









Grupo de bases de datos de alta disponibilidad con Pandora FMS
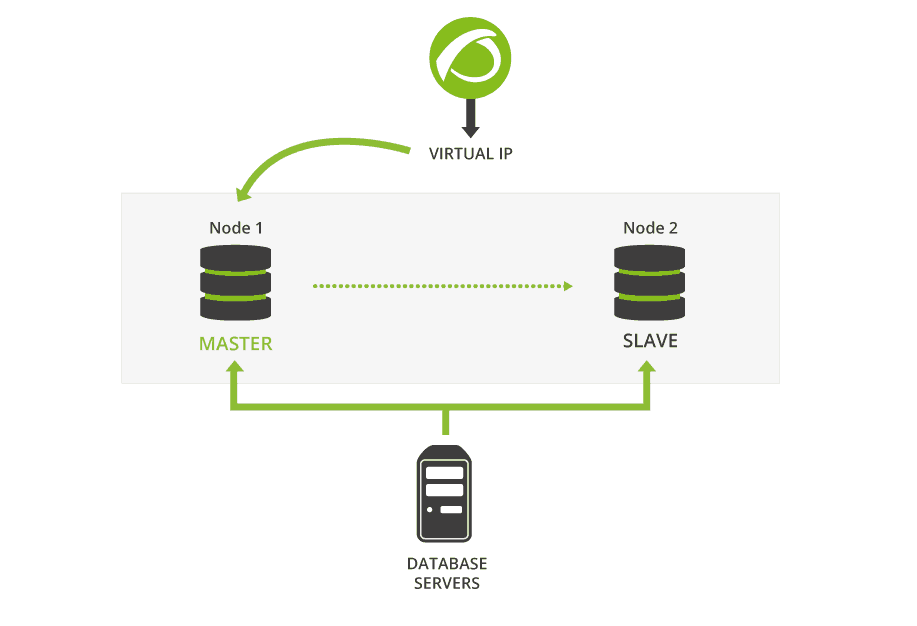
Pandora FMS se basa fundamentalmente en una base de datos MySQL para configurar y almacenar datos. Un fallo en la base de datos puede paralizar inmediatamente el software de monitorización. El cluster de la base de datos de alta disponibilidad de Pandora FMS nos posibilita desplegar fácilmente una arquitectura robusta y tolerante a los fallos.
Los recursos de cluster se gestionan con Pacemaker, un gestor de recursos de HA (del inglés, high availability) cluster avanzado y escalable. Corosync proporciona un modelo de comunicación de grupo de proceso cerrado para generar máquinas de estado replicadas. Percona, un reemplazo compatible con versiones anteriores de MySQL, se eligió como RDBMS por defecto por su escalabilidad, disponibilidad, seguridad y características de backup.
La replicación activa / pasiva se desarrolla desde un nodo maestro único (con permiso de escritura) a cualquier número de esclavos (solo lectura). Una dirección IP virtual siempre lleva al maestro actual. Si falla el nodo maestro, uno de los esclavos asciende a un maestro y se actualiza la dirección IP virtual en consecuencia.
La herramienta de base de datos de alta disponibilidad de Pandora FMS, pandora_ha, monitoriza el clúster y se asegura que el servidor de Pandora FMS está en continuo funcionamiento, reiniciándolo en caso necesario. pandora_ha se monitoriza a su vez con systemd .
Requisitos previos e instalación
En este artículo configuraremos y probaremos un grupo de nodos con Pandora FMS. Necesitaremos tener instalada la versión Enterprise de Pandora FMS y los hosts adicionales que se ejecutan en la versión 7 de CentOS.
Para configurar el clúster se puede consultar la guía de instalación oficial de Pandora FMS sobre los clústeres de bases de datos de alta disponibilidad. Aunque esta guía sea sencilla, con explicaciones paso a paso, es recomendable tener algo de experiencia con la línea de comandos de Linux.
