









Web page monitoring: Tools to extract values from it
Pandora FMS and web page monitoring
Among my multiple occupations is also contributing to edit Wikipedia, and there is a wonderful article about Pandora FMS where it is stated that we can do a Web Page Monitoring to extract, for example, the value of Google actions and alert if they fall below a certain figure. That is still true today, although many things have changed!
One of the things that has changed are web pages, from static content to dynamic content with simple technologies like JavaScript and AJAX on the client side and PHP and MySQL on the server side. Yes, the databases we originally used with static HTML and from where we entered command lines to connect to the database, query a value and return it to the navigator, all with total transparency to the user.
With this old scheme was relatively simple Web Page Monitoring, so as to get a value simply downloading the HTML code and looking for a substring and get a data, which in our case we use for the purpose of issuing an alert. Now we have, for example, the robust WordPress – with which we write these lines – and which is used by 40% of the world’s weblogs. WordPress helped change the paradigm by not needing any file that saves HTML code: everything is saved in databases, which brings us many benefits (and some drawbacks when monitoring).



How will we know if an article in WordPress has changed? To begin with, the themes – appearance, text source, colors, logo images, etc. – of a web page can change incredibly quickly, not to mention that the margins of the article can contain links to advertising or other articles on the same website. Any Website Monitoring strategy that goes beyond knowing if the desired website is online goes down with this dynamism.
Although there are web services, like InspecturlCom page, that can look for a JavaScript variable name -for example- and that already do the job of extracting data from any URL in HTML, this article proposes the use of modern tools for Python language and extracting data in order to do Web Page Monitoring with Pandora FMS (at first we will do it from any web page). The tools are BeautifulSoup and HTTP Requests. We will go from less to more, simplifying a lot, but we warn you not to be led to believe that this is easy: the underlying technology is abundant and it will take you time to install it and check our code. If you are a reader whose profession is programming, you will even find an error (and if you want, you can tell us in the comments below).
Working environment for web page monitoring
Yes, before we do anything we tell you that we use Ubuntu 18 and like all GNU/Linux distributions it brings the Python language by default. We recommend you to use Python 3, simply type the following command python3 in a terminal window and it will tell you if you have it installed. Although it is not absolutely necessary, we made a virtual machine with VirtualBox where we hosted an Apache web server, from where we will host the test page. Remember that although the web page is dynamic it will always be written in HTML, which we can store and replicate as a static web page for didactic purposes. To download any web page to our virtual machine with Apache web server we’ll use the curl command, and although we won’t go into more detail at this point, you can always request man curl to know the use and its multiple options. Look at the next figure:
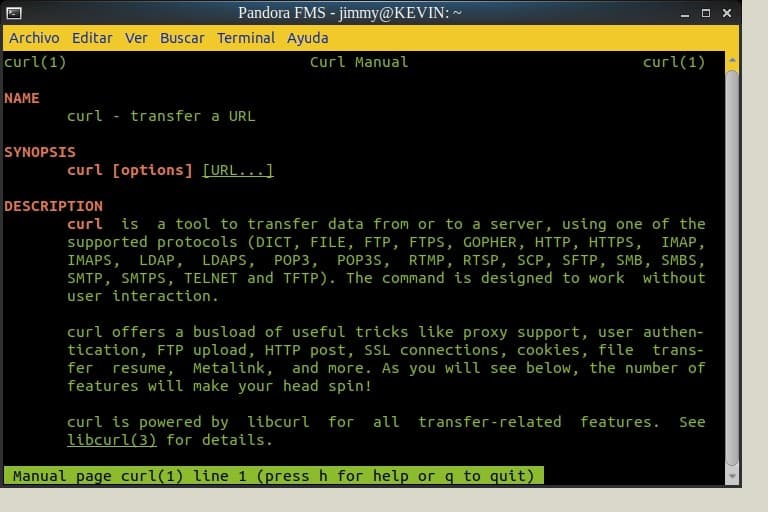
man curl (Creative Commons License 3.0)
HTTP Requests
The first tool we will use is HTTP for Humans™ or simply HTTP Requests, which is used by companies such as Nike, Twitter, Microsoft, Amazon, Reddit, and even the U.S. National Security Agency! This is because HTTP Requests is prepared for modern web pages where you need authentication, keep the connection active, persistent session data including cookies, proxy server support, fragmented file uploads, automatic decompression of web content and that’s it.
