








Aujourd’hui, de nombreuses entreprises génèrent et stockent d’énormes quantités de données. Pour vous donner une idée, il y a des décennies, la taille d’Internet était mesurée en téraoctets (TB) et est maintenant mesurée en zettaoctets (ZB).
Les bases de données relationnelles ont été conçues pour répondre aux besoins de stockage et de gestion des informations de l’époque. Aujourd’hui, nous avons un nouveau scénario où les réseaux sociaux, les appareils IdO et l’Edge Computing génèrent des millions de données non structurées et hautement variables. De nombreuses applications modernes nécessitent des performances élevées pour fournir des réponses rapides aux requêtes des utilisateurs.
Dans les SGBD relationnels, une augmentation du volume de données doit s’accompagner d’améliorations de la capacité du matériel. Ce défi technologique a contraint les entreprises à rechercher des solutions plus flexibles et évolutives.
Las bases de données NoSQL ont une architecture distribuée qui leur permet d’évoluer horizontalement et de gérer des flux de données continus et rapides. Cela en fait une option viable dans les environnements à forte demande tels que les plateformes de streaming où le traitement des données est effectué en temps réel.
Compte tenu de l’intérêt que suscitent les bases de données NoSQL dans le contexte actuel, il nous semble indispensable d’élaborer un guide d’utilisation qui aide les développeurs à comprendre et à utiliser efficacement cette technologie. Dans cet article, nous proposons de clarifier certains concepts de base sur NoSQL, en donnant des exemples pratiques et en fournissant des recommandations sur la mise en œuvre et l’optimisation pour tirer le meilleur parti de ses avantages.
- Modélisation de données dans NoSQL
- Stockage et partitionnement des données en NoSQL
- Réplication dans des bases de données NoSQL
- Théorème CAP et cohérence des bases de données NoSQL
- BASE et le modèle de cohérence éventuel en NoSQL
- Indexation des arbres dans les bases de données NoSQL. Quelles sont les structures les plus connues ?
- Comparaison entre les systèmes de gestion de bases de données NoSQL
- Défis dans l’administration des bases de données NoSQL. Comment Pandora FMS aide-t-il ?
Modélisation de données dans NoSQL
L’une des plus grandes différences entre les bases relationnelles et non relationnelles réside dans l’approche que nous adoptons pour la modélisation de données.
Les bases de données NoSQL ne suivent pas un schéma rigide et prédéfini. Cela permet aux développeurs de choisir librement le modèle de données en fonction des caractéristiques du projet.
L’objectif fondamental est d’améliorer les performances des requêtes, en éliminant la nécessité de structurer les informations en tableaux complexes. Ainsi, NoSQL prend en charge une grande variété de données dénormalisées telles que les documents JSON, les valeurs clés, les colonnes et les relations graphiques.
Chaque type de base de données NoSQL est optimisé pour faciliter l’accès, la consultation et la modification d’une classe de données spécifique. Les principales sont les suivantes:
- Clé-valeur : Redis, Riak ou DyamoDB. Ce sont les bases de données NoSQL les plus simples. Ils stockent les informations comme s’il s’agissait d’un dictionnaire basé sur des paires clé-valeur, où chaque valeur est associée à une clé unique. Ils ont été conçus dans le but de s’adapter rapidement en garantissant les performances du système et la disponibilité des données.
- Documentaires : MongoDB, Couchbase. Les données sont stockées dans des documents tels que JSON, BSON ou XML. Certains considèrent qu’il s’agit d’un pas en avant par rapport aux systèmes clé-valeur, car ils permettent d’encapsuler des paires clé-valeur dans des structures plus complexes pour les requêtes avancées.
- Axés sur les colonnes : BigTable, Cassandra, HBase. Au lieu de stocker les données dans des lignes comme le font les bases de données relationnelles, elles les stockent dans des colonnes. Ceux-ci sont à leur tour organisés en familles de colonnes logiquement ordonnées dans la base de données. Le système est optimisé pour travailler avec de grands ensembles de données et des charges de travail distribuées.
