









En la actualidad muchas empresas generan y almacenan enormes cantidades de datos. Para hacernos una idea, décadas atrás, el tamaño de Internet se medía en Terabytes (TB) y ahora se mide en Zettabytes (ZB).
Las bases de datos relacionales se diseñaron para satisfacer las necesidades de almacenamiento y gestión de la información que había en la época. Hoy en día tenemos un escenario nuevo donde las redes sociales, los dispositivos IoT y el Edge Computing generan millones de datos no estructurados y altamente variables. Muchas aplicaciones modernas requieren un alto rendimiento para proporcionar respuestas rápidas a las consultas de los usuarios.
En los SGBD relacionales un incremento en el volumen de datos debe ir acompañado de mejoras en la capacidad del hardware. Este desafío tecnológico obligó a las empresas a buscar soluciones más flexibles y escalables.
Las bases de datos NoSQL tienen una arquitectura distribuida que les permite escalar horizontalmente y manejar flujos de datos continuos y rápidos. Esto las convierte en una opción viable en entornos de alta demanda como las plataformas de streaming donde el procesamiento de los datos se realiza en tiempo real.
Ante el interés que despiertan las bases de datos NoSQL en el contexto actual, nos parece indispensable elaborar una guía de uso que ayude a los desarrolladores a comprender y utilizar eficazmente esta tecnología. En este artículo nos proponemos aclarar algunos conceptos básicos sobre NoSQL, poniendo ejemplos prácticos y proporcionando recomendaciones sobre implementación y optimización para aprovechar al máximo sus ventajas.
- Modelado de datos en NoSQL
- Almacenamiento y particionado de datos en NoSQL
- Replicado en bases de datos NoSQL
- Teorema de CAP y consistencia de las bases de datos NoSQL
- BASE y el modelo de consistencia eventual en NoSQL
- Indexación de árboles en bases de datos NoSQL. ¿Cuáles son las estructuras más conocidas?
- Comparación entre sistemas de gestión de bases de datos NoSQL
- Desafíos en la administración de las bases de datos NoSQL ¿Cómo ayuda Pandora FMS?
Modelado de datos en NoSQL
Una de las mayores diferencias entre las bases de relacionales y no relacionales radica en el enfoque que adoptamos para el modelado de datos.
Las BBDD NoSQL no siguen un esquema rígido y predefinido. Esto permite a los desarrolladores elegir libremente el modelo de datos en función de las características del proyecto.
El objetivo fundamental es mejorar el rendimiento de las consultas, eliminando la necesidad de estructurar la información en tablas complejas. Así, NoSQL admite una gran variedad de datos desnormalizados como documentos JSON, valores clave, columnas y relaciones de grafos.
Cada tipo de base de datos NoSQL está optimizado para facilitar el acceso, consulta y modificación de una clase específica de datos. Las principales son:
- Clave-valor: Redis, Riak o DyamoDB. Son las BBDD NoSQL más sencillas. Almacenan la información como si fuera un diccionario basado en pares de clave-valor, donde cada valor está asociado con una clave única. Se diseñaron con la finalidad de escalar rápidamente garantizando el rendimiento del sistema y la disponibilidad de los datos.
- Documentales: MongoDB, Couchbase. Los datos se almacenan en documentos como JSON, BSON o XML. Algunos las consideran un escalón superior de los sistemas clave-valor ya que permiten encapsular los pares de clave-valor en estructuras más complejas para realizar consultas avanzadas.
- Orientadas a columnas: BigTable, Cassandra, HBase. En lugar de almacenar los datos en filas como lo hacen las bases de datos relacionales, lo hacen en columnas. Estas a su vez se organizan en familias de columnas ordenadas de forma lógica en la base de datos. El sistema está optimizado para trabajar con grandes conjuntos de datos y cargas de trabajo distribuidas.