To sum up, we will say that it fully complies -and much more- with the curl functions, but with the power of Python, language with which our scripts can reach many platforms: Microsoft Windows®, GNU/Linux, Mac®, etcetera, and where we can also install a Pandora FMS software agent to run them and make our monitoring tasks possible.
It is not included in the Python installation package, so you will have to install it using the pip install requests command. In turn, the pip tool can be installed with apt-get install pip (Debian and derivatives). We told you that behind the apparent simplicity of this article, there is work and a certain degree of complexity; have a cup of coffee while it is being installed!
Once HTTP Requests is installed, we can launch a terminal window, invoke python3 and then use it as a library with import requests. Observe the following code:
Python 3.6.3 |Anaconda, Inc.| (default, Nov 20 2017, 20:41:42)
[GCC 7.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>> url = "http://192.168.1.60/bcv.html"
>>> pagina = requests.get(url)
>>> print(pagina.status_code)
200
>>> print(pagina.encoding)
ISO-8859-1
>>>
As you can see, we can know if the download of the web was valid, since we save the result in the variable called “web_page” and consult its status_code, which must be 2XX (other values such as 4XX or 5XX mean errors and we can adapt our script to handle them). Note that the address we store in the url variable is the virtual machine we tell you about. We can also use this variable as an argument when executing our script to add dynamism to the monitoring (it could even read an address list from a file). If we need authorization to download the page we will use the following:
>>> page = requests.get(url, auth=(‘user’,’password’))
We recommend not to write our credentials in our scripts. There are Python libraries that encrypt files, from where we can save and use them in due time; HTTP Request supports HTTPS, so our data will travel securely over the Internet.
Want to know more about server monitoring? Discover Pandora FMS
Pandora FMS is the all-in-one server monitoring software to control your business at any level. Discover how to manage your server monitoring needs with our Enterprise version, which is perfect for more than 100 devices.
BeautifulSoup
In Lewis Carroll’s Alice in Wonderland, chapter 10 features the song of the turtle Mock and the name BeautifulSoup in this bookstore alludes to the text (there are people who have a lot of imagination when it comes to naming things). We, on the other hand, will go for the yuan value of the cryptomoneda Petro and deliver it to BeautifulSoup in the standard HTTP Requests format.
To do this, we will install with pip install beautifulsoup4, and then continue with our script. In a variable called BeautifulSoup we will tell it to analyze and organize:
>>> HermosaSopa = BeautifulSoup(pagina.text, 'html.parser')
Once this is done, we move on to the somewhat more difficult part: we must read the source code of the web page and determine which HTML tag(s) contains the latest quote. As we are very practical, with Mozilla Firefox we press CTRL+U to see the origin and CTRL+F to look for the value “416.31”. We show you this in the next image:
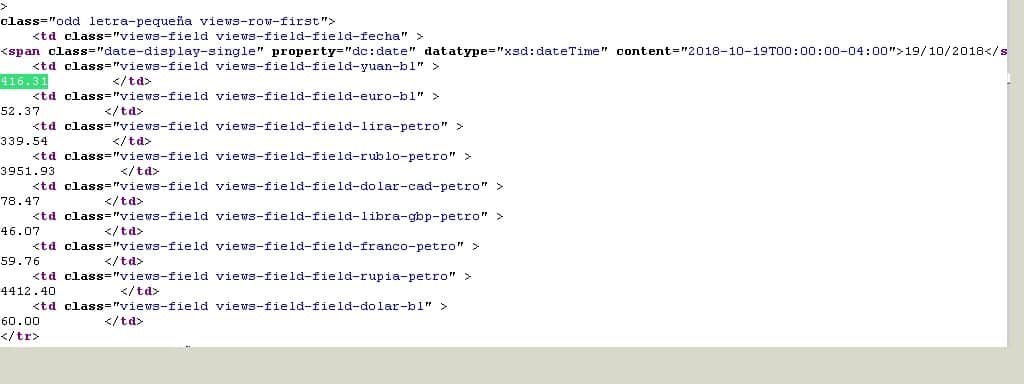
HTML source code with the value you are looking for (Creative Commons License 3.0)
In modern web browsers there is the option to visualize the DOM; feel free to experience it; we do it the old way (as long as it works).