- Orienté graphique : Neo4J, InfiniteGraph. Ils stockent les données en tant qu’entités et les relations entre les entités. Les entités sont appelées « nœuds » et les relations qui lient les nœuds entre eux sont les « arêtes ». Ils sont idéaux pour gérer des données avec des relations complexes, telles que les médias sociaux ou les applications avec localisation géospatiale.
Stockage et partitionnement des données en NoSQL
Au lieu d’utiliser une architecture monolithique et coûteuse où toutes les données sont stockées sur un seul serveur, NoSQL distribue les informations sur différents serveurs connus sous le nom de “nœuds” qui sont réunis dans un réseau appelé “grappe”.
Cette fonctionnalité permet au SGBD NoSQL d’effectuer un scale-out et de gérer de gros volumes de données à l’aide de techniques de partitionnement.
Qu’est-ce que le partitionnement dans les bases de données NoSQL ?
Il s’agit d’un processus qui consiste à décomposer une grande base de données en morceaux plus petits et plus faciles à gérer.
Il est nécessaire de préciser que le partitionnement des données n’est pas exclusif au NoSQL. Les bases de données SQL prennent également en charge le partitionnement, mais les systèmes NoSQL disposent d’une fonction native appelée « auto-sharding » qui divise automatiquement les données, équilibrant la charge entre les serveurs.
Quand partitionner une base de données NoSQL ?
Il existe plusieurs situations dans lesquelles il est nécessaire de partitionner une base de données NoSQL :
- Lorsque le serveur est à la limite de sa capacité de stockage ou de sa RAM.
- Lorsque vous avez besoin de réduire la latence. Dans ce cas, équilibrez la charge de travail entre les différents nœuds du cluster afin d’améliorer les performances.
- Lorsque vous souhaitez assurer la disponibilité des données en lançant une procédure de réplication.
Bien que le partitionnement soit utilisé dans les grandes bases de données, il ne faut pas attendre que le volume de données soit excessif car dans ce cas, cela pourrait entraîner une surcharge du système.
De nombreux programmeurs utilisent AWS ou Azure pour simplifier le processus. Ces plates-formes offrent une variété de services cloud qui permettent aux développeurs de se libérer des tâches d’administration des bases de données et de se concentrer sur l’écriture du code de leurs applications.
Techniques de partitionnement
Il existe différentes techniques de partitionnement d’une base de données d’architecture distribuée.
- Clustering
Elle consiste à regrouper plusieurs serveurs afin qu’ils fonctionnent ensemble comme s’ils n’en faisaient qu’un. Dans un environnement de clustering, tous les nœuds du cluster partagent la charge de travail afin d’augmenter le débit du système et la tolérance aux pannes. - Séparation des lectures et des écritures
Elle consiste à diriger les opérations de lecture et d’écriture vers différents nœuds du cluster. Par exemple, les opérations de lecture peuvent être dirigées vers des serveurs répliqués qui agissent comme des esclaves pour soulager la charge sur le nœud principal. - Partitionnement
Les données sont divisées horizontalement en petits morceaux appelés « partitions » et distribuées sur différents nœuds du cluster.
Il s’agit de la technique de partitionnement la plus utilisée dans les bases de données à architecture distribuée en raison de son évolutivité et de sa capacité à équilibrer automatiquement la charge du système, en évitant les goulots d’étranglement. - Hachage cohérent
Il s’agit d’un algorithme utilisé pour allouer efficacement des données aux nœuds dans un environnement distribué.
L’idée de hachages cohérents a été introduite par David Karger dans un article de recherche publié en 1997 et intitulé “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web« .
Dans ce travail académique, l’algorithme « Consistent Hashing » a été proposé pour la première fois comme solution permettant d’équilibrer la charge de travail des serveurs avec les bases de données distribuées.Il s’agit d’une technique utilisée à la fois dans le partitionnement et la réplication des données car elle permet de résoudre des problèmes communs aux deux processus, tels que la redistribution des clés et des ressources lorsque des nœuds sont ajoutés ou supprimés dans un cluster.