- Orientadas a grafos: Neo4J, InfiniteGraph. Guardan los datos como entidades y relaciones entre entidades. Las entidades se llaman “nodos” y las relaciones que unen los nodos son los “bordes”. Son ideales para gestionar datos con relaciones complejas, como redes sociales o aplicaciones con ubicación geoespacial.
Almacenamiento y particionado de datos en NoSQL
En lugar de emplear una arquitectura monolítica y costosa donde todos los datos se almacenan en un único servidor, NoSQL distribuye la información en diferentes servidores conocidos como “nodos” que se unen en una red llamada “clúster”.
Esta característica permite a los SGBD NoSQL escalar horizontalmente y gestionar grandes volúmenes de datos mediante técnicas de particionado.
¿Qué es el particionado en bases de datos NoSQL?
Es un proceso que consiste en dividir una base de datos de gran tamaño en fragmentos más pequeños y fáciles de administrar.
Es necesario aclarar que el particionado de datos no es exclusivo de NoSQL. Las bases de datos SQL también soportan particionado, pero los sistemas NoSQL poseen una función nativa llamada “auto-sharding” que divide los datos de manera automática, balanceando la carga entre los servidores.
¿Cuándo particionar una base de datos NoSQL?
Existen varias situaciones en las que es necesario particionar una BBDD NoSQL:
- Cuando el servidor está al límite de su capacidad de almacenamiento o memoria RAM.
- Cuando necesitamos reducir la latencia. En este caso balanceamos la carga de trabajo en diferentes nodos del clúster para mejorar el rendimiento.
- Cuando queremos asegurar la disponibilidad de los datos iniciando un procedimiento de replicado.
Aunque el particionado se utiliza en BBDD de gran tamaño, no debemos esperar a que el volumen de datos sea excesivo porque en este caso podría provocar la sobrecarga del sistema.
Muchos programadores utilizan AWS o Azure para simplificar el proceso. Estas plataformas ofrecen una gran variedad de servicios en la nube que permiten a los desarrolladores despreocuparse de las tareas relacionadas con la administración de las bases de datos y centrarse en escribir el código de sus aplicaciones.
Técnicas de particionado
Existen diferentes técnicas para realizar el particionado de una base de datos de arquitectura distribuida.
- Clustering
Consiste en agrupar varios servidores para que trabajen juntos como si fueran uno solo. En un entorno de clustering todos los nodos del clúster comparten la carga de trabajo para aumentar la capacidad de procesamiento del sistema y la tolerancia a fallos. - Separación de lecturas y escrituras
Consiste en dirigir las operaciones de lectura y escritura a diferentes nodos del clúster. Por ejemplo, las operaciones de lectura se pueden dirigir a servidores de réplica que ejercen de esclavos para aliviar la carga del nodo principal. - Sharding
Los datos se dividen horizontalmente en fragmentos más pequeños llamados “shards” y se distribuyen en diferentes nodos del clúster.
Es la técnica de particionado más utilizada en bases de datos con arquitectura distribuida por su escalabilidad y capacidad de autobalancear la carga del sistema, evitando cuellos de botella. - Consistent Hashing
Es un algoritmo que se utiliza para asignar de manera eficiente datos a nodos en un entorno distribuido.
La idea de los hashes consistentes fue introducida por David Karger en un artículo de investigación publicado en 1997 y titulado “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web«.
En este trabajo académico se propuso por primera vez el algoritmo “Consistent Hashing” como una solución para balancear la carga de trabajo de los servidores con bases de datos distribuidas.
Es una técnica que se utiliza tanto en el particionado como en la replicación de datos ya que permite solucionar problemas comunes a ambos procesos como la redistribución de claves y de recursos cuando se añaden o se eliminan nodos en un clúster.
