









Today, many companies generate and store huge amounts of data. To give you an idea, decades ago, the size of the Internet was measured in Terabytes (TB) and now it is measured in Zettabytes (ZB).
Relational databases were designed to meet the storage and information management needs of the time. Today we have a new scenario where social networks, IoT devices and Edge Computing generate millions of unstructured and highly variable data. Many modern applications require high performance to provide quick responses to user queries.
In relational DBMSs, an increase in data volume must be accompanied by improvements in hardware capacity. This technological challenge forced companies to look for more flexible and scalable solutions.
NoSQL databases have a distributed architecture that allows them to scale horizontally and handle continuous and fast data flows. This makes them a viable option in high-demand environments such as streaming platforms where data processing takes place in real time.
Given the interest in NoSQL databases in the current context, we believe it is essential to develop a user guide that helps developers understand and effectively use this technology. In this article we aim to clarify some basics about NoSQL, giving practical examples and providing recommendations on implementation and optimization to make the most of its advantages.
- NoSQL data modeling
- NoSQL data storage and partitioning
- Replication in NoSQL databases
- CAP theorem and consistency of NoSQL databases
- BASIS and eventual consistency model in NoSQL
- Tree indexing in NoSQL databases. What are the best-known structures?
- Comparison between NoSQL database management systems
- Challenges in managing NoSQL databases. How does Pandora FMS help?
NoSQL data modeling
One of the biggest differences between relational and non-relational bases lies in the approach we took to data modeling.
NoSQL databases do not follow a rigid and predefined scheme. This allows developers to freely choose the data model based on the features of the project.
The fundamental goal is to improve query performance, getting rid of the need to structure information in complex tables. Thus, NoSQL supports a wide variety of denormalized data such as JSON documents, key values, columns, and graph relationships.
Each NoSQL database type is optimized for easy access, query, and modification of a specific class of data. The main ones are:
- Key-value: Redis, Riak or DyamoDB. These are the simplest NoSQL databases. They store the information as if it were a dictionary based on key-value pairs, where each value is associated with a unique key. They were designed to scale quickly ensuring system performance and data availability.
- Documentary: MongoDB, Couchbase. Data is stored in documents such as JSON, BSON or XML. Some consider them an upper echelon of key-value systems since they allow encapsulating key-value pairs in more complex structures for advanced queries.
- Column-oriented: BigTable, Cassandra, HBase. Instead of storing data in rows like relational databases do, they do it in columns. These in turn are organized into logically ordered column families in the database. The system is optimized to work with large datasets and distributed workloads.
- Graph-oriented: Neo4J, InfiniteGraph. They save data as entities and relationships between entities. The entities are called “nodes” and the relationships that bind the nodes are the “edges”. They are perfect for managing data with complex relationships, such as social networks or applications with geospatial location.
NoSQL data storage and partitioning
Instead of making use of a monolithic and expensive architecture where all data is stored on a single server, NoSQL distributes the information on different servers known as “nodes” that join in a network called “cluster“.
This feature allows NoSQL DBMSs to scale horizontally and manage large volumes of data using partitioning techniques.
What is NoSQL database partitioning?
It is a process of breaking up a large database into smaller, easier-to-manage chunks.
It is necessary to clarify that data partitioning is not exclusive to NoSQL. SQL databases also support partitioning, but NoSQL systems have a native function called “auto-sharding” that automatically splits data, balancing the load between servers.
When to partition a NoSQL database?
There are several situations in which it is necessary to partition a NoSQL database:
- When the server is at the limit of its storage capacity or RAM.
- When you need to reduce latency. In this case you get to balance the workload on different cluster nodes to improve performance.
- When you wish to ensure data availability by initiating a replication procedure.
Although partitioning is used in large databases, you should not wait for the data volume to become excessive because in that case it could cause system overload.
Many programmers use AWS or Azure to simplify the process. These platforms offer a wide variety of cloud services that allow developers to skip the tasks related to database administration and focus on writing the code of their applications.
Partitioning techniques
There are different techniques for partitioning a distributed architecture database.
- Clustering
It consists of grouping several servers so that they work together as if they were one. In a clustering environment, all nodes in the cluster share the workload to increase system throughput and fault tolerance. - Separation of Reads and Writes
It consists of directing read and write operations to different nodes in the cluster. For example, read operations can be directed to replica servers acting as children to ease the load on the parent node. - Sharding
Data is divided horizontally into smaller chunks called “shards” and distributed across different nodes in the cluster.
