








False positives (as well as false negatives) are a recurrent issue in our experience in monitoring, and after a while we are pretty sure that it’s worth talking about them.
The best way to approach a problem is using an example: Suppose we use Pandora FMS to monitor a network with 500 servers, in which we have defined to make a connectivity check (ping) to each IP. The most common result is that all checks appear in green, however, sometimes and in a random way, some check appears in red. Once we detect that, we perform the ping manually and we make sure that it works perfectly.
The initial conclusion is that our monitoring system, in this case Pandora FMS, is failing, but what is really happening is that our monitoring system is not configured as it should, and that is exactly where the problem is.
To test it, we just have to do a ping to one of these IP’s that sometimes fail y leave it for hours. We will see that occasionally, in 1 of 1.000 checks or even in 1 of 10.000 the ping fails, but we shouldn’t worry about that because is relatively common for networks to have that behavior sometimes.
The following screenshot shows us how our entire monitoring system is in green and however, a ping from the console fails. If in this precise moment Pandora FMS had been doing a check, it would have probably turned into red.
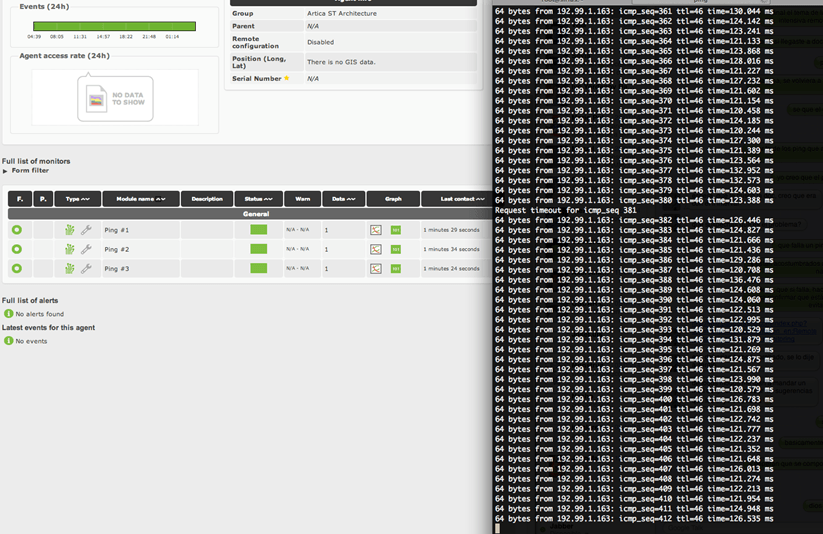
All monitoring systems have several parameters to control this behavior. Maybe we are interested in having the maximum detail level, as Pandora FMS does by default, or otherwise we want to attenuate the detail to avoid warning at the minimum failure. Below we list many control mechanisms available in Pandora FMS (also available in other monitoring systems) to avoid this kind of behavior:
-
- Nº of checks: Sometimes the first ping fails, but the second one works, that’s why almost all the systems have a number of retries. There have been cases of systems where the first ping always failed, and it only worked when we pinged constantly with three retries. In this kind of cases (infrequent), the best option is to use other adapted checks (a custom plugin) instead of the standard check.
-
- Timeout: In case we want to check remote systems maybe we need to increase the Timeout response. If we talk about a LAN, a second is more than enough, in the Internet we’d probably find a lot of false positives caused by a very low Timeout. On the other hand, setting a high Timeout of 10 seconds for example, would be a drag for the capacity of our server, because in the worst case it would have to wait 10 seconds per each check considering that the system is not responding.
-
- Sensibility package loss: It could be hard to believe, but different ping tools behave differently, and even the same ping tool in different systems behave differently. Sometimes, the monitoring tool allows to set up this behavior to be tuned. We can`t compare the results of tools like ping, fping, hping or nmap as it will return different values. That’s why we need to know if our monitoring tool has settings that are generally respect to the tolerance of package loss or to the speed of transmission of information (related with Timeout and Nº of checks parameters). A bad configuration can make false positives appear. In an extreme case, because of this intolerance, we can find out with our monitoring tool a network with a package loss negligible for other tools. This is a real case with Pandora ICMP Enterprise server, using T3 parameter in the Nmap scan, in which we can appreciate that some systems don’t respond randomly because of a negligible package loss for the most part of the conventional monitoring systems.
-
- Flipflop: The phenomenon in which an element that usually behaves in a stable way “bounces” more or less regular. To avoid that these bounces affect to how we perceive the value we will put a bound threshold. As this sometimes has “peaks” we’ll assume that there is a problem when that failure happens twice.
- Flipflop threshold: To avoid having to wait till the monitorization process finish we will set the flipflop threshold to control the element faster and better. This way, if something fails we will know instantly. It’ssually combined with the previous parameter (Flipflop) so that if it fails we hope to have a confirmation in a shorter time, in Pandora FMS that is called Intensive Monitoring.
In the previous example we set the flipflop threshold in 1 and the flipflop interval in 30 seconds, so that, if anything fails we will be aware and we will repeat the test after 30 seconds. If the fails again, we’ll consider it as down and we will send an alert to the system, if not, we will consider it as a false positive and we will avoid alerting the system.
In conclusion, before claiming that our system has false positives, it’s important to review and properly set up all those elements in our monitoring software to avoid unnecessary alerts.
 |
|
| Do you want to know more about false positives in Pandora FMS |
Do you want to get Pandora FMS? |

Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring. Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring.






