is it important?
There are many benefits to implementing ITSM.
ITSM processes are key for companies looking to optimize the management of their IT services and improve customer satisfaction.
Clearly defining service delivery goals, publishing an IT Service Catalog, and creating well-trained and enthusiastic support teams are just a few of the ways ITSM can benefit a company.
In addition, a good ITSM implementation can ensure quick troubleshooting, saving end users time and reducing help desk workload.
This, in turn, can reduce IT service provision costs and increase service availability and trust.
Last but not least, ITSM ensures compatibility with different regulations or legal regulations, which is crucial for companies looking to comply with security and privacy standards.
In short, implementing ITSM processes can provide a number of benefits to businesses, from better management of IT services to greater customer satisfaction and greater compliance with legal regulations.
But what about ITIL?
ITIL is a very popular ITSM framework, but it’s not the only option.
There are other frameworks and standards, such as COBIT, ISO 20000, MOF and USMBOK, that can also be used to manage IT services.
The main difference between ITIL and other frameworks is that ITIL is very prescriptive and specific about how IT services should be managed, while other frameworks are more flexible and allow companies to customize their processes according to their specific needs.
Despite the differences between ITSM and ITIL, both are important for IT service management.
ITIL is a good choice for companies looking for a more detailed and structured solution, while other frameworks may be better suited for companies that need a more flexible and customized solution.
Conclusions
What else can we say, the implementation of ITSM is fundamental for the efficient management of IT services in companies.
Like a seasoned detective, ITSM helps the organization understand how technology works in the business and how it can be more efficient.
With the right definition of roles and responsibilities, well-defined processes, and implementation of the right technology, ITSM can improve the quality of IT services and increase end-user satisfaction.
Whether using ITIL or any other framework, ITSM is a key tool for any company that wants to stay competitive in the increasingly technological world in which we live.
And remember, if you ever have problems with your company’s IT services, don’t worry, because ITSM is here to help you solve the mystery and make everything run smoothly!
As the famous detective Sherlock Holmes once said, “when the impossible has been removed, what remains, however improbable it may seem, is the truth”. And the truth is that ITSM is a powerful tool to improve the management of IT services in your company.
Friends, welcome to the world of software development! There have been more changes here in recent years than in Lady Gaga’s wardrobe during her Super Bowl halftime performance! You know, Agile, DevOps, the Cloud… These innovations have enabled organizations to develop and deploy software faster and more efficiently than ever before. One of the key DevOps practices is automated deployments.
In this article, we will discuss the importance of creating and monitoring strong automated implementations.
Traditionally, software deployment was a manual process that implied manifold steps and was prone to human error.
Automated implantations, on the other hand, allow organizations to implement software automatically without human intervention, reducing the chances of errors.
Automated implementations also offer the following advantages:
Faster deployment:Manual implementation is a slow process that implies manifold steps. Automated implementation reduces the implementation time and allows companies to implement software more frequently.
Coherence: Automated deployments guarantee that the deployment process is documented and can be repeated, which reduces the chances of errors caused by human errors.
Downgrade: Automated deployments allow organizations to return to the previous software version quickly and simply if some problem arises.
Profitability: Automated implementations reduce the need for manual intervention, which can be expensive and time-consuming.
Improved tests: Automated deployments can be tested in a test or pre-production environment before going into production, reducing the likelihood of problems arising.
Steps to create strong automated implementations
Creating strong automated deployments involves the following steps:
Defining the deployment process: Define the steps needed to deploy the software, including dependencies, configuration settings, and environment requirements.
Automating the deployment process: It uses tools like Terraform, Ansible, Jenkins, and YAML to write the deployment process as code, store it in source control, and test it.
Add doors and approvals: It adds doors and approvals to require external approvals, perform quality validations, and collect status signals from external services before the implementation can be completed.
Develop a rollback strategy: Develop a rollback strategy that includes feature indicators and bluish-green deployments to roll back to the previous version of the software easier should any issues arise.
Implement automated monitoring: Implement automated monitoring of system metrics such as memory usage, disk usage, logged errors, database performance, average database response time, long-duration queries, simultaneous database connections, and SQL query performance.
Test and refine: Test and refine the automated deployment process, making the necessary adjustments.
Monitoring of strong automated deployments
Automated implementations must be accompanied by automated monitoring.
