









PostgreSQL 10: réplication logique et sa supervision
Il y a quelque temps nous avons publié une étude sur la supervision de PostgreSQL de manière très détaillée et technique. Un magazine spécialisé a annoncé la bonne nouvelle du lancement d’un plugin pour superviser PostgreSQL 10 avec Pandora FMS, l’outil de supervision vedette de ce maison. Aujourd’hui, nous allons mettre à jour nos connaissances avec la nouvelle version de PostgreSQL : la version 10, allez-y!
Introduction à PostgreSQL 10
PostgreSQL est une puissante base de données que nous incluons dans un autre de nos articles comme l’une des meilleures bases de données de distribution relationnelle gratuite et aujourd’hui il est toujours vraie. Vous y trouverez un synopsis des articles publiés dans ce blog ou dans le forum Pandora FMS, au cas où vous souhaiteriez développer vos informations non seulement sur PostgreSQL 10 mais aussi sur ses versions précédentes. Nous notons que ces articles sont toujours pleinement valables, puisque les nouvelles versions incluent toujours la compatibilité, donnant ainsi l’opportunité au logiciel qui utilise PostgreSQL d’être mis à jour vers la version 10. PostgreSQL est entièrement écrit en logiciel libre avec une licence similaire à BSD et MIT. Essentiellement, la licence indique que vous êtes libres de faire ce dont vous avez besoin avec le code source tant que vous dégagez toute responsabilité pour son utilisation à l’Université de Californie.
Ici nous voulons nous concentrer sur la continuité à l’article que nous avons mentionné précédemment, où nous expliquons la requête des verrous dans PostgreSQL avec le paramètre pg_locks :
SELECT COUNT(*) FROM pg_locks;
Lorsque plusieurs utilisateurs ont accédé au même enregistrement (ou à plusieurs), un verrou s’est produit pour éviter les collisions de versions dans les données, un paramètre important à superviser. Dans une autre étude que nous avons fait sur une autre base de données populaire nous avons introduit en tant que concept et expliqué brièvement ce que l’ACID est (Atomicité, _0849 , Isolation and Durability), de l’enregistrement de nouvelles données et transactions ensemble qui peuvent créer des verrous dans une base de données relationnelle : oui, ce que nous décrivons se produit également dans d’autres moteurs de stockage, d’où l’importance du nouveau que PostgreSQL 10 apporte maintenant !
Verrous : le cauchemar d’un programmeur
Bien qu’il semble que les préoccupations des autres ne devraient pas nous intéresser, nous expliquons maintenant pourquoi cela interfère avec nos efforts de supervision des bases de données. Ceci est dû au fait qu’il existe également la supervision de sauvegarde, sa correcte mise en œuvre correcte, stockage dans un endroit sûr, et les bases de données ne sont pas exemptées ils. Nous devons également suivre les conseils de base pour garder leurs performances optimisées, tout harmonisé avec un système de supervision.
Tout ce qui précède peut être effectué avec une attention particulière (dans le cas de la version « Entreprise » de Pandora FMS, il existe en plus des plans de formation des utilisateurs), en plus des administrateurs réseau qui gèrent des répliques du bases de données, bien sûr sur d’autres serveurs dans des emplacements physiques différents.
Ces répliques présentent un certain nombre d’avantages :
● Ils peuvent être physiquement situés à l’extérieur de l’entreprise ou dans ses succursales, en tenant toujours compte des communications cryptées pour transmettre des données d’un endroit à un autre.
● Conceptuellement, il peut être considéré comme des « sauvegardes » mises à jour pratiquement en temps réel.
● Nous pourrons effectuer des audits et des statistiques sur les répliques sans affecter les performances de la base de données principal.
Qu’est-ce qu’une réplique de base de données dans PostgreSQL 10 ?
Une réplique de base de données réplique les données de manière très simple : elle copie les fichiers de la base de données maître, bit par bit, octet par octet. PostgreSQL 10 enregistre chaque élément d’une base de données dans les fichiers qu’il juge nécessaires et pour cela il conserve un enregistrement binaire, une sorte de journal qui résume les changements effectués dans lesdits fichiers qui se produisent lorsque des enregistrements sont ajoutés ou modifiés. Cette méthode de réplication est également utilisée par d’autres moteurs de base de données car il s’agit d’un schéma bien connu.