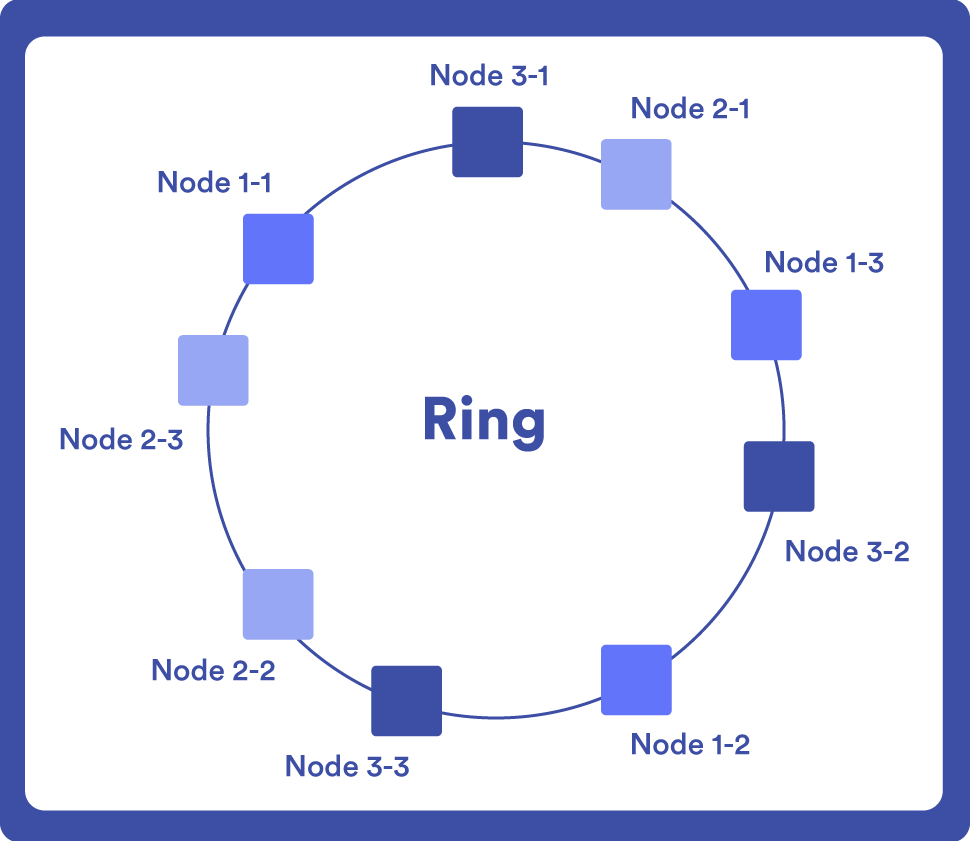
Los nodos se representan en un anillo circular y cada dato se asigna a un nodo mediante una función de hash. Cuando se añade un nuevo nodo al sistema, los datos se redistribuyen entre los nodos existentes y el nuevo nodo.
El hash funciona como un identificador único de manera que al realizar una consulta, sólo hay que ubicar ese punto sobre el anillo.
Un ejemplo de base de datos NoSQL que utiliza “Consistent Hashing” es DynamoDB, ya que uno de sus puntos fuertes es el escalado incremental, y para conseguirlo necesita un procedimiento capaz de fraccionar los datos de manera dinámica.
Replicado en bases de datos NoSQL
Consiste en crear copias de los datos en múltiples máquinas. Este proceso busca mejorar el rendimiento de las BBDD, distribuyendo las consultas entre diferentes nodos. Al mismo tiempo, garantiza que la información seguirá estando disponible, aunque se produzca un fallo en el hardware.
Las dos formas principales de realizar el replicado de datos (además del Consistent Hashing que ya mencionamos en el apartado anterior) son:
Servidor maestro-esclavo
La escritura se realiza en el nodo principal y desde él se replican los datos a los nodos secundarios.
