









Control de Congestión de TCP: esquema básico y algoritmo TCP CUBIC
El control de congestión de TCP es parte fundamental de este protocolo y con los años ha experimentando un proceso de mejora constante a través de la generación de diferentes versiones, como TCP Tahoe, Reno, Vegas, etc.
Es interesante el caso de la versión TCP CUBIC, la cual desde hace algunos años es el control de congestión que aplican por defecto los sistemas Linux/Unix.
TCP CUBIC se hace más interesante aún ya que Microsoft ha decidido que esta versión sea parte fundamental de productos como Windows 10 y Windows Server 2019, tal como se lee en este documento sobre las novedades de Windows Server 2019 y en este sobre Windows 10.
El hecho de tener una misma distribución en los entornos Linux y Windows ha llevado a los administradores de red a repasar la idea tras el control de congestión que plantea TCP y lo que implica TCP CUBIC.
Justo para apoyarlos en esta tarea es que redactamos este artículo. Comencemos por repasar la idea fundamental del control de congestión de TCP.



Manejo de ventanas como base para el control de congestión
TCP introduce el concepto de “ventanas” para lograr establecer un control de flujo de tráfico y gestionar las conexiones entre dos dispositivos: un emisor y un receptor.
Así pues, la implementación básica se conoce como ventana deslizante o rwnd (receive window), en la que, por conexión, se establece un tamaño de ventana que representa la cantidad de paquetes que el emisor puede enviar al receptor sin esperar los paquetes de reconocimiento (paquetes ACKs).
Ahora bien, el protocolo de ventana deslizante gestiona la conexión en función de las capacidades de buffer del equipo receptor, pero no reconoce los problemas de congestión asociados con la red.
Para lograr adecuar la transmisión dependiendo del nivel de congestión, TCP introduce otra ventana. Se trata de la ventana de congestión o cwnd con la cual pretende regular la cantidad de paquetes enviados en función de la percepción que tiene TCP de la congestión.
Ahora bien, ¿cómo percibe TCP la congestión en la red y qué hace en consecuencia?
La idea básica es la siguiente:
- Si hay paquetes perdidos se asume que hay congestión en la red, y la pérdida de paquetes se evalúa en función de los paquetes de reconocimiento recibidos y no recibidos.
- Si se determina que existe congestión se modifica la ventana de congestión de forma que el emisor ralentice el envío de sus paquetes.
- Si se determina que no hay congestión se modificará la ventana de congestión de forma que el emisor pueda enviar más paquetes.
Sobre este procedimiento básico encontramos múltiples algoritmos que lo implementan.
Los algoritmos proponen cosas como cuántos paquetes ACK no recibidos implican congestión, en cuánto disminuir o incrementar la ventana cwnd, cómo calcular el ratio de transferencia a partir de la ventana de congestión, etc.
A continuación les sugerimos repasar la evolución de estos algoritmos de manera de tener claro el alcance de aquellos que se utilizan actualmente.
Evolución de los algoritmos de control de congestión
La evolución del control de congestión de TCP comienza a mediados de los años 80.
Hasta ese momento el control de flujo de transmisión basado en ventanas deslizantes había funcionado bastante bien, pero con la popularización de Internet la congestión pasó a ser un problema.
Entre 1986 y 1988, Van Jacobson propuso el esquema básico de control de congestión y desarrolló el primer protocolo de implementación, que se conoce como TCP Tahoe.
Aquí se propone que el ratio de transmisión debe considerar el valor de las ventanas de recepción y de congestión, quedando el emisor restringido a un ratio de transmisión cuyo valor mínimo es rwnd y su máximo es cwnd.
En 1990 con TCP Reno se introdujo la aplicación del algoritmo AIMD (additive increase / multiplicative decrease) según el cual:
- Se incrementará de forma paulatina el ratio de transmisión hasta que alguna pérdida de paquetes ocurra.
- El incremento se hará aumentando de forma lineal la ventana de congestión, es decir, sumando un valor.