It is the most widely used partitioning technique in databases with distributed architecture due to its scalability and ability to self-balance the system load, avoiding bottlenecks. - Consistent Hashing
It is an algorithm that is used to efficiently allocate data to nodes in a distributed environment.
The idea of consistent hashes was introduced by David Karger in a research paper published in 1997 and entitled “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web“.
In this academic work, the “Consistent Hashing” algorithm was proposed for the first time as a solution to balance the workload of servers with distributed databases.
It is a technique that is used in both partitioning and data replication, since it allows to solve problems common to both processes such as the redistribution of keys and resources when adding or removing nodes in a cluster.
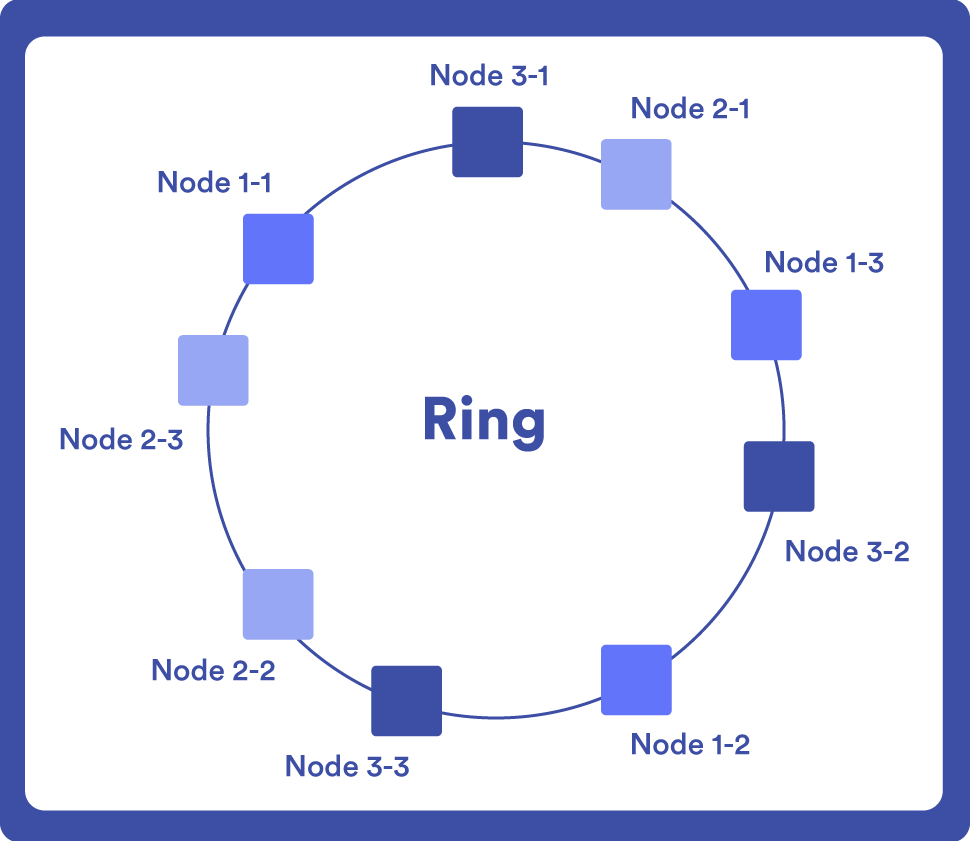
Nodes are represented in a circular ring and each data is assigned to a node using a hash function. When a new node is added to the system, the data is redistributed between the existing nodes and the new node.
The hash works as a unique identifier so that when you make a query, you just have to locate that point on the ring.
An example of a NoSQL database that uses “Consistent Hashing” is DynamoDB, since one of its strengths is incremental scaling, and to achieve this it needs a procedure capable of fractionating data dynamically.
Replication in NoSQL databases
It consists of creating copies of the data on multiple machines. This process seeks to improve database performance by distributing queries among different nodes. At the same time, it ensures that the information will continue to be available, even if the hardware fails.
The two main ways to perform data replication (in addition to the Consistent Hashing that we already mentioned in the previous section) are:
Master-slave server
Writing is made to the primary node and from there data is replicated to secondary nodes.
Peer to peer
All nodes in the cluster have the same hierarchical level and can accept writing. When data is written to one node it spreads to all the others. This ensures availability, but can also lead to inconsistencies if conflict resolution mechanisms are not implemented (for example, if two nodes try to write to the same location at the same time).