Peer to peer
Todos los nodos del clúster tienen el mismo nivel jerárquico y pueden aceptar escrituras. Cuando los datos se escriben en un nodo se propagan a todos los demás. Esto garantiza la disponibilidad, pero puede provocar también inconsistencias si no se implementan mecanismos de resolución de conflictos (por ejemplo, si dos nodos intentan escribir a la vez en la misma ubicación).

Teorema de CAP y consistencia de las bases de datos NoSQL
El teorema CAP fue presentado por el profesor Eric Brewer de la Universidad de Berkeley en el año 2.000. Nos explica que una base de datos distribuida puede cumplir a la vez con dos de estas tres cualidades:
- Consistencia: Todas las peticiones posteriores a la operación de escritura obtienen el mismo valor, independientemente de dónde se realicen las consultas.
- Disponibilidad: La base de datos siempre responde a las solicitudes, incluso si se produce un fallo.
- Tolerancia a particiones: El sistema sigue funcionando aunque se interrumpa la comunicación entre algunos nodos.

Según este esquema podríamos elegir un SGBD que sea consistente y tolerante a particiones (MongoDB, HBase), disponible y tolerante a particiones (DynamoDB, Cassandra) o consistente y disponible (MySQL), pero no puede mantener las tres características a la vez.
Cada desarrollo tiene sus requerimientos y el teorema CAP nos ayuda a encontrar el SGBD que mejor se ajusta a sus necesidades. A veces es imprescindible que los datos sean consistentes en todo momento (por ejemplo, en un sistema de control de stock). En estos casos solemos trabajar con una base de datos relacional. En las bases de datos NoSQL la consistencia no está cien por cien garantizada, ya que los cambios deben propagarse entre todos los nodos del clúster.
BASE y el modelo de consistencia eventual en NoSQL
BASE es un concepto enfrentado a las propiedades ACID (atomicidad, consistencia, aislamiento, durabilidad) de las bases de datos relacionales. En este enfoque priorizamos la disponibilidad de los datos por encima de la consistencia inmediata, algo que es especialmente importante en las aplicaciones que procesan datos en tiempo real.
El acrónimo BASE significa:
- Basically Available: La base de datos envía siempre una respuesta, aunque contenga errores si se producen lecturas desde nodos que aún no han recibido la última escritura.
- Soft state: La base de datos puede estar en un estado inconsistente cuando se produce la lectura, así que es posible que obtengamos resultados dispares en diferentes lecturas.
- Eventually Consistent: La consistencia en la base de datos se alcanza una vez que la información se ha propagado a todos los nodos. Hasta ese momento hablamos de una consistencia eventual.
A pesar de que el enfoque BASE surgió en respuesta a ACID, no son opciones excluyentes. De hecho, algunas bases de datos NoSQL como MongoDB ofrecen una consistencia configurable.
Indexación de árboles en bases de datos NoSQL. ¿Cuáles son las estructuras más conocidas?
Hasta el momento hemos visto cómo se distribuyen y se replican los datos en una BBDD NoSQL, pero nos falta explicar cómo se estructuran de manera eficiente para facilitar su búsqueda y recuperación.
Los árboles son las estructuras de datos más utilizadas. Organizan los nodos de forma jerárquica partiendo de un nodo raíz que es el primer nodo del árbol, nodos padre que son todos aquellos nodos que tienen al menos un hijo, y nodos hijo que completan el árbol.
El número de niveles de un árbol determina su altura. Es importante tener en cuenta el tamaño final del árbol y el número de nodos que contiene, ya que esto puede influir en el rendimiento de las consultas y el tiempo de recuperación de los datos.
Existen diferentes índices de árboles que podemos emplear en bases de datos NoSQL.
Árboles B
Son árboles balanceados e ideales para sistemas distribuidos por su capacidad para mantener la coherencia de los índices, aunque también se pueden utilizar en bases de datos relacionales.