- En caso de que se infiera congestión, se disminuirá el ratio de transmisión, pero en este caso se hará una disminución multiplicando por un valor.
Luego de TCP Reno aparecieron otros algoritmos y versiones de TCP que procuraban tomar los preceptos del control de congestión y refinarlo, experimentándose una gran diversificación de versiones y alcances.
Así tenemos que TCP Vegas plantea prestar atención a los valores de retardo para inferir congestión o el caso de ECN (Explicit Congestion Notification) que introduce la posibilidad de que los enrutadores de la red notifiquen condiciones de congestión a los equipos emisores.
También se ha promovido el desarrollo de una buena cantidad de mecanismos que permiten la implementación de AIMD, tales como Slow Start, Fast Retransmission, Fast recovery, Adaptive timeout o ACK clocking.
En todo caso, es interesante precisar la situación que teníamos hasta hace poco.
El mundo Linux se había decantado por TCP CUBIC, el cual es un heredero de TCP Reno y BIC TCP, por lo que se basa en pérdida de paquetes y no en valores de retardo para determinar congestión.
En tanto que el mundo Windows utilizaba un algoritmo llamado TCP Compound, que proviene de TCP Fast, el cual a su vez es heredero de TCP Vegas, por lo que se basan en retardos para inferir congestión.
Tal como mencionamos al comienzo de este artículo, esta situación cambió en el momento en el que Microsoft apostó por introducir TCP CUBIC en sus nuevos productos.
TCP CUBIC
TCP CUBIC es un algoritmo de control de congestión que surge con la idea de tomar ventaja del hecho de que actualmente los enlaces de comunicaciones suelen disponer de niveles de ancho de banda cada vez mayores.
En una red compuesta por enlaces de amplios anchos de banda un algoritmo de control de congestión que lentamente incrementa el ratio de transmisión puede terminar por desperdiciar la capacidad los enlaces.
La intención es disponer de un algoritmo que trabaje con ventanas de congestión cuyos procesos de incremento sean más agresivos, pero que se restrinjan de sobrecargar la red.
Para lograr esto se propone que el esquema de incremento y disminución del ratio de transmisión se establezca de acuerdo a una función cúbica. Veamos la siguiente figura:
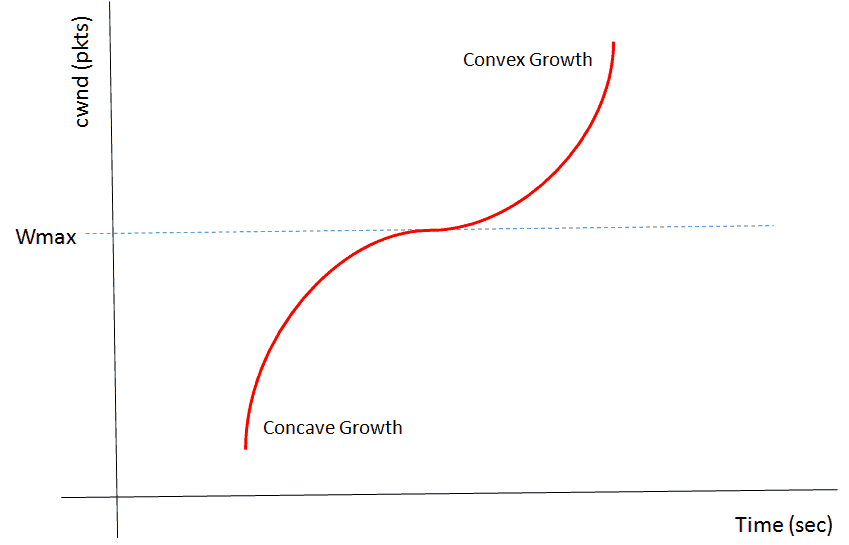
Descripción: Función cúbica que regula la ventana de congestión según el algoritmo Cubic
Fuente: IEEE Xplore Digital Library:
https://ieeexplore.ieee.org/document/8368259
El procedimiento que sigue el algoritmo es, de forma resumida, el siguiente:
- En el momento de experimentar un evento de congestión se registrará el tamaño de la ventana para ese instante como Wmax o el tamaño máximo de ventana.