Al terminar nos damos cuenta de cualquiera de los dos nodos y ejecutamos el estado de pcs para el estado del cluster. Ambos nodos deben estar en línea:
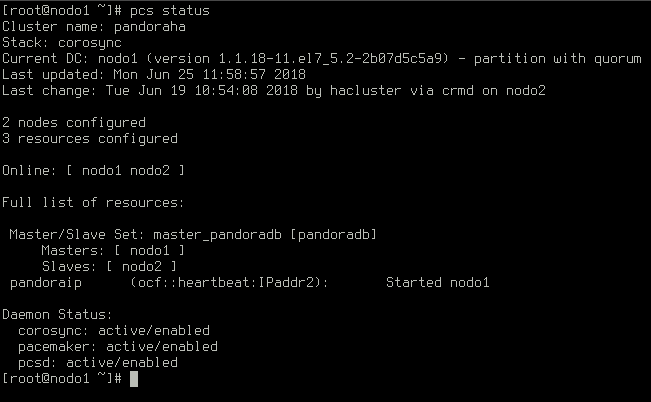
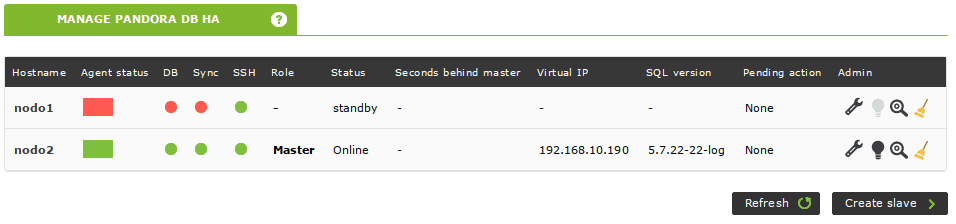
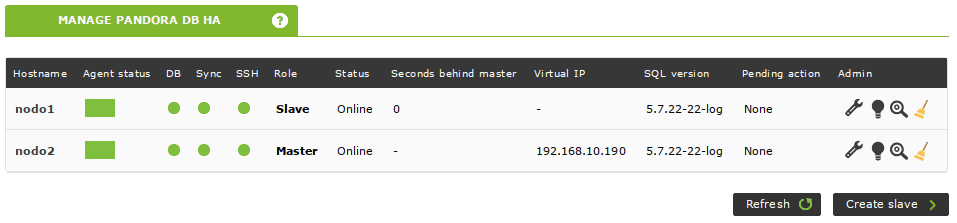
El cluster está activo y funciona. También puedes comprobar su estado desde la consola de Pandora FMS. Simplemente ve a Servers -> Manage database HA (consejo: si hacemos clic en el icono de la lupa podremos ver la salida de los estados de pcs sin tener que realizar un ssh a ese nodo):
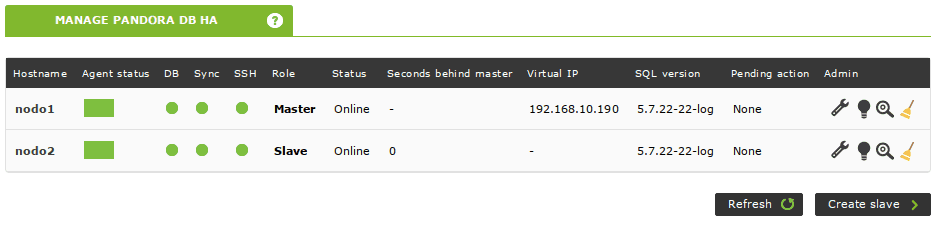
La herramienta de base de datos de alta disponibilidad de Pandora FMS crea agentes automáticamente para monitorizar un cluster. Se puede acceder a ellos desde la vista anterior, haciendo clic en el nombre del nodo que aparece en la columna Hostname:
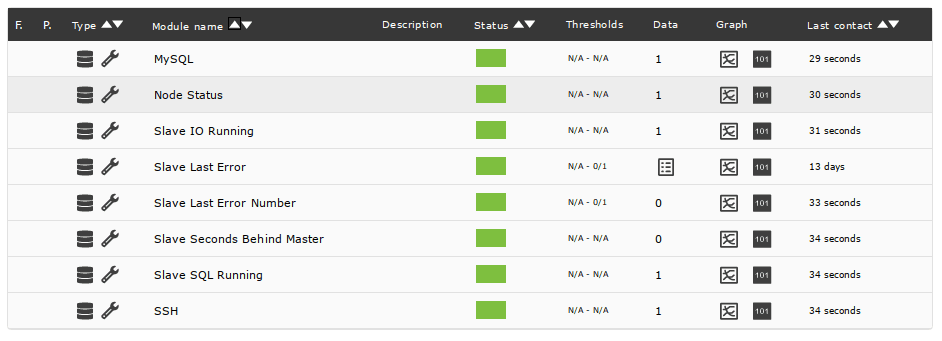