La característica principal de los árboles B es que pueden tener varios nodos hijos por cada nodo padre, pero siempre mantienen balanceada su altura. Esto quiere decir que poseen un número de niveles idéntico o muy similar en cada rama del árbol, una particularidad que hace posible manejar inserciones y eliminaciones de manera eficiente.
Se utilizan mucho en sistemas de archivo donde es necesario acceder con rapidez a grandes conjuntos de datos.
Árboles T
También son árboles balanceados que pueden tener como máximo dos o tres nodos hijos.
A diferencia de los árboles B que están diseñados para facilitar las búsquedas en grandes volúmenes de datos, los árboles T funcionan mejor en aplicaciones donde se necesita acceso rápido a datos ordenados.
Árboles AVL
Son árboles binarios, lo que significa que cada nodo padre puede tener como máximo dos nodos hijos.
Otra característica destacada de los árboles AVL es que están equilibrados en altura. El sistema de autobalanceo sirve para garantizar que el árbol no crezca de manera descontrolada, algo que podría perjudicar el rendimiento de la base de datos.
Son una buena elección para desarrollar aplicaciones que requieren consultas rápidas y operaciones de inserción y eliminación en tiempo logarítmico.
Árboles KD
Son árboles binarios y balanceados que organizan los datos en múltiples dimensiones. En cada nivel del árbol se crea una dimensión específica.
Se utilizan en aplicaciones que trabajan con datos geoespaciales o datos científicos.
Árboles Merkle
Representan un caso especial de estructuras de datos en sistemas distribuidos. Son conocidos por su utilidad en Blockchain para cifrar datos de manera eficiente y segura.
Un árbol Merkle es un tipo de árbol binario que ofrece una solución de primer nivel al problema de la verificación de los datos. Su creador fue un informático y criptógrafo estadounidense llamado Ralph Merkle en 1979.
Los árboles Merkle tienen una estructura matemática formada por hashes de varios bloques de datos que resumen todas las transacciones en un bloque.

Los datos se van agrupando en conjuntos de datos más grandes y se relacionan con los nodos principales hasta reunir todos los datos dentro del sistema. Como resultado, se obtiene la raíz Merkle (Merkle Root).
¿Cómo se calcula la raíz Merkle?
1. Los datos se dividen en bloques de un tamaño fijo.
2. Cada bloque de datos se somete a una función hash criptográfica.
3. Los hashes se agrupan en pares y a estos pares se les aplica nuevamente una función para generar sus respectivos hashes padres hasta que solamente queda un hash que es la raíz Merkle.
La raíz Merkle está en la cima del árbol y es el valor que representa de forma segura la integridad de los datos. Esto se debe a que está determinadamente relacionada con todos los conjuntos de datos y el hash que identifica a cada uno de ellos. Cualquier cambio en los datos originales alterará la raíz Merkle. De esta forma, podemos tener la certeza de que los datos no han sido modificados en ningún punto.
Esta es la razón por la que los árboles Merkle se emplean con frecuencia para verificar la integridad de los bloques de datos en transacciones de Blockchain.
Bases de datos NoSQL como Cassandra recurren a estas estructuras para validar los datos sin sacrificar velocidad y rendimiento.
Comparación entre sistemas de gestión de bases de datos NoSQL
Por lo que hemos podido ver hasta ahora, los SGBD NoSQL son extraordinariamente complejos y variados. Cada uno de ellos puede adoptar un modelo de datos diferente y presentar características únicas de almacenamiento, consulta y escalabilidad. Este abanico de opciones permite a los desarrolladores seleccionar la base de datos más adecuada para las necesidades de su proyecto.
A continuación, pondremos como ejemplo dos de los SGBD NoSQL más usados en la actualidad para el desarrollo de aplicaciones escalables y de alto rendimiento: MongoDB y Apache Cassandra.
MongoDB
Es un SGBD de tipo documental desarrollado por 10gen en 2007. Es de código abierto y ha sido creado en lenguajes de programación como C++ C y JavaScript.