- Se fijará el valor Wmax como el punto de inflexión de la función cúbica que regirá el crecimiento de la ventana de congestión.
- Luego se recomenzará la transmisión con un valor de ventana menor y, de no experimentarse congestión, este valor se incrementará según la porción cóncava de la función cúbica.
- A medida que la ventana se aproxime al Wmax los incrementos irán ralentizándose.
- Una vez alcanzado el punto de inflexión -es decir, Wmax- se seguirá aumentando discretamente el valor de la ventana.
- Finalmente, si la red sigue sin experimentar congestión alguna, se seguirá aumentando el tamaño de la ventana según la porción convexa de la función.
Como vemos, CUBIC implementa un esquema de incrementos grandes al principio, los cuales disminuyen alrededor del tamaño de ventana que causó la última congestión, para luego seguir aumentado con incrementos grandes.
Si el lector está interesado en profundizar sobre los detalles técnicos del algoritmo CUBIC puede comenzar por leer el siguiente trabajo: https://www.cs.princeton.edu/courses/archive/fall16/cos561/papers/Cubic08.pdf
El control de congestión y las herramientas de monitorización
Un punto interesante del control de congestión que aporta TCP es que se trata de procesos con las siguientes características:
- Estos procesos corren solo en los equipos emisores.
- No generan tráfico.
- Propician un reparto equitativo de la capacidad de transmisión de la red. Como cada equipo decide sobre su capacidad de transmisión, atendiendo solo al comportamiento de la red que él observa, no se favorece ni perjudica a ningún equipo emisor bajo ninguna circunstancia.
Ahora bien, es fácil entender que no es justo comparar las capacidades de los algoritmos de control de congestión de TCP con las capacidades de una herramienta de monitorización, porque nos estamos moviendo en dos universos completamente distintos.
Sin embargo, les proponemos repensar el alcance de una herramienta de monitorización de propósitos generales como Pandora FMS desde el ángulo de estos algoritmos.
Así surgen los siguientes puntos:
- El objeto de estudio de una herramienta de monitorización es mucho más amplio: una herramienta de monitorización debe considerar todos los protocolos presentes en la plataforma, no solo TCP.
- La idea de una herramienta de monitorización es incluir bajo su esquema a todos los componentes, ofreciendo siempre una visión global de la plataforma.
- Los mecanismos que utiliza una herramienta de monitorización, tales como los asociados con la administración de red como SNMP o con el control de flujo de tráfico como NetFlow, son protocolos que implican el envío de paquetes asociados con sus funciones. Ahora bien, por supuesto las herramientas de monitorización tienen como objetivo establecer esquema que interfiera lo justo con el rendimiento global de la plataforma.
- La causa raíz de la congestión: el acercamiento que logran las herramientas de monitorización pretende llegar a la causa raíz de la congestión. Quizás la causa de un estado de congestión esté en la configuración errada de un protocolo de enrutamiento, lo que no se va a corregir con que los equipos emisores modifiquen su capacidad de transmisión.
- Para finalizar debemos decir que un objetivo de las herramientas de monitorización es generar información que permita predecir una situación de congestión antes de que aparezca.
Para profundizar en la idea de evaluar cómo podemos utilizar Pandora FMS en cuanto a congestión le recomendamos este interesante artículo sobre monitorización de ancho de banda.
Además, si el lector aún no dispone de una herramienta de monitorización para su plataforma, debe saber que ha llegado al sitio correcto. De hecho, si tiene más de 100 equipos le sugerimos evaluar Pandora FMS Enterprise.
Y si cuenta con un número reducido de equipos le recomendamos descargar la versión Pandora FMS Open Source, aquí