Un effet secondaire des répliques de base de données est que l’esclave sera indisponible pendant de brefs instants pendant l’écriture des informations répliquées. Nous ne considérons pas cela comme quelque chose de sérieux ou d’inquiétant, la chose la plus importante se produit dans la base de données principale s’il y a un verrou d’enregistrement présent ou, pire encore, un ensemble d’enregistrements appartenant à une transaction qui doit être annulée. Ces ne doivent pas être copiés dans la réplique, car ce sont des informations qui ne seront pas enregistrées définitivement mais qui seront supprimées (seul un résumé des informations sera enregistré).
Voyons ce qui précède avec un exemple simple: deux clients de n’importe quelle banque maintiennent des comptes et le client A veut transférer de l’argent au client B (en réalité, c’est beaucoup plus complexe, il ne s’agit que d’un exemple simplifié). Au moins deux écritures doivent être effectuées dans la base de données : une débitant le montant au client A et une autre créditant le montant au client B : lorsque les deux événements ont été vérifiés, la transaction peut être considérée comme terminée et les changements deviennent permanents.
Que se passerait-il si, en même temps que le client A effectue ledit transfert d’argent au client B, le paiement automatique de sa carte de crédit était réduit, le laissant sans solde suffisant pour le transfert ? Eh bien, l’accréditation qui aurait été faite au client B et le débit effectué au client A ne seront pas enregistrés définitivement mais seront rejetés : c’est ainsi que fonctionne ACID, garantissant l’intégrité des données et rendant ainsi difficile la réplication du information.
Le processus de réplication ne voit pas, ni ne sait rien des enregistrements ou des utilisateurs qui souhaitent enregistrer ou modifier des données, le processus de réplication voit uniquement que les fichiers doivent être les mêmes sur les deux machines et si la source écrit des données dans l’un de ces fichiers, elle doit attendre qu’il se termine et que le fichier soit disponible pour être lu et copié.
Qu’est-ce qu’une réplication logique d’une base de données dans PostgreSQL 10 ?
L’approche est différente dans PostgreSQL 10 et consiste en ce qui suit : tout comme la réplique normale effectue le processus d’interrogation au journal binaire, qui garde la trace des fichiers qui ont été modifiés depuis la dernière réplication réussie. Voici la nouveauté, il traduit ces changements en informations sur les enregistrements qui sont déjà enregistrés en permanence dans la base de données, étant ces enregistrements qui sont lus et ajoutés dans la réplique. De cette manière les verrous sont contournés car on ne sait pas ce qu’ils en résulteront (permanents ou jetés), ce qui est une solution très pratique et ingénieuse et nous apporte également des avantages supplémentaires.
Comment les réplications logiques sont-elles possibles dans PostgreSQL 10 ?
Grâce à cette nouvelle version 10, vous pourrez installer une extension de PostgreSQL appelée pglogical de l’éditeur de logiciels 2ndQuadrant qui a ajouté des fonctionnalités logiques à PostgreSQL depuis la version 9.4.
pglogical est disponible en tant que logiciel libre sous les mêmes conditions de licence que PostgreSQL 10 et pour l’installer suivre les étapes suivantes que nous expliquons de manière pratique dans le cas de l’utilisation de GNU / Linux Debian et de ses dérivés :
● Tout d’abord, ajoutez le référentiel sur votre ordinateur directement à partir de la page Web PostgreSQL, dans le cas d’Ubuntu, la version 9.5 est disponible et nous avons besoin de la version 10.
● Il faut ajouter la clé du référentiel qui garantira que ce que nous téléchargeons est fidèle et précis et en fonction de ce qui est publié sur la page PostgreSQL (détails dans ce lien).
● Nous ferons le même processus avec pglogical, nous ajouterons le référentiel pointant vers la page web 2ndQuadrant pour obtenir la dernière version disponible.
● Il faut également ajouter la clé respective du référentiel 2ndQuadrant (détails dans ce lien).
● Une fois les référentiels configurés, commandez apt-get update puis apt-upgrade.
● Finalement, installez PostgreSQL 10 avec apt-get install postgresql-10 pgadmin3 et pslogical avec apt-get install postgresql-10-pglogical.