MongoDB es uno de los sistemas más populares para bases de datos distribuidas. Redes sociales como LinkedIn, empresas de telecomunicaciones como Telefónica o medios informativos como Washington Post utilizan MongoDB.
Veamos algunas de sus características principales.
- Almacenamiento en BBDD con MongoDB: MongoDB almacena los datos en documentos BSON (JSON binario). Cada base de datos se compone de una colección de documentos. Una vez que MongoDB está instalado y la Shell está en ejecución, podemos crear la BBDD simplemente indicando el nombre que queremos usar. Si la BBDD aún no existe, MongoDB la creará automáticamente al añadir la primera colección. De manera similar, una colección se crea automáticamente al almacenar un documento en ella. Sólo tenemos que agregar el primer documento y ejecutar la sentencia “insert” y MongoDB creará un campo ID asignándole un valor del tipo ObjectID que es único para cada máquina en el momento en el que se ejecuta la operación.
- Particionado en BBDD con MongoDB: MongoDB facilita la distribución de datos en múltiples servidores utilizando la función de sharding automático. La fragmentación de los datos se produce a nivel de colección, distribuyendo los documentos entre los distintos nodos del clúster. Para efectuar esta distribución se emplea una “clave de partición” definida como campo en todos los documentos de la colección. Los datos se fragmentan en “chunks” que tienen por defecto un tamaño de 64 MB y se almacenan en diferentes shards dentro del clúster, procurando que exista un equilibrio. MongoBD monitoriza continuamente la distribución de los chunks entre los nodos del shard y si fuera necesario, efectúa un rebalanceo automático para asegurarse de que la carga de trabajo que soportan los nodos esté equilibrada.
- Replicado en BBDD con MongoDB: MongoDB utiliza un sistema de replicación basado en la arquitectura maestro-esclavo. El servidor maestro puede realizar operaciones de escritura y lectura, pero los nodos esclavos únicamente realizan lecturas (replica set). Las actualizaciones se comunican a los nodos esclavos mediante un log de operación llamado oplog.
- Consultas en BBDD con MongoDB: MongoDB cuenta con una potente API que permite acceder y analizar los datos en tiempo real, así como realizar consultas ad-hoc, es decir, consultas directas sobre una base de datos que no están predefinidas. Esto proporciona a los usuarios la posibilidad de realizar búsquedas personalizadas, filtrar documentos y ordenar los resultados por campos específicos. Para llevar a cabo estas consultas, MongoDB emplea el método “find” sobre la colección deseada o “findAndModify” para consultar y actualizar los valores de uno o más campos simultáneamente.
- Indexación en BBDD con MongoDB: MongoDB utiliza árboles B+ para indexar los datos almacenados en sus colecciones. Se trata de una variante de los árboles B con nodos de índice que contienen claves y punteros a otros nodos. Estos índices almacenan el valor de un campo específico, permitiendo que las operaciones de recuperación y eliminación de datos sean más eficientes.
- Coherencia en BBDD con MongoDB: A partir de la versión 4.0 (la más reciente es la 6.0), MongoDB soporta transacciones ACID a nivel de documento. La función “snapshot isolation” ofrece una visión coherente de los datos y permite realizar operaciones atómicas en múltiples documentos dentro de una sola transacción. Esta característica es especialmente relevante para las bases de datos NoSQL, ya que plantea soluciones a diferentes problemas relacionados con la consistencia, como escrituras concurrentes o consultas que devuelven versiones obsoletas de un documento. En este aspecto, MongoDB se acerca mucho a la estabilidad de los RDMS.
- Seguridad en BBDD con MongoDB: MongoDB tiene un nivel de seguridad alto para garantizar la confidencialidad de los datos almacenados. Cuenta con varios mecanismos de autenticación, configuración de accesos basada en roles, cifrado de datos en reposo y posibilidad de restringir el acceso a determinadas direcciones IP. Además, permite auditar la actividad del sistema y llevar un registro de las operaciones realizadas en la base de datos.