CAP theorem and consistency of NoSQL databases.
The CAP theorem was introduced by Professor Eric Brewer of the University of Berkeley in the year 2000. He explains that a distributed database can meet two of these three qualities at the same time:
- Consistency: All requests after the writing operation get the same value, regardless of where the queries are made.
- Availability: The database always responds to requests, even if a failure takes place.
- Partition Tolerance: The system continues to operate even if communication between some nodes is interrupted.

Under this scheme we could choose a DBMS that is consistent and partition tolerant (MongoDB, HBase), available and partition tolerant (DynamoDB, Cassandra), or consistent and available (MySQL), but all three features cannot be preserved at once.
Each development has its requirements and the CAP theorem helps us find the DBMS that best suits your needs. Sometimes it is imperative for data to be consistent at all times (for example, in a stock control system). In these cases, we usually work with a relational database. In NoSQL databases, consistency is not one hundred percent guaranteed, since changes must propagate between all nodes in the cluster.
BASIS and eventual consistency model in NoSQL
BASE is a concept opposed to the ACID properties (atomicity, consistency, isolation, durability) of relational databases. In this approach, we prioritize data availability over immediate consistency, which is especially important in applications that process data in real time.
The BASE acronym means:
- Basically Available: The database always sends a response, even if it contains errors if readings occur from nodes that did not yet receive the last writing.
- Soft state: The database may be in an inconsistent state when reading takes place, so you may get different results on different readings.
- Eventually Consistent: Database consistency is reached once the information has been propagated to all nodes. Up to that point we talk about an eventual consistency.
Even though the BASE approach arose in response to ACID, they are not exclusionary options. In fact, some NoSQL databases like MongoDB offer configurable consistency.
Tree indexing in NoSQL databases. What are the best-known structures?
So far we have seen how data is distributed and replicated in a NoSQL database, but we need to explain how it is structured efficiently to make its search and retrieval easier.
Trees are the most commonly used data structures. They organize nodes hierarchically starting from a root node, which is the first tree node; parent nodes, which are all those nodes that have at least one child; and child nodes, which complete the tree.
The number of levels of a tree determines its height. It is important to consider the final size of the tree and the number of nodes it contains, as this can influence query performance and data recovery time.
There are different tree indexes that you may use in NoSQL databases.
B Trees
They are balanced trees and perfect for distributed systems for their ability to maintain index consistency, although they can also be used in relational databases.
The main feature of B trees is that they can have several child nodes for each parent node, but they always keep their height balanced. This means that they have an identical or very similar number of levels in each tree branch, a particularity that makes it possible to handle insertions and deletions efficiently.
They are widely used in filing systems, where large data sets need to be accessed quickly.
T Trees
They are also balanced trees that can have a maximum of two or three child nodes.
Unlike B-trees, which are designed to make searches on large volumes of data easier, T-trees work best in applications where quick access to sorted data is needed.
AVL Trees
They are binary trees, which means that each parent node can have a maximum of two child nodes.
Another outstanding feature of AVL trees is that they are balanced in height. The self-balancing system serves to ensure that the tree does not grow in an uncontrolled manner, something that could harm the database performance.
They are a good choice for developing applications that require quick queries and logarithmic time insertion and deletion operations.
KD Trees
They are binary, balanced trees that organize data into multiple dimensions. A specific dimension is created at each tree level.
They are used in applications that work with geospatial data or scientific data.
Merkle Trees
They represent a special case of data structures in distributed systems. They are known for their utility in Blockchain to efficiently and securely encrypt data.
A Merkle tree is a type of binary tree that offers a first-rate solution to the data verification problem. Its creator was an American computer scientist and cryptographer named Ralph Merkle in 1979.
Merkle trees have a mathematical structure made up by hashes of several blocks of data that summarize all transactions in a block.

Data is grouped into larger datasets and related to the main nodes until all the data within the system is gathered. As a result, the Merkle Root is obtained.
How is the Merkle Root calculated?
1. The data is divided into blocks of a fixed size.
2. Each data block is subjected to a cryptographic hash function.
3. Hashes are grouped into pairs and a function is again applied to these pairs to generate their corresponding parent hashes until only one hash remains, which is the Merkle root.
The Merkle root is at the top of the tree and is the value that securely represents data integrity. This is because it is strongly related to all datasets and the hash that identifies each of them. Any changes to the original data will alter the Merkle Root. That way, you can make sure that the data has not been modified at any point.