Es conveniente configurar alertas para, por lo menos, los módulos Node Status, Slave IO Running y Slave SQL Running. Estos módulos cambian a estado crítico cuando ocurre un problema, por lo que se puede utilizar el modelo de alertas Critical condition por defecto de Pandora FMS:
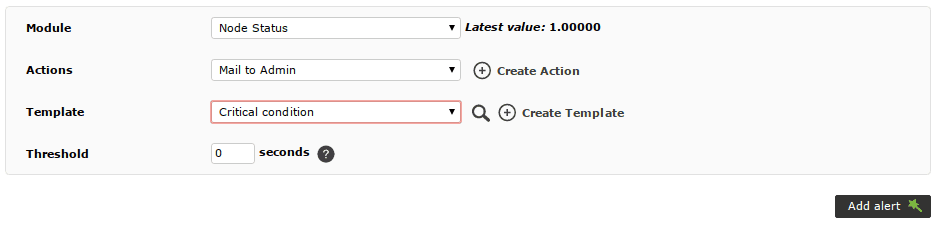
Funcionamiento del cluster
Veamos qué ocurre cuando algo va mal. En esta sección probaremos el comportamiento de nuestro cluster de base de datos de alta disponibilidad en diferentes situaciones.
Conmutación por error manual
Quizá necesitemos interrumpir uno de los nodos para realizar un mantenimiento, por ejemplo. En vez de parar un esclavo, detengamos el maestro:
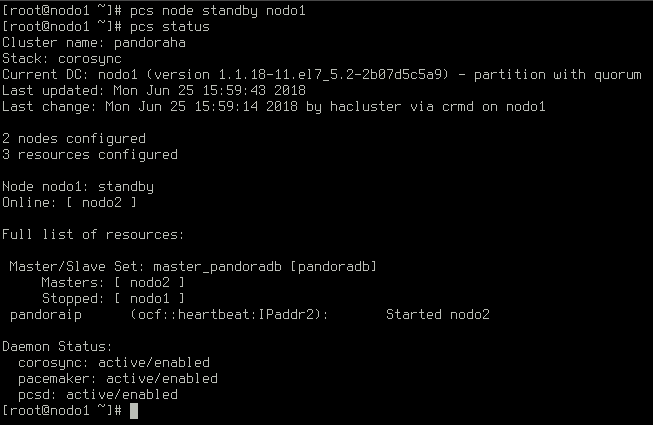
El maestro anterior está en standby y el esclavo ha ascendido a maestro:
Lo volvemos a conectar:
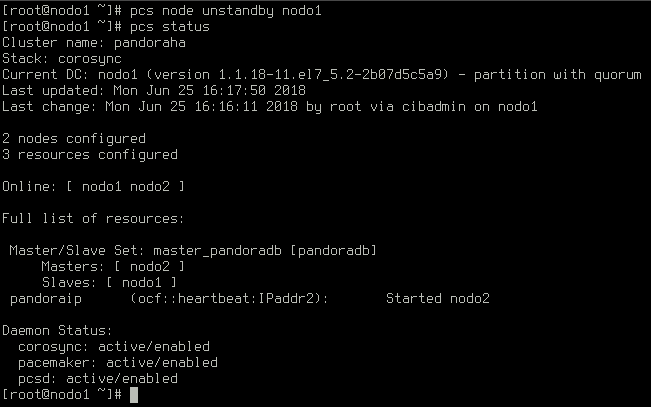
El maestro anterior está conectado y ahora es un esclavo. El nuevo maestro no renunciará a su función a no ser que falle.
Nuestro servidor de Pandora FMS funciona correctamente:

Caída del maestro
Si el proceso del servidor de la base de datos falla, se reiniciará automáticamente:
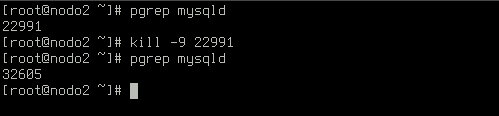
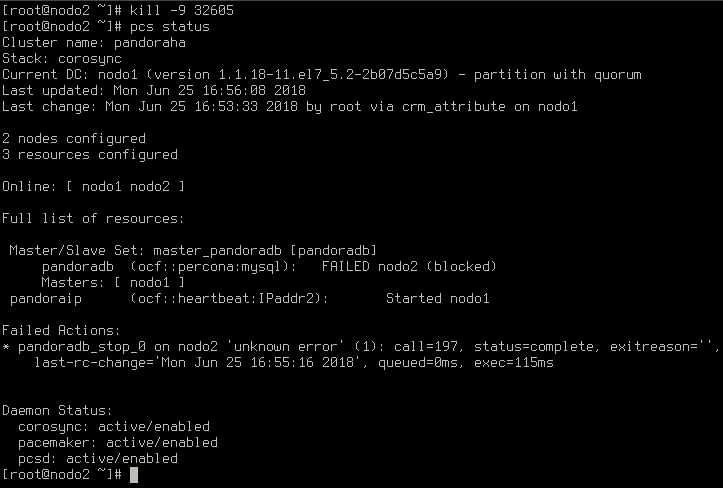
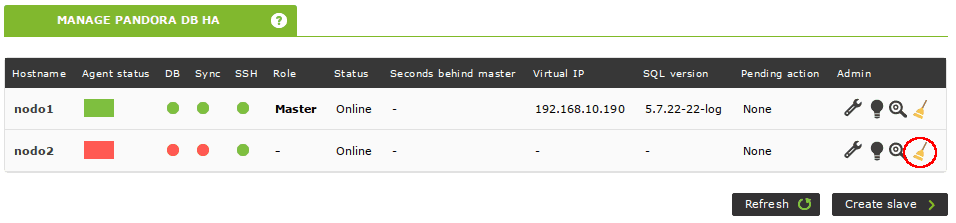
Sin embargo, si hay más de una caída en un lapso de una hora, el nodo quedará bloqueado y un esclavo ascenderá a maestro:
Cuando el problema se haya solucionado, hacemos clic en el icono de escoba para recuperar el nodo bloqueado.
Parada o reinicio de un nodo
Una parada o reinicio de cualquier nodo dejará el cluster con un maestro y la operación no se verá afectada:

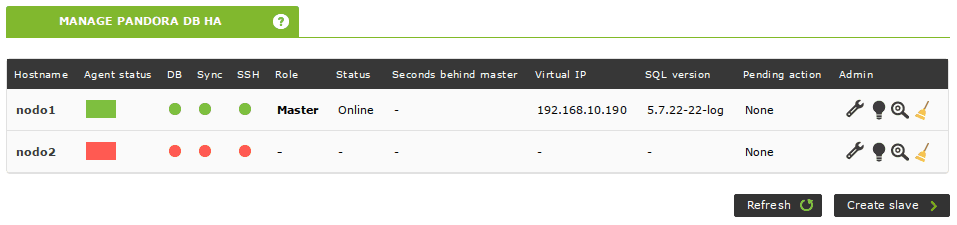
Si seconds behind master es superior a 0 al volver a conectar el nodo, entonces el esclavo aún no ha replicado todas las transacciones que ocurrieron en el maestro. Este valor debería disminuir paulatinamente hasta llegar a 0:
Replicación rota
Cuando el maestro no está en sincronía con el esclavo (es decir, cuando el maestro está por delante del esclavo) y falla, puede que no sea capaz de iniciar la replicación a partir del nuevo maestro hasta que se vuelva a conectar:
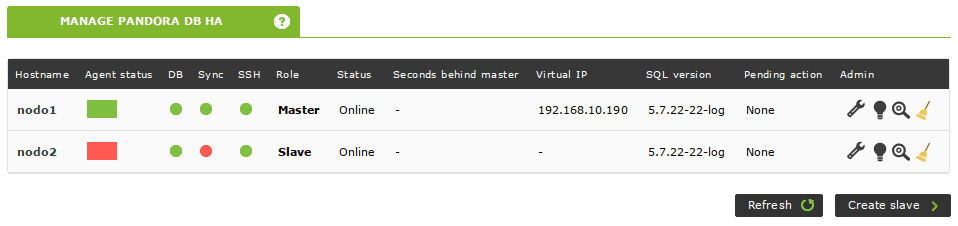
Algunos de los cambios no replicados por el esclavo anterior podrían entrar en conflicto con los nuevos cambios que se necesitan replicar:
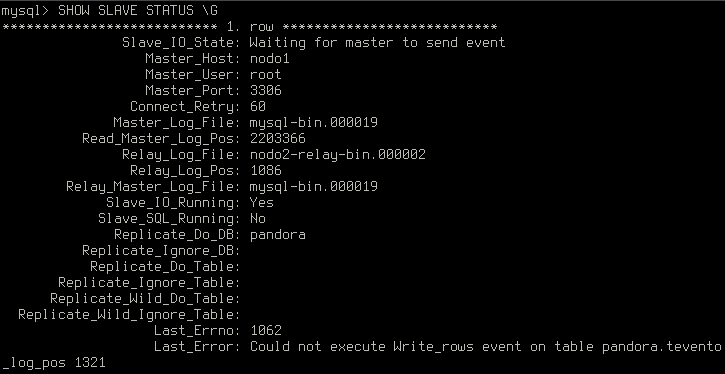
La manera más fácil de reparar un nodo roto es seguir las instrucciones en la sección reparación de un nodo roto de la guía de instalación del cluster de base de datos de alta disponibilidad de Pandora FMS, lo que conlleva la reconstrucción de una base de datos del nodo a partir del maestro y el reinicio de la replicación.
Añadir nodos adicionales
Aunque no tratemos este tema en el presente artículo, es posible añadir nodos adicionales al cluster para aumentar su resiliencia. Para más información, se puede consultar la guía de instalación de cluster de base de datos de alta disponibilidad de Pandora FMS.
Conclusión
Cuando se utiliza el grupo de datos de alta disponibilidad de Pandora FMS, el servidor de Pandora FMS no detecta los fallos en los nodos esclavos. Sin embargo, es conveniente intervenir rápidamente antes de que caigan otros nodos.
Un fallo en el nodo maestro provocará una breve interrupción hasta que uno de los esclavos ascienda a maestro. Tras esta parada, se recuperará la operación normal automáticamente.
¡Nunca volverá a caer nuestra infraestructura de monitorización por un fallo en la base de datos!
Puede ver la demostración de cómo funciona la base de datos de alta disponibilidad en Pandora FMS aquí:

El equipo de redacción de Pandora FMS está formado por un conjunto de escritores y profesionales de las TI con una cosa en común: su pasión por la monitorización de sistemas informáticos. Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring.