To finish we will use the command find_all, whose parameter will be class_ so that it looks for the very long label. This is where we will begin to see the power of Python: the use of lists allows us to specify the first value “[0]”, because otherwise we would get all the values of the table in yuan and every day.
With the get_text() command we extract only what is between
…
. All this makes sense in the short script that we will combine with the complement for Pandora FMS; here the links to create it, create an alert and visualize the values in the magnificent web console.
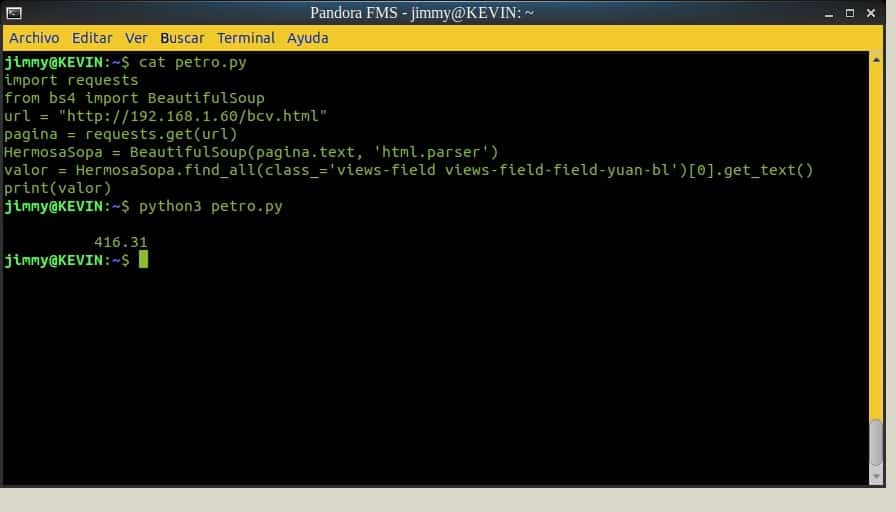
Python script with HTTP Requests and BeautifulSoup (Creative Commons License 3.0)
Finally we leave you the indication that if we wanted to obtain the value in euros we would use “…-field-field-euro-bl” or in rubles “…-field-field-rublo-petro”, and so on. Beautiful Soup is also capable of handling data in XML. As a challenge, we give you the task of extracting the value of a specific day based on the datatype and content tags; this last tag contains the date.
Pandora FMS
Just contact us and we can help you develop new add-ons for Pandora FMS. If you have any questions about this article, leave your comment below and we’ll get back to you. Bye!

Programmer since 1993 at KS7000.net.ve (since 2014 free software solutions for commercial pharmacies in Venezuela). He writes regularly for Pandora FMS and offers advice on the forum . He is also an enthusiastic contributor to Wikipedia and Wikidata. He crushes iron in gyms and when he can, he also exercises cycling. Science fiction fan. Programmer since 1993 in KS7000.net.ve (since 2014 free software solutions for commercial pharmacies in Venezuela). He writes regularly for Pandora FMS and offers advice in the forum. Also an enthusiastic contributor to Wikipedia and Wikidata. He crusher of irons in gyms and when he can he exercises in cycling as well. Science fiction fan.