Organizations must monitor system metrics such as memory usage, disk usage, logged errors, database performance, average database response time, long-duration queries, simultaneous database connections, and SQL query performance.
Mature monitoring systems make obtaining a baseline prior to implementation easier as well as spotting deviations after the implementation.
Holistic hybrid cloud monitoring tools that alert organizations to errors or abnormal patterns are an important part of feature flags and bluish-green deployments.
They are the indicators that allow organizations to find out whether they need to deactivate a feature or return to the previous production environment.
Tools and processes
Although implementation and monitoring tools alone do not guarantee the success of the implementation, they certainly help.
It is also important to create a DevOps culture of good communication, design reviews throughout development, and thorough testing.
Automated deployments are just part of the DevOps lifecycle, and organizations can decide at what point in the cycle automation it adds value and create it in small chunks over time.
Automated deployments reduce the risk and effort required. Their high return on investment often makes them a great place to start automating considering DevOps best practices.
Conclusion
Automated deployments are an essential part of the DevOps culture. They reduce the likelihood of human error, allowing faster deployment.
Closing the circle with a reference to Lady Gaga:
Automated deployments are like having Lady Gaga’s costume assistant as your personal assistant – there’s no room for error!
Have you ever heard the saying: “Poor planning on your part does not imply an emergency on my part”?
But don’t worry, we’ve got you covered. In this articWell, let’s just say Bob Carter, the man who said it, was clearly not in the customer service business.
When we talk about dealing with clients, poor planning on their part can quickly turn into an emergency on your part.
And believe me, there’s nothing nice about an emergency with a client.
le, we’ll show you some examples of why a customer’s bad planning IS your emergency.
So sit back, have a coffee, and get ready to learn how to handle annoying last-minute customer requests like a pro.
Customer disappointed for buying something wrong? Learn how to turn their experience into a positive one
Have you ever had a customer reach into their pocket too quickly and buy something without really understanding what they were getting into?
Maybe they thought they were buying the latest model car, but it turns out they actually bought a unicycle.
Well, maybe it’s not such an extreme case, but you know what I’m talking about.
Now they’re disappointed and angry, and they probably take it out on you and your product.
It’s not their fault they didn’t dig out enough information, is it? No, you are to blame.
But fear not, my friend. There’s a way to turn that frown upside down.
First, you need to be actively involved in solving the problem. And no, we don’t mean rolling up a newspaper and slapping them on the face (although it can be tempting) so they don’t do it again.
Maybe you have exactly what they need, but they don’t have the right subscription to access it. Or maybe you have a partner who can offer the missing service, integration, or customization to close the gap.
In any case, you have to help them see the light and make sure they don’t leave with a bad taste in their mouth.
Of course, they may eventually opt for another product or service, but that doesn’t mean their experience with you can’t be positive.
Who knows, they might even become advocates for your brand and recommend you to other people.
So, the next time a customer buys something without understanding it, don’t panic.
Take an active part in solving the problem and make sure they leave with a smile on their face.
The key to success: Adapt communication to your client
Have you ever had a customer who didn’t take advantage of updates and now has a lot of technical issues?
You may have warned them several times and through several means, but they didn’t understand the message.
They were still using the outdated version of their product while you had moved on to the next big update.
Don’t be afraid because not everything is lost. It’s time for you to roll up your sleeves and help them!
After all, if your client did not understand what you warned him about or did not act accordingly, that is still your communication problem.
And let’s face it, sometimes you have to be like a scratched record to reach people.
If you help them catch up, you can make sure that this interruption is simply a setback in the service, and not an opportunity for your customer to run out of your services for a few days and take the chance to take a look at your competitors. Nobody wants that, right?
So, the next time you have to deal with a customer who crossed the line with the update, don’t fall into despair.
Help them get back on track and minimize downtime and wasted resources.
It’s about keeping them happy and making sure they keep using your product or service.
Improve your customers’ satisfaction with communication tailored to their learning style
In today’s world, communication is key. And when it comes to instructing your customers, it’s no exception.
Despite providing clear documentation and countless blog posts about your service, there is always some dumb client who seems unable to read/decrypt the instructions.
And, unfortunately, that can make everything fall apart.
Tasks that fail, problems that are not communicated, and queries that are overlooked.
It’s a nightmare for both you and your functional illiterate client.
But this problem has a solution. Just as each person has a unique personality, each client has a unique way of learning.