● Nous avons testé ces processus sur une machine avec Ubuntu 16.04 64 bits (en fait la base de données proposée lors de l’installation d’Ubuntu Server est précisément PostgreSQL) et le seul revers que nous avons eu concerne le dictionnaire russe pour ce qui concerne le vérificateur Orthographe Hunspell.
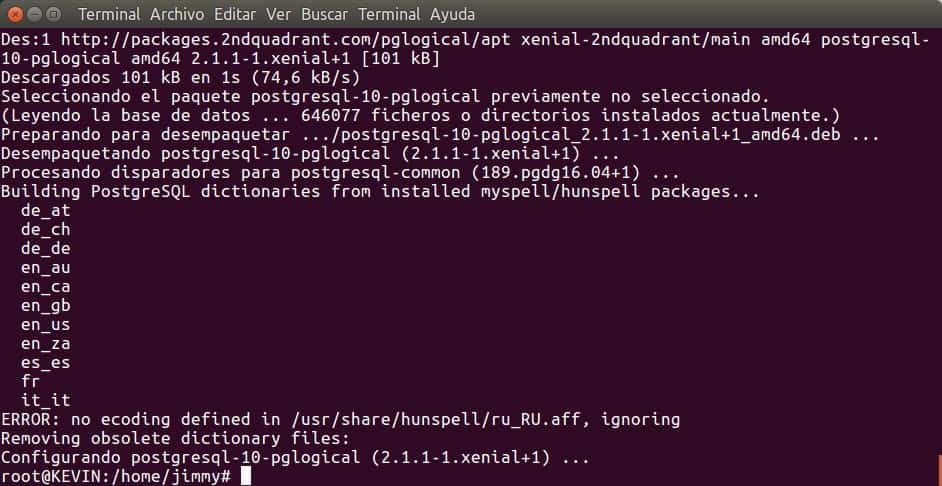
Si vous voulez découvrir la dernière version de développement de pglogical, vous pouvez apporter le code source direct de votre référentiel sur GitHub. Sur le site Web de 2ndQuadrant, ils signalent que la version de pglogical doit toujours correspondre à la version de PostgreSQL installée et que différentes machines peuvent fonctionner avec différentes versions (et se répliquer entre elles) tant que ce qui précède est respecté, il reste donc à la discrétion de chaque administrateur de base de données de travailler de cette façon.
Extension de l’utilitaire à la réplication logique dans PostgreSQL 10
Comme vous pouvez déjà le voir, la réplication logique surmonte certaines limitations techniques de la réplication normale, remplissant ainsi votre objectif de sauvegarde des données, mais vous pouvez aller plus loin : vous savez déjà que la réplication logique n’est PAS une copie fidèle et exacte, octet par octet, de la base de données principale. Par conséquent, les informations que nous copions à partir de la base de données principale atteignent la réplique comme s’il s’agissait d’une base de données « indépendante » et écriront dans ses propres fichiers comme il convient le mieux, c’est-à-dire, selon le type de matériel, le système d’exploitation installé etc.
Ce qui est garanti ici, c’est qu’un enregistrement est copié sur la replique et est identique octet pour octet à son original, , mais la façon dont il est écrit sur le disque dur sera différente sur les deux machines. Pour finir, nous devons noter qu’avec une copie logique, vous pouvez extraire des informations statistiques ou d’audit sans avoir à attendre la réplication que vous avez planifiée de temps en temps pour être écrite exactement (toutes les cinq minutes ou un gigaoctet, quoi qu’il arrive d’abord, par exemple).
Le fait d’extraire des informations statistiques ou d’audit d’une réplique de base de données implique qu’il faut écrire les requêtes (voire modifier les index) qui, bien entendu, n’existent pas dans la base de données master, mais qu’il faut renvoyer le information: lors de l’écriture de ces requêtes (même si elles le sont temporairement) et la base de données n’est plus une copie fidèle et exacte de la base de données master, ce qui pose des problèmes lors de la réplication des fichiers un par un.
Avec la réplication logique, nous n’aurons pas ce problème car il est garanti que tous les enregistrements originaux sont copiés dans la réplique, ce qui garantit (car c’est une machine dédiée à la réplication) qu’ils ne peuvent pas être modifiés ou supprimés mais qu’ils peuvent être lus et consultés.