Apache Cassandra
Es un SGBD orientado a columnas que fue desarrollado por Facebook para optimizar las búsquedas dentro de su plataforma. Uno de los creadores de Cassandra es el informático Avinash Lakshman que trabajó anteriormente con Amazon, formando parte del grupo de ingenieros que desarrolló DynamoDB. Por este motivo, no es extraño que comparta algunas características con este otro sistema.
En el año 2008 fue lanzado como proyecto open source y en 2010 se convirtió en un proyecto top-level de la Fundación Apache. Desde entonces Cassandra continuó creciendo hasta ser uno de los SGBD NoSQL más populares.
Aunque a día de hoy Meta utiliza otras tecnologías, Cassandra sigue formando parte de su infraestructura de datos. Otras empresas que lo utilizan son Netflix, Apple o Ebay. En términos de escalabilidad está considerada como una de las mejores bases de datos NoSQL.

Veamos algunas de sus características más destacadas:
- Almacenamiento en BBDD con Apache Cassandra: Cassandra utiliza un modelo de datos tipo “Column Family”, que es similar a las bases de datos relacionales, pero más flexible. No se refiere a una estructura jerárquica de columnas que contengan otras columnas, sino más bien a una colección de pares clave-valor, donde la clave identifica una fila y el valor es un conjunto de columnas. Es un diseño pensado para almacenar grandes cantidades de datos y realizar operaciones de escritura y lectura más eficientes.
- Particionado en BBDD con Apache Cassandra: Para la distribución de datos Cassandra utiliza un particionador que reparte los datos en diferentes nodos del clúster. Este particionador usa el algoritmo “consistent hashing” para asignar una clave de partición única a cada fila de datos. Los datos que poseen la misma clave de partición estarán juntos en los mismos nodos. También admite nodos virtuales (vnodes), lo que significa que un mismo nodo físico puede tener varios rangos de datos.
- Replicado en BBDD con Apache Cassandra: Cassandra propone un modelo de replicado basado en Peer to peer en el que todos los nodos del clúster aceptan lecturas y escrituras. Al no depender de un nodo maestro para procesar las solicitudes, la posibilidad de que se produzca un cuello de botella es mínima. Los nodos se comunican entre sí y comparten datos utilizando un protocolo de gossiping.
- Consultas en BBDD con Apache Cassandra: Al igual que MongoDB, Cassandra también admite consultas ad-hoc, pero estas tienden a ser más eficientes si están basadas en la clave primaria. Además, dispone de su propio lenguaje de consulta llamado CQL (Cassandra Query Language) con una sintaxis similar a SQL, pero que en lugar de utilizar joins apuesta por la desnormalización de los datos.
- Indexación en BBDD con Apache Cassandra: Cassandra utiliza índices secundarios para permitir consultas eficientes sobre columnas que no forman parte de la clave primaria. Estos índices pueden afectar a columnas individuales o a varias columnas (SSTable Attached Secondary Index). Se crean para permitir consultas complejas de rango, prefijo o búsqueda de texto en un gran número de columnas.
- Coherencia en BBDD con Apache Cassandra: Al utilizar una arquitectura Peer to Peer Cassandra juega con la consistencia eventual. Los datos se propagan de forma asíncrona en múltiples nodos. Esto quiere decir que durante un breve periodo de tiempo puede haber discrepancias entre las diferentes réplicas. Sin embargo, Cassandra proporciona también mecanismos para configurar el nivel de consistencia. Cuando se produce un conflicto (por ejemplo, si las réplicas tienen versiones diferentes), utiliza la marca de tiempo (timestamp) y da por válida la versión más reciente. Además, realiza reparaciones automáticas para mantener la coherencia y la integridad de los datos si se presentan fallos de hardware u otros eventos que causan discrepancias entre las réplicas.