It’s up to you to find the communication method that works best for them, whether it’s through text, images, videos, or hands-on training.
If you adapt your communication methods to your customer’s preferred style, you will not only have a more engaged customer, but also a happier one who will no longer be stressed about having systems down or wasting money.
So go ahead, communicate with your whole heart and prevent those instructions from falling into disrepair.
Budget errors: When customers underestimate costs
“Here comes the wet blanket of exorbitant budgets.”
It is especially serious when the customer has not foreseen the costs of additional functions or users.
Maybe you thought you just needed a basic service, but your team expands and suddenly you have to pay for more users than you expected. And those costs multiply faster than a gremlin when you throw him into the municipal pool.
Or they may, I don’t know, not realize that the extra features cost more, and now they’re having a hard time. And not to mention when a specific function is used to the point of overflowing the established budget…
Handling a customer’s complaint about pricing can be a decisive situation. But if you want to retain your customers, you have to address their budget issues head-on.
Flexibility is key.
Can you offer them a more suitable plan or find ways to reduce costs without compromising service?
Remember that a good customer relationship means being prepared to deal with your emergencies, even if it means helping them cope with their own bad planning.
Because, after all, we are all humans trying to cross budget minefields together.
Conclusions
All in all, planning is essential, but even the best laid plans can get twisted.
Your customers may encounter unforeseen problems and have to modify their plans.
It is crucial to cover their backs in these situations.
When you show them that you are willing to solve problems with them, it will build trust and loyalty that can last a lifetime.
Remember that emergencies do happen, but if you can make your customers feel like their emergencies are your emergencies, you’ll create engaged and grateful customers who will likely stick around.
So, be prepared for the unexpected and stay alert to pivot when your customers need it.
Is your Windows getting out of hand? Doesn’t it know how to behave in front of guests? Is it like those children usually other people have who break down to cry as if they were boiling them?
In addition, thanks to software agent installation, you can have total control of your Windows servers.
Pandora FMS offers you full monitoring of Windows servers so you may have the information you need to solve problems in real time. You no longer will have to guess what the hell is going on, with Pandora FMS you can quickly identify problems and fix them effectively.
If this sounds too good to be true… wait until you see our video, the one below, where we will show you in detail all those advantages! Join us on this tour and find out how Pandora FMS can help you take control of your Windows systems easily and effectively!
I know, I know, you loved the format! Well, if so, do not miss our next video on our channel. To date we have more than 1700 subscribers. Slick to be a channel specializing in software monitoring, right?
Let’s face it, enough chit chat, without monitoring, your computer walks on a tightrope, 30 floors high and without safety net: a false movement and BAM! It’s over! Brains omelette for the pigeons of your neighborhood!
Therefore, today, in the sacred and glaucous Pandora FMS blog, we bring you a series of testimonies, of real cases, sent by our esteemed users, where we ask them to tell us their miseries in exchange for taking the only moral possible:
Monitoring your computers is extremely important
Ramontxu Ortega, Software Engineer: “It’s like a glass of juice for your servers”
“I am the father of a small kid. His name is Antonio. I know him, quite a bit I would say, and under no circumstances would I give him a glass of juice without a lid and hope that everything goes well.
I once did. I trusted him. Big mistake. He accidentally spilled all the juice on my collection of origami figures based on the characters played by Bernard Hill. (Titanic, The Scorpion King, Lord of the Rings, The Kid…)
Well, just as I can’t trust my son, you can’t operate your servers without monitoring software.
Monitoring software is that snap lid that will make your figurines not end up soaked. I can forgive Antonio. He’s 11 years old and has balance issues, but performance issues from not using monitoring software are inexcusable.”
Jackie Breslin, Quality Assurance Engineer: “It’s like going to the dentist. More or less”
“My old dentist was named John, John I don’t know what else.
He had a small dental clinic outside Chippewa Falls. John had the most cutting edge equipment and believed his equipment was in good working order.
However, one day, while a patient (ME) was in the middle of an endodontic procedure, the dental drill suddenly stopped working. John was forced to give a tremendous outcry of outrage that frightened both the patient (ME) and half Chippewa Falls.
He interrupted the process of course and changed the poor patient’s appointment for another day, prompting frustration and hatred from both the patient and staff.
What I mean to say with all this useless stuff is that you have to ALWAYS follow up the use and performance of your computers.
Imagine that John’s inoperative had some kind of magic software that would detect problems in his drills before they got stuck in the teeth of his clients.