L’extension de l’utilité de la réplication logique nous conduit à des exemples pratiques, par exemple, il est nécessaire pour le service des cartes de crédit d’une banque de tenir des registres des clients en temps réel sans que leur travail n’impacte la base de données principale : nous pouvons installer un serveur de réplique logique qui copie uniquement les données des clients qui ont des cartes de crédit. Ces données (simplifiées à l’extrême) pourraient être des données personnelles, des comptes bancaires et bien sûr les données des cartes de crédit. Il n’est pas nécessaire de répliquer tous les clients de la banque, seulement une partie d’entre eux ; De même, le service des cartes de crédit peut même créer des tableaux supplémentaires pour analyser les transactions bancaires et être en mesure d’approuver une augmentation de la limite de crédit du client et ainsi de suite de nombreuses autres choses qui se traduisent finalement par de l’argent entrant dans l’entreprise.
Configuration de PostgreSQL 10 pour les réplications logiques
Lors de l’installation de PostgreSQL 10, il apporte par défaut des valeurs par défaut dans la configuration WAL. Sans beaucoup développer sur le sujet, cette configuration permet la récupération après des arrêts inattendus ou des pannes qui ont empêché l’enregistrement des données sur le disque dur.
Dans le cas des réplications, la réplication logique est une nouveauté que beaucoup ignorent encore à propos de car elle est désactivée par défaut. Ce que nous devons faire d’abord est d’avoir un accès exclusif à la base de données (seulement nous serons connectés avec les informations d’identification appropriées) et deuxièmement, nous changeons la valeur du paramètre wal_level par ‘logique’. Pour connaître l’emplacement du fichier postgresql.conf, exécutez simplement la commande : show config_file sur une console psql et éditez le fichier en modifiant : set wal_level = logical et enregistrez le fichier. Ensuite, redémarrez le service, ce qui n’est pas un problème puisque vous êtes seuls connectés et personne d’autre.
Ce changement indiquera à PostgreSQL 10 qu’il doit ajouter les enregistrements correspondants afin de traduire les catalogues binaires en catalogues d’enregistrements, d’où la nécessité d’arrêter momentanément la base de données et de la redémarrer. PostgreSQL 10 a la capacité d’héberger des scripts en langage Python. Par conséquent, la planification de ce que nous décrivons (et de ce qui vient ensuite) dépendra de la collaboration de chaque administrateur de base de données avec le ou les administrateurs réseau afin de profiter de la nuit ou des heures ouvrables pour effectuer les travaux sans impacter le travail quotidien normal de l’entreprise.
Création de publications dans la base de données master
PostgreSQL 10 est configuré pour fonctionner avec publications que nous devons définir dans la base de données master. Connecté avec les informations d’identification appropriées par une fenêtre de terminal, nous créons une publication pour notre exemple du département des cartes de crédit de notre banque imaginaire comme suit :
CREATE PUBLICATION dpto_tc FOR TABLE clients, comptes_bancaires, cartes_de_credit;
Cela créera une publication appelée dpto_tc qui rendra disponibles pour la réplication logique les tables nommées clients, comptes_bancaires et cartes_de_credit.
Si vous devez ajouter toutes les tables à un seul article, écrivez ce qui suit :
CREATE PUBLICATION tous_les_tables FOR ALL TABLES;
Nous devons souligner que par défaut pour les publications que nous ajoutons, les données de ces tables seront copiées dans la réplique logique dans son intégralité, cependant il y a la possibilité de ne copieR que les données qui ont été ajoutées après la création de la publication.
Préparation de la réplique logique
Une fois défini les publications, procédez à la réalisation du travail qui peut impliquer davantage de réflexion et de décision de votre part : créez la structure de données de chacune des tables que contient chacune des publications et si vous utilisez la commande « FOR ALL TABLES » dans au moins une des publications car Vous devrons faire une copie identique de toute la structure de la base de données.
C’est pourquoi nous vous recommandons de faire avancer le travail et de toujours créer une copie complète de toute la structure de la base de données car pglogical ne fera jamais ce travail pour vous et lors de sa réplication, il ne retournera qu’une erreur de table non trouvée (ce qui vous prendra à la supervision du travail de réplication logique, ¡une supervision supplémentaire pour Pandora FMS! ).