This is why Merkle trees are frequently employed to verify the integrity of data blocks in Blockchain transactions.
NoSQL databases like Cassandra draw on these structures to validate data without sacrificing speed and performance.
Comparison between NoSQL database management systems
From what we have seen so far, NoSQL DBMSs are extraordinarily complex and varied. Each of them can adopt a different data model and present unique storage, consultation and scalability features. This range of options allows developers to select the most appropriate database for their project needs.
Below, we will give as an example two of the most widely used NoSQL DBMSs for the development of scalable and high-performance applications: MongoDB and Apache Cassandra.
MongoDB
It is a documentary DBMS developed by 10gen in 2007. It is open source and has been created in programming languages such as C++, C and JavaScript.

MongoDB is one of the most popular systems for distributed databases. Social networks such as LinkedIn, telecommunications companies such as Telefónica or news media such as the Washington Post use MongoDB.
Here are some of its main features.
- Database storage with MongoDB: MongoDB stores data in BSON files (binary JSON). Each database consists of a collection of documents. Once MongoDB is installed and Shell is running, you may create the DB just by indicating the name you wish to use. If the database does not already exist, MongoDB will automatically create it when adding the first collection. Similarly, a collection is created automatically when you store a file in it. You just have to add the first document and execute the “insert” statement and MongoDB will create an ID field assigning it an ObjectID value that is unique for each machine at the time the operation is executed.
- DB Partitioning with MongoDB: MongoDB makes it easy to distribute data across multiple servers using the automatic sharding feature. Data fragmentation takes place at the collection level, distributing documents among the different cluster nodes. To carry out this distribution, a “partition key” defined as a field is used in all collection documents. Data is fragmented into “chunks”, which have a default size of 64 MB and are stored in different shards within the cluster, ensuring that there is a balance. MongoBD monitors continuously chunk distribution among the shard nodes and, if necessary, performs automatic rebalancing to ensure that the workload supported by these nodes is balanced.
- DB Replication with MongoDB: MongoDB uses a replication system based on the master-slave architecture. The master server can perform writing and reading operations, but slave nodes only perform reads (replica set). Updates are communicated to slave nodes via an operation log called oplog.
- Database Queries with MongoDB: MongoDB has a powerful API that allows you to access and analyze data in real time, as well as perform ad-hoc queries, that is, direct queries on a database that are not predefined. This gives users the ability to perform custom searches, filter documents, and sort results by specific fields. To carry out these queries, MongoDB uses the “find” method on the desired collection or “findAndModify” to query and update the values of one or more fields simultaneously.
- DB Consistency with MongoDB: From version 4.0 (the most recent one is 6.0), MongoDB supports ACID transactions at document level. The “snapshot isolation” function provides a consistent view of the data and allows atomic operations to be performed on multiple documents within a single transaction. This feature is especially relevant for NoSQL databases, as it poses solutions to different consistency-related issues, such as concurrent writes or queries that return outdated file versions. In this respect, MongoDB comes very close to the stability of RDMSs.
- Database indexing with MongoDB: MongoDB uses B trees to index the data stored in its collections. This is a variant of the B trees with index nodes that contain keys and pointers to other nodes. These indexes store the value of a specific field, allowing data recovery and deletion operations to be more efficient.
- DB Security with MongoDB: MongoDB has a high level of security to ensure the confidentiality of stored data. It has several authentication mechanisms, role-based access configuration, data encryption at rest and the possibility of restricting access to certain IP addresses. In addition, it allows you to audit the activity of the system and keep a record of the operations carried out in the database.
Apache Cassandra
It is a column-oriented DBMS that was developed by Facebook to optimize searches within its platform. One of the creators of Cassandra is computer scientist Avinash Lakshman, who previously worked for Amazon, as part of the group of engineers who developed DynamoDB. For that reason, it does not come as a surprise that it shares some features with this other system.
In 2008 it was launched as an open source project, and in 2010 it became a top-level project of the Apache Foundation. Since then, Cassandra continued to grow to become one of the most popular NoSQL DBMSs.
Although Meta uses other technologies today, Cassandra is still part of its data infrastructure. Other companies that use it are Netflix, Apple or Ebay. In terms of scalability, it is considered one of the best NoSQL databases.

Let’s take a look at some of its key properties:
- Database storage with Apache Cassandra: Cassandra uses a “Column Family” data model, which is similar to relational databases, but more flexible. It does not refer to a hierarchical structure of columns that contain other columns, but rather to a collection of key-value pairs, where the key identifies a row and the value is a set of columns. It is designed to store large amounts of data and perform more efficient writing and reading operations.