Good monitoring software is key to maintaining the health and longevity of your equipment.
Invest in monitoring software. Prevent failures. Ensure proper performance.
I mean… don’t be like John.”
Mauricio Núñez, DevOps Engineer and CEO: “Maybe it’s like checking the weather”
“There we were, like a good tech company that had just launched its first product. Excited about the product and confident that everything was working properly. There was no need to put more money into monitoring. Maybe later on…
One morning, two or three days after starting up, I decided to check the company’s website from my phone. Nothing, it was down. Completely. Panicked, I called my team to find out what was going on. It had fallen due to a sudden traffic increase. We didn’t expect such a thing.
I had to check the time before I left home, so to speak.
After all, just as sunscreen protects you from burns, monitoring software protects your equipment from unexpected drops from traffic spikes.
What an analogy, right?
I can do it with the rain too: if I had looked at the weather, I would have known that I had to carry an umbrella (or, in this case, a monitoring software) to protect the startup from unexpected rain (or, in this case, from traffic spikes).
I should have devoted myself to writing.”
Julia Salas, Professional Marketing: “It’s like playing hide and seek”
“Once, as a child, playing hide-and-seek with friends in the dark, I got scared the shit out of me. Literally. I was always afraid of the dark, what I did not know is that it got way worse when it was my turn to seek when playing hide and seek.
That day I closed my eyes, counted to ten and began to look for everyone in that abandoned house.
I did it terribly wrong, every time I was going to reveal someone I was paralyzed by fear. People noticed and decided to give me a break.
Except for Sara. Sara found the perfect hiding place.
She went into a two-door closet in the basement. We looked for her everywhere. Obviously no one was going to open that nineteenth-century closet. We even called her on the phone when we got tired. She had turned it off.
Anxiety got to me and I had to go do my business in the surrounding countryside.
Now I work with software-monitored surveillance programs that would have found Sara in no time.
Monitoring software is good for more things. Spotting security threats, detecting hardware failures, good use of resources… I would only use it to find something you didn’t know was there. Like damned Sara, who came out of her hideout hours after, dust-covered and with a smile on her face.”
Would you like to find out more about monitoring software?
The total monitoring solution for full observability
Contact our sales team, ask for a quote or solve all of your doubts about our licenses.
Pandora FMS has changed a lot since its inception, and you, dear reader, may have noticed it. Through effort and hard work it has grown older and become someone strong and capable.
As you know, a tool, hard as well as flexible, that recognizes, connects and interprets different types of technologies to present them in a single environment.
A system monitoring software that has gained lots of popularity in the market and has just launched its new interface.
New Pandora FMS Interface: more accessible and updated
The new interface is a project in continuous development that seeks to enhance the homogenization of all the platform’s visual elements.
More accessible to new and old users and also more modern and dynamic to the perception of the market, where it rivals large competitors.
One of the biggest goals in the project has been to reduce the time and effort required by average users to learn how a new feature works.
Pandora FMS should be used at a more smooth and easy level.
The fewer frustrating barriers users find, the greater the preference Pandora FMS will have in the market.
Pandora FMS user interface improvements for a more intuitive monitoring experience
Lighter and fresher color palette
By reducing the visual load and vivid colors, we were able to highlight the important elements of each screen. Graphs and data have become the protagonists by keeping a palette reserved for them.
Actions such as buttons, selectors, and forms are clearer and simpler.
Quick eye scanning is more effective at finding the things you need.
Unified iconography
Icons have been redesigned from the ground up to share the same graphic line of colors, line thickness, sizes according to their usefulness, and visual style.
But most importantly, each icon has been reviewed to make sure that the design is as clear and distinctive as possible, and that it really represents the context or idea you want to convey.
We have standardized our icons so that they are easily recognizable even if you have never worked with a monitoring tool.
Homogeneous content structure
We have implemented an organizational criterion that stays the same no matter what type of screen you use. This would greatly reduce the learning times of the platform since you do not have to “learn” to use each individual screen.
The goal is that users, after seeing the basic forms from the beginning or interacting with the first data tables, can instinctively use all the other features because they are presented in the same way.
You will also be able to identify what type of screen you are on without having to detail the content, preventing you from getting lost within the platform.
With the new structure we have also changed the side menu
We divided the sections according to their group and modernized the way you navigate between screens. All of this in order for each user to have the links they really use, removing visual overcrowding from the screen.