Création des abonnements
Une fois que vous avez la structure de données prête à recevoir la réplique logique, créez un abonnement en utilisant les mêmes noms que les publications créées. La syntaxe, une fois que vous êtes correctement connectés à la machine qui contiendra la réplique logique, sera la suivante (nous utiliserons le même exemple de la banque) :
CREATE SUBSCRIPTION dpto_tc CONNECTION 'host=bd_maestra dbname=mi_credenciales ...' PUBLICATION dpto_tc;
Pour faciliter la mémorisation, l’abonnement portera le même nom que la publication et en ce qui concerne les données de connexion car vous devez inclure les valeurs en fonction de la structure et de la configuration de votre réseau : temps d’attente pour expirer la tentative de connexion, port, etc., tous conformes à la norme RFC3986.
Modification des publications
Avec la commande ALTER PUBLICATION dans la base de données master, vous pouvez ajouter de nouvelles tables, supprimer, changer d’utilisateurs ou même renommer la publication, entre autres options.
Maintenir les abonnements à jour
Vous pouvez automatiser la mise à jour des abonnements dans la base de données des esclaves avec la commande suivante :
ALTER SUBSCRIPTION dpto_tc REFRESH PUBLICATION;
Cela mettra à jour les tables que vous avez ajoutées, c’est pourquoi nous avons recommandé de copier la structure complète de toutes les tables de la base de données mais nous insistons: si vous créez une nouvelle table dans la source et l’ajoutez à la publication, aussi vous devrez créer cette structure de table dans la destination puis mettre à jour l’abonnement.
Supervision de la réplication logique dans PostgreSQL 10
Comme la réplication normale, dont vous pouvez extraire son étatavecpg_stat_replication dans les répliques logiques, utilisez pg_stat_subscription de la manière suivante :
SELECT * FROM pg_stat_subscription;
Vous pouvez également sélectionner des champs spécifiques des abonnements :
● application_name: le nom de l’abonnement.
● backend_start: date et heure exactes du début de la réplication logique.
● state: s’il fonctionne, vous recevrez du « streaming » ou de la transmission.
● sent_location: valeur hexadécimale à des fins d’audit binaire.
● write_location: égal que précédent.
● flush_location: égal que précédent.
● sync_state: il renvoie une valeur asynchrone, c’est-à-dire qu’elle s’exécute indépendamment ou en arrière-plan.
Pour terminer cet article dense, il appartient aux programmeurs de créer un script qui se connecte aux deux bases de données en mode lecture seule et compare enregistrement par enregistrement pour voir si les informations correspondent à la fois à l’origine et à la destination. Ledit processus, comme toujours, pourrait être exécuté à l’aube ou le week-end et les résultats devraient être sauvegardés dans une troisième base de données ou dans des fichiers journaux, tout cela pour être supervisés avec Pandora FMS afin que plus tard vous puissiez configurer correctement les alertes respectives.
Conclusion
Nous avons à peine vu la réplication logique car il existe encore de nombreuses autres fonctionnalités telles que :
● Filtrage au niveau de la ligne (enregistrement) : tout comme la commande CHECK fonctionne, nous ne pouvons répliquer que ceux qui répondent à une certaine règle.
● Filtrage au niveau de la colonne (champ) : si une table contient de nombreux champs qui ne sont pas pertinents pour le service des cartes de crédit (nous continuons avec notre exemple pratique), nous ne répliquons que ceux qui nous intéressent.
● pglogical a un paramètre qui est exclusif à ce plugin et qui consiste à retarder les réplications en fonction de la période de temps dont vous avez besoin : vous pourriez avoir besoin que la réplication démarre la nuit lorsque les employés se sont reposés. Cette fonctionnalité n’est pas « intégrée » dans PostgreSQL 10.
Nous pensons qu’avec le temps, ces concepts deviendront des normes dans d’autres environnements de gestion de données, espérons juste que quelques années passent et ils nous auront toujours ici prêts à écrire sur le sujet. Écrivez vos questions ou commentaires ci-dessous, merci!

Traductora a francés e inglés. Me encantan las lenguas. Amante de la ropa oversize, la tarta de queso y el chocolate caliente en invierno. Me gusta leer, escuchar música, viajar y explorar cosas nuevas. Mi frase más temida por aquellos que me conocen es « he estado pensando… »
Translator into French and English. I love languages. Lover of oversized clothes, cheesecake and hot chocolate in winter. I like reading, listening to music, travelling and exploring new things. My most feared phrase by those who know me is « I’ve been thinking… »