- Seguridad en BBDD con Apache Cassandra: Para utilizar Cassandra en un entorno seguro es necesario realizar configuraciones, ya que muchas opciones no están habilitadas por defecto. Por ejemplo, debemos activar el sistema de autenticación y establecer permisos para cada rol de usuario. Además, es fundamental encriptar los datos en tránsito y en reposo. Para la comunicación entre los nodos y el cliente se pueden cifrar los datos en tránsito utilizando SSL/TLS.
Desafíos en la administración de las bases de datos NoSQL ¿Cómo ayuda Pandora FMS?
Los SGBD NoSQL ofrecen a los desarrolladores la posibilidad de gestionar grandes volúmenes de datos y de escalar horizontalmente añadiendo múltiples nodos a un clúster.
Para administrar estas infraestructuras distribuidas es necesario dominar diferentes técnicas de particionado y replicación de los datos (por ejemplo, hemos visto que MongoDB utiliza una arquitectura maestro-esclavo, mientras que Cassandra prioriza la disponibilidad con el modelo Peer to peer).
A diferencia de lo que ocurre con los RDMS que comparten muchas similitudes, en las bases de datos NoSQL no hay un paradigma común y cada sistema tiene sus propias APIs, lenguajes y una implementación diferente, por lo que acostumbrarse a trabajar con cada uno de ellos puede significar un auténtico desafío.
Teniendo en cuenta que la monitorización es un componente fundamental para la administración de cualquier base de datos, debemos ser pragmáticos y apoyarnos en aquellos recursos que nos hacen la vida más fácil.
Tanto MongoDB como Apache Cassandra disponen de comandos que devuelven información sobre el estado del sistema y permiten diagnosticar problemas antes de que se conviertan en fallos críticos. Otra posibilidad es utilizar el software de Pandora FMS para simplificar todo el proceso.
¿Cómo hacerlo?
Si se trata de una base de datos en MongoDB, tenemos que descargar el plugin de Pandora FMS para MongoDB. Este plugin utiliza el comando mongostat para recopilar información básica sobre el rendimiento del sistema. Una vez obtenidas las métricas relevantes, estas son enviadas al servidor de datos de Pandora FMS para su análisis.
En cambio, si la base de datos funciona con Apache Cassandra, debemos descargar el plugin correspondiente a este sistema. Este plugin obtiene la información ejecutando internamente la herramienta nodetool, que ya está incluida en la instalación estándar de Cassandra y ofrece una amplia gama de comandos para monitorizar el estado de los servidores. Una vez que se analizan los resultados, el plugin estructura los datos en formato XML y los envía al servidor de Pandora FMS para su posterior análisis y visualización.
Para que estos plugins funcionen correctamente, hay que copiar los ficheros en el directorio de plugins del agente de Pandora FMS, editar el archivo de configuración y, por último, reiniciar el sistema (en los artículos enlazados se explica muy bien el procedimiento).
Una vez que los plugins estén activos, podremos monitorear la actividad de los nodos del clúster en una vista de gráficos y recibir alertas si se produce algún fallo. Estas y otras opciones de automatización nos ayudan a ahorrar bastante tiempo y recursos en el mantenimiento de las bases de datos NoSQL.
¡Crea una cuenta gratuita y descubre todas las utilidades de Pandora FMS para impulsar tu proyecto digital!
Y si tienes dudas sobre la diferencia entre NoSQL y SQL puedes consultar nuestro post «NoSQL vs SQL: principales diferencias y cuándo elegir cada una de ellas«.

Estudié Filología, pero las circunstancias de la vida me llevaron a trabajar en el sector del Marketing como redactora de contenidos. Me apasiona el mundo del blogging y la oportunidad de aprender que se presenta con cada proyecto nuevo. Te invito a seguir mis publicaciones en el blog de Pandora FMS para descubrir las tendencias tecnológicas que están transformando el mundo de los negocios.