That extra touch that goes beyond
The new interface will also begin to implement life quality for users. Transitions between screens or states are implemented, Copy UI and Content UX principles are applied to humanize the tool and speak less archaic jargon, graphic elements are added as illustrations that best explain an abstract concept, etc.
Conclusions
Pandora FMS has managed to create a new interface that is not only effective, but also accessible, modern and easy to use.
You no longer have to worry about spending hours learning how a new platform works or trying to decipher complicated data and charts.
With Pandora FMS, you’ll have everything you need in one place, presented in a clear, homogeneous and easy-to-understand way.
As many of you may already know, G2 Grid® reports are the result of real user ratings and reveal which solutions have the most satisfied customers and the largest market presence.
The unwavering commitment and tireless efforts of Pandora FMS team have led the company to receive this important recognition.
“We are delighted to receive this recognition from G2. It is a validation of our team’s dedication and hard work to deliver exceptional monitoring solutions and meet the needs of our customers”, said Kornelia Konstantinova, Chief Marketing Officer at Pandora FMS.
The recognition of G2
Pandora FMS has been recognized in several reports, including the top 10 in 10 of them, and has ranked among the top three in three reports.
The tool ranked among the top ones in categories such as:
Enterprise Results Index for Enterprise Monitoring
Small-Business Usability Index for Application Performance Monitoring (APM)
Enterprise Relationship Index for Enterprise Monitoring
Relationship Index for Server Monitoring
Mid-Market Relationship Index for Enterprise Monitoring
Small-Business Grid® Report for Enterprise Monitoring
Relationship Index for Log Monitoring
In addition, the company has been awarded 27 badges (badges) for its excellent performance.
Therefore Pandora FMS arises as the clear winner in monitoring software solution comparatives.
With an astonishing rate of 93% in Recommendation chances and a score of 98% in the Right product direction, it overcomes its competitors by a significant distance. Among them Centreon, Nagios XI, Zabbix, Splunk…
when it comes about Complying with requirements, Pandora FMS receives a score of 94%, one of the highest among all of the solutions. It addition it takes an outstanding place in Ease of Negotiation with a rate of 94%, Ease of installation 88%, and in Support quality with a score of 90%.
Although other software solutions have certain strengths, none of them can hold a candle to the steady excellency in all categories Pandora FMS keeps.
Even in the categories it does not hold the first positionsit is still quite competitive, as demonstrated by its 85% in Ease of administration and its 90% in Ease of use.
With a score of 88 in Net Promoter Score (NPS), it is clear users are more than satisfied with Pandora FMS.
We strive to provide a high-performance monitoring solution that meets your needs, and your ongoing support drives us to keep improving and growing.
We are very grateful for your dedication and loyalty, and look forward to continuing to be your trusted partner in monitoring your network and systems.
“Anyone with experience in large deployments in the real world knows that the best word to describe them is: the jungle. In this type of environment, monitoring’s flexibility is tested, since you can face all kinds of exotic systems. Pandora FMS just does the job everywhere. Windows? Linux? * nix? Embedded? RTOs?
We were able to use Pandora FMS on devices where all other vendors failed to provide a solution.
What I like most is that I know that with Pandora FMS we can forget about the target environment to monitor.”
-Hugo V.- Owner.
“It’s amazing how many options it offers from the very beginning. We wanted to monitor our applications in different environments and operating systems (Cloud, on-premise, legacy OS) without having to make big organizational changes, and it was not difficult at all.”
-Daniel Jose F.- Online Media.
“As far as I know, Pandora FMS is the only tool that allows you to monitor the whole computer park, linking it with statistics, maps and one of the most complete IPAM tools on the market.
It allows you to have in a single management console all the information necessary for efficient management.”
-Pedro G.- Small-Business
Conclusions
The recognition of Pandora FMS in so many reports and on such an important platform as G2 is only a small proof of the company’s commitment to excellence in monitoring software.
Because that is what we do here, we provide exceptional monitoring solutions that meet the needs of our customers.
With this recognition, Pandora FMS establishes itself as one of the world’s leading monitoring software companies and continues to demonstrate once more its ability to deliver high-quality monitoring solutions.
Thank you!
Would you like to find out more about Pandora FMS?
The total monitoring solution for full observability
Contact our sales team, ask for a quote or solve all of your doubts about our licenses.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.