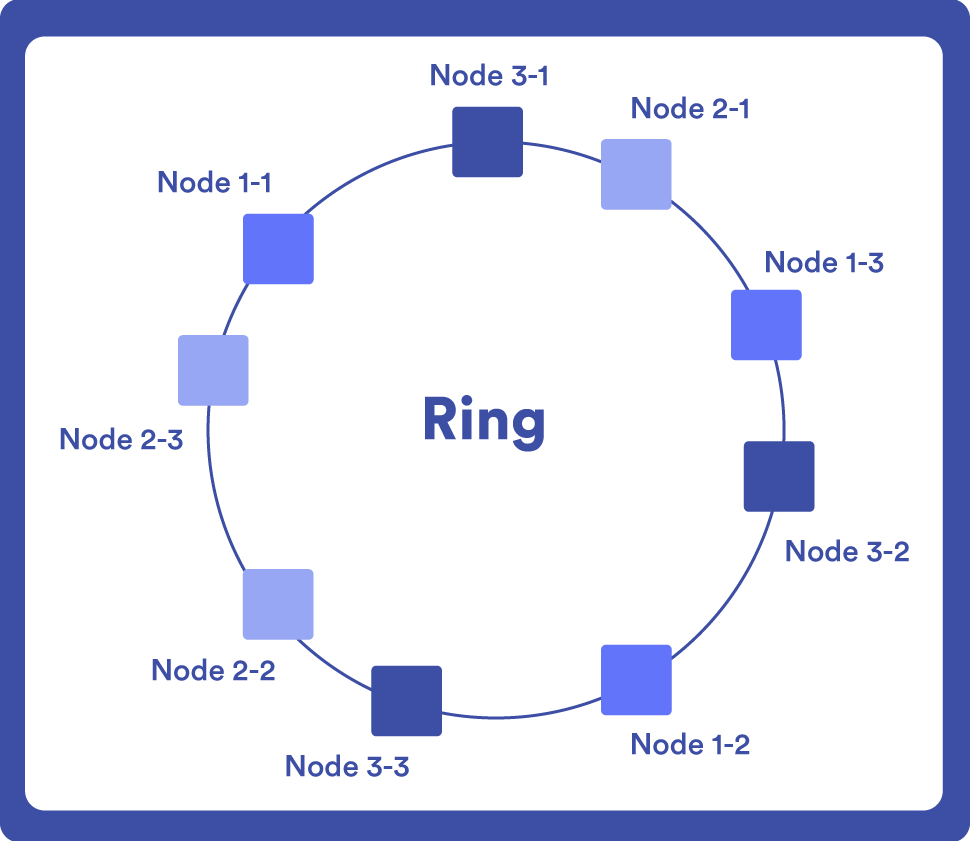
Les nœuds sont représentés dans un anneau circulaire et chaque élément de données est affecté à un nœud à l’aide d’une fonction de hachage. Lorsqu’un nouveau nœud est ajouté au système, les données sont redistribuées entre les nœuds existants et le nouveau nœud.
Le hachage fonctionne comme un identifiant unique, de sorte que lorsque vous effectuez une requête, vous n’avez qu’à placer ce point sur l’anneau.
Un exemple de base de données NoSQL qui utilise le « hachage cohérent » est DynamoDB, car l’un de ses points forts est la mise à l’échelle incrémentale, et pour y parvenir, il a besoin d’une procédure capable de découper dynamiquement les données.
Réplication dans des bases de données NoSQL
Il s’agit de créer des copies des données sur plusieurs machines. Ce processus vise à améliorer les performances des bases de données en répartissant les requêtes entre différents nœuds. En même temps, il garantit que les informations continueront d’être disponibles, même en cas de défaillance du matériel.
Les deux principales façons d’effectuer la réplication des données (en plus du hachage cohérent que nous avons déjà mentionné dans la section précédente) sont les suivantes :
Serveur maître-esclave
L’écriture est effectuée sur le nœud principal et à partir de là, les données sont répliquées sur les nœuds secondaires.
Peer to peer
Tous les nœuds du grappe ont le même niveau hiérarchique et peuvent accepter des écritures. Lorsque les données sont écrites sur un nœud, elles se propagent à tous les autres. Cela garantit la disponