









L’infrastructure doit être « invisible » pour l’utilisateur, mais visible pour les stratèges informatiques afin d’assurer la performance et les niveaux de service requis par l’entreprise, où l’observabilité (dans le cadre de SRE ou de l’ingénierie de fiabilité du site) est essentielle pour comprendre l’état interne d’un système en fonction de ses résultats externes. Pour obtenir une observabilité efficace, il existe quatre piliers clés : les métriques, les événements, les journaux et les traces (de suivi), qui sont résumés dans l’acronyme MELT
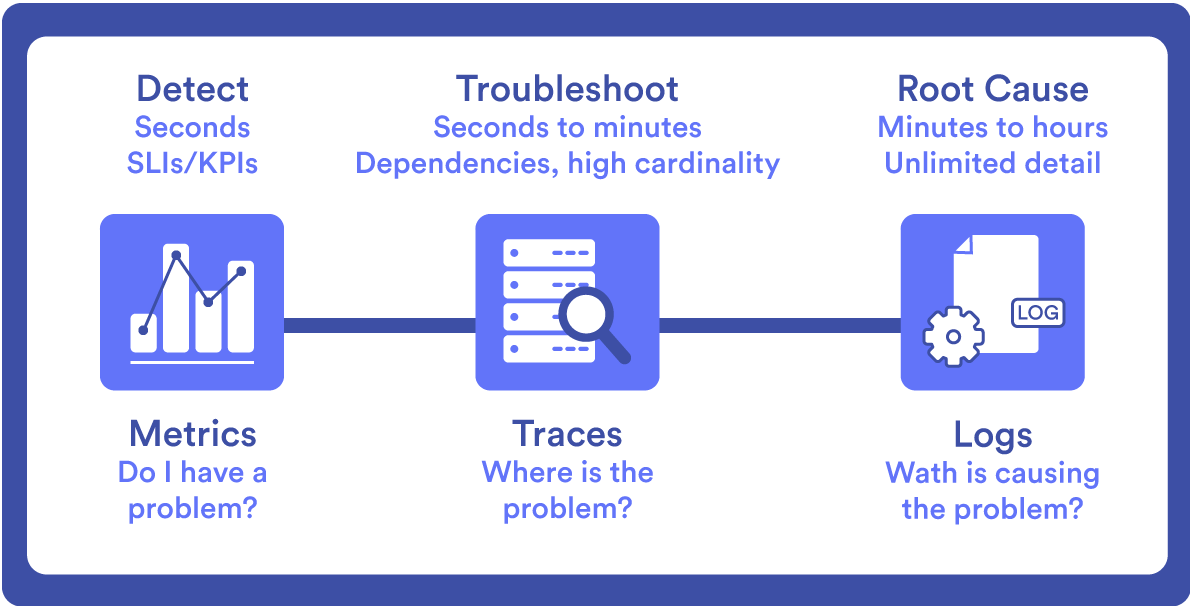
Ensuite, nous définirons chacun de ces piliers.
Métriques
Que sont les métriques ?
Ce sont des mesures numériques, généralement périodiques, qui fournissent des informations sur l’état d’un système et les performances.
Exemples de métriques utiles
Temps de réponse, taux d’erreur, utilisation de l’UCT, consommation de mémoire et performances du réseau.
Avantages de l’utilisation de métriques
Les métriques permettent aux équipes informatiques et de sécurité de suivre les indicateurs clés de performance (KPI) pour détecter les tendances ou les anomalies dans le comportement du système.
Événements
Que sont les Événements ?
Il s’agit d’événements ou de faits discrets au sein d’un système, qui peuvent aller de la création d’un module à la connexion d’un utilisateur à la console. L’événement décrit le problème, l’origine (agent) et la création.
Exemples d’événements dans les systèmes
Actions des utilisateurs (tentatives de connexion de l’utilisateur), réponses HTTP, modifications de l’état du système ou autres incidents notables.
Comment les événements fournissent le contexte
Les événements sont généralement capturés sous forme de données structurées, y compris des attributs tels que l’horodatage, le type d’événement et les métadonnées associées, ce qui donne plus d’éléments et d’informations à l’équipe informatique pour comprendre le comportement du système et détecter les modèles ou les anomalies.
Logs
Qu’est-ce que les journaux ?
Ce sont des enregistrements détaillés des événements et des actions qui se produisent dans un système. Ces données collectées fournissent également une vue chronologique de l’activité du système, offrant plus d’éléments pour la résolution de problèmes et le débogage, la compréhension du comportement des utilisateurs et le suivi des modifications apportées au système. Les journaux peuvent contenir des informations telles que des messages d’erreur, des suivis de pile, des interactions utilisateur, des notifications de modifications du système.
Formats courants des journaux
Normalement, les logs utilisent des fichiers plats, soit dans des encodages de caractères de type ASCII et sont stockés sous forme de texte. Les formats les plus connus sont Microsoft IIS3.0, NCSA, O’Reilly ou W3SVC. En outre, il existe des formats spéciaux tels que ELF (Extended Log Format) et CLF (Common Log Format).
Importance de la centralisation des journaux
La centralisation des logs assure une vision complète et plus contextualisée du système à tout moment. Cela permet de détecter les problèmes de manière proactive et les problèmes potentiels, ainsi que de prendre des mesures avant qu’ils ne deviennent des problèmes majeurs. Cette centralisation permet également de disposer des éléments essentiels pour les audits et la conformité réglementaire, car la conformité aux politiques et réglementations en matière de sécurité peut être démontrée.
Traces
Que sont les traces ?
Les traces fournissent une vue détaillée du flux de demandes via un système distribué. C’est parce qu’ils saisissent le chemin d’une demande au fur et à mesure qu’elle traverse plusieurs services ou composants, y compris le temps à chaque étape. De cette façon, les traces aident à comprendre les dépendances et les goulots d’étranglement potentiels dans la performance, en particulier dans un système complexe. Les traces permettent également d’analyser comment l’architecture du système peut être optimisée pour améliorer les performances globales et, par conséquent, l’expérience utilisateur final.
Exemples de traces dans les systèmes distribués
- L’intervalle ou span est une opération chronométrée et nommée qui représente une partie du flux de travail. Par exemple, les intervalles peuvent inclure des requêtes de données, des interactions du navigateur, des appels à d’autres services, etc.
- Les transactions peuvent se composer de plusieurs tranches et représentent une demande complète d’un bout à l’autre voyageant à travers plusieurs services dans un système distribué.
- Les identifiants uniques pour chacun, afin de suivre le parcours de la demande à travers différents services. Cela permet de visualiser et d’analyser l’itinéraire et la durée de la demande.
- La propagation du contexte de la trace implique le passage du contexte de la trace entre les services.
- La visualisation de la trace pour afficher le flux de demandes à travers le système, ce qui aide à identifier les défaillances ou les goulots d’étranglement des performances.
De plus, les traces fournissent des données détaillées afin que les développeurs puissent effectuer une analyse des causes profondes et avec ces informations aborder les problèmes liés à la latence, aux erreurs et aux dépendances.
Défis dans l’instrumentation des traces
L’instrumentation des traces peut être difficile essentiellement pour deux raisons :
- Chaque composant d’une demande doit être modifié pour transmettre les données de suivi.
- De nombreuses applications sont basées sur des bibliothèques ou des frameworks utilisant l’open source, de sorte qu’elles peuvent nécessiter une instrumentation supplémentaire.
Implémentation de MELT dans les systèmes distribués
Adopter l’observabilité via MELT implique la télémétrie, c’est-à-dire la collecte et la transmission automatiques de données à partir de sources distantes vers un emplacement centralisé pour la supervision et l’analyse. À partir des données collectées, les principes de la télémétrie (analyser, visualiser et alerter) doivent être appliqués pour construire des systèmes résilients et fiables.
Collecte de données de télémétrie
Les données sont la base de MELT, dans laquelle il existe trois principes fondamentaux de télémétrie :
- Analyser les données collectées permet d’obtenir des informations importantes, en s’appuyant sur des techniques statistiques, des algorithmes d’apprentissage automatique (Machine Learning) et des méthodes d’exploration de données pour identifier les modèles, les anomalies et les corrélations.
En analysant les métriques, les événements, les journaux et les traces, les équipes informatiques peuvent détecter les problèmes de performance, détecter les menaces à la sécurité et comprendre le comportement du système. - Visualiser les données les rend accessibles et compréhensibles pour les parties intéressées. Les techniques de visualisation efficaces sont les panneaux, les tableaux et les graphiques qui représentent les données de manière claire et concise. En une seule vue, vous et votre équipe pouvez superviser l’état du système, identifier les tendances et communiquer efficacement les résultats.
- Alerter est un aspect critique de l’observabilité. Lorsque les alertes sont configurées basées sur des seuils prédéfinis ou des algorithmes de détection d’anomalies, les équipes informatiques peuvent identifier et répondre de manière proactive aux problèmes. Les alertes peuvent être activées en fonction de mesures dépassant certaines limites, d’événements indiquant des défaillances du système ou des modèles spécifiques dans les journaux ou les traces.
Gestion des données agrégées
La mise en œuvre de MELT implique de gérer une grande quantité de données provenant de différentes sources telles que les journaux d’applications, de systèmes, le trafic réseau, les services et l’infrastructure de tiers. Toutes ces données doivent être concentrées en un seul endroit et agrégées de la manière la plus simplifiée pour observer les performances du système, détecter les irrégularités et leur origine, ainsi que reconnaître les problèmes potentiels. Par conséquent, une gestion globale des données basée sur une organisation définie, une capacité de stockage et une analyse appropriée est nécessaire pour obtenir des informations précieuses.
L’agrégation de données est particulièrement utile pour les logs, qui constituent la majeure partie des données de télémétrie collectées. Les journaux peuvent également être ajoutés avec d’autres sources de données pour fournir des informations complémentaires sur les performances de l’application et le comportement de l’utilisateur.
Importance de MELT dans l’observabilité
MELT offre une approche globale de l’observabilité, avec des informations sur l’état, les performances et le comportement du système, à partir desquelles les équipes informatiques peuvent détecter, diagnostiquer et résoudre efficacement les problèmes.
Améliorations de la fiabilité et des performances du système
Adopter l’observabilité soutient les objectifs des SRE :
- Réduire le travail associé à la gestion des incidents, en particulier autour de l’analyse des causes, en améliorant le temps de disponibilité et le temps moyen de réparation/résolution (MTTR).
- Fournir une plate-forme pour superviser et adapter en fonction des objectifs les niveaux de service ou les contrats de niveaux de service et leurs indicateurs (Voir Qu’est-ce que SLA, SLO et SLI ?). Il donne également les éléments pour une solution possible lorsque les objectifs ne sont pas atteints.
- Soulager la charge de l’équipe informatique lorsqu’il s’agit de grandes quantités de données en réduisant l’épuisement ou les alertes excessives. Cela conduit également à stimuler la productivité, l’innovation et la création de valeur.
- Soutenir des équipements multifonctionnels et autonomes. Une meilleure collaboration avec les équipes DevOps est obtenue.
Création d’une culture de l’observabilité
Les métriques sont le point de départ de l’observabilité, il faut donc créer une culture de l’observabilité où la collecte et l’analyse appropriées sont la base d’une prise de décision éclairée et prudente, en plus de fournir les éléments permettant d’anticiper les événements et même de planifier la capacité de l’infrastructure qui prend en charge la numérisation de l’entreprise et la meilleure expérience des utilisateurs finaux.
Outils et techniques pour mettre en œuvre MELT
- Supervision des performances des applications (APM, Application Performance Monitoring): APM est utilisé pour superviser, détecter et diagnostiquer les problèmes de performance dans systèmes distribués. Il fournit une visibilité à l’échelle du système en collectant des données de toutes les applications et en traçant les flux de données entre les composants.
- Analyse AIOps: Ce sont des outils qui utilisent l’intelligence artificielle et le ML pour optimiser les performances du système et reconnaître les problèmes potentiels.
- Analyse automatisée de la cause racine: L’IA identifie automatiquement la cause racine d’un problème, ce qui aide à détecter et à résoudre rapidement les problèmes potentiels et à optimiser les performances du système.
Avantages de la mise en œuvre de MELT
La fiabilité et la performance des systèmes nécessitent une observabilité, qui doit être basée sur la mise en œuvre de MELT, avec des données sur les métriques, les événements, les journaux et les traces. Toutes ces informations doivent être analysées et exploitables pour résoudre les problèmes de manière proactive, optimiser les performances et obtenir une expérience satisfaisante pour les utilisateurs et les clients finaux.
Pandora FMS : Une solution intégrale pour MELT
Pandora FMS est la solution de supervision complète pour une observabilité totale, car sa plate-forme permet de centraliser les données pour obtenir une vision intégrée et contextualisée, avec des informations pour analyser de grands volumes de données provenant de diverses sources. En une seule vue, il est possible de voir l’état et les tendances du comportement des systèmes, en plus de générer des alertes de manière intelligente et efficace. Il génère également des informations qui peuvent être partagées avec des clients ou des fournisseurs pour se conformer aux normes et aux objectifs de service et de performance des systèmes. Pour implémenter MELT :
- Pandora FMS unifie la supervision des services et applications quel que soit le modèle opérationnel et les infrastructures (physique ou SaaS, PaaS ou IaaS).
- Avec Pandora FMS, vous pouvez collecter et stocker tous les types de journaux (y compris les événements Windows) afin de pouvoir rechercher et configurer des alertes. Les journaux sont stockés dans un stockage non SQL qui vous permet de stocker des données de différentes sources pendant un certain temps, soutenant les efforts de conformité et d’audit. En élargissant ce sujet, nous vous invitons à lire le document Registres d’infrastructure. La clé pour résoudre les nouvelles questions de conformité, de sécurité et d’affaires.
- Pandora FMS propose des conceptions personnalisées de panneaux de contrôle ou de tableaux de bord pour afficher des données en temps réel et des données historiques sur plusieurs années. Vous pouvez prédéfinir des rapports sur les calculs de disponibilité, les rapports SLA (mensuels, hebdomadaires ou quotidiens), les histogrammes, les graphiques, les rapports de planification de la capacité, les rapports d’événements, les inventaires et la configuration des composants, entre autres.
- Avec Pandora FMS, vous pouvez superviser le trafic en temps réel, en obtenant une vision claire du volume de demandes et de transactions. Cet outil vous permet d’identifier les schémas d’utilisation, de détecter les pics inattendus et de planifier efficacement la capacité.
- Avec la prémisse qu’il est beaucoup plus efficace de montrer visuellement l’origine d’un échec que de simplement recevoir des centaines d’événements par seconde. Pandora FMS offre la valeur de sa supervision des services, qui vous permet de filtrer toutes les informations et de ne montrer que ce qui est essentiel pour chaque département.

EN: Market analyst and writer with +30 years in the IT market for demand generation, ranking and relationships with end customers, as well as corporate communication and industry analysis.
ES: Analista de mercado y escritora con más de 30 años en el mercado TIC en áreas de generación de demanda, posicionamiento y relaciones con usuarios finales, así como comunicación corporativa y análisis de la industria.
FR: Analyste du marché et écrivaine avec plus de 30 ans d’expérience dans le domaine informatique, particulièrement la demande, positionnement et relations avec les utilisateurs finaux, la communication corporative et l’anayse de l’indutrie.