- DB Partitioning with Apache Cassandra: For data distribution, Cassandra uses a partitioner that distributes data to different cluster nodes. This partitioner uses the algorithm “consistent hashing” to assign a unique partition key to each data row. Data possessing the same partition key will stay together on the same nodes. It also supports virtual nodes (vnodes), which means that the same physical node may have multiple data ranges.
- DB Replication with Apache Cassandra: Cassandra proposes a replication model based on Peer to peer in which all cluster nodes accept reads and writes. By not relying on a master node to process requests, the chance of a bottleneck occurring is minimal. Nodes communicate with each other and share data using a gossiping protocol.
- DB Queries with Apache Cassandra: Like MongoDB, Cassandra also supports ad-hoc queries, but these tend to be more efficient if they are based on the primary key. In addition, it has its own query language called CQL (Cassandra Query Language) with a syntax similar to that of SQL, but instead of using joins, it takes its chances on data denormalization.
- DB Indexation with Apache Cassandra: Cassandra uses secondary indexes to allow efficient queries on columns that are not part of the primary key. These indices may affect individual columns or multiple columns (SSTable Attached Secondary Index). They are created to allow complex range, prefix or text search queries in a large number of columns.
- DB Coherence with Apache Cassandra: By using Peer to Peer architecture, Cassandra plays with eventual consistency. Data is propagated asynchronously across multiple nodes. This means that, for a short period of time, there may be discrepancies between the different replicas. However, Cassandra also provides mechanisms for setting the consistency level. When a conflict takes place (for example, if the replicas have different versions), use the timestamp and validate the most recent version. In addition, perform automatic repairs to maintain data consistency and integrity if hardware failures or other events that may cause discrepancies between replicas take place.
- DB Security with Apache Cassandra: To use Cassandra in a safe environment, it is necessary to perform configurations, since many options are not enabled by default. For example, activate the authentication system and set permissions for each user role. In addition, it is critical to encrypt data in transit and at rest. For communication between the nodes and the client, data in transit can be encrypted using SSL/TLS.
Challenges in managing NoSQL databases. How does Pandora FMS help?
NoSQL DBMSs offer developers the ability to manage large volumes of data and scale horizontally by adding multiple nodes to a cluster.
To manage these distributed infrastructures, it is necessary to master different data partitioning and replication techniques (for example, we have seen that MongoDB uses a master-slave architecture, while Cassandra prioritizes availability with the Peer to peermodel).
Unlike RDMS, which share many similarities, in NoSQL databases there is no common paradigm and each system has its own APIs, languages and a different implementation, so getting used to working with each of them can be a real challenge.
Considering that monitoring is a fundamental component for managing any database, we must be pragmatic and rely on those resources that make our lives easier.
Both MongoDB and Apache Cassandra have commands that return system status information and allow problems to be diagnosed before they become critical failures. Another possibility is to use Pandora FMS software to simplify the whole process.
How to do so?
If this is a database in MongoDB, download Pandora FMS plugin for MongoDB. This plugin uses the mongostat command to collect basic information about system performance. Once the relevant metrics are obtained, they are sent to Pandora FMS data server for their analysis.
On the other hand, if the database works with Apache Cassandra, download the corresponding plugin for this system. This plugin obtains the information by internally running the tool nodetool, which is already included in the standard Cassandra installation, and offers a wide range of commands to monitor server status. Once the results are analyzed, the plugin structures the data in XML format and sends it to Pandora FMS server for further analysis and display.
For these plugins to work properly, copy the files to the plugin directory of Pandora FMS agent, edit the configuration file and, finally, restart the system (the linked articles explain the procedure very well).
Once the plugins are active, you will be able to monitor the activity of the cluster nodes in a graph view and receive alerts should any failures take place. These and other automation options help us save considerable time and resources in maintaining NoSQL databases.
Create a free account and discover all Pandora FMS utilities to boost your digital project!
And if you have doubts about the difference between NoSQL and SQL you can consult our post “NoSQL vs SQL: main differences and when to choose each of them“.

I studied Philology, but life circumstances led me to work in the Marketing sector as a content writer. I am passionate about the world of blogging and the opportunity to learn that comes with each new project. I invite you to follow my posts on the Pandora FMS blog to discover the technological trends that are transforming the business world.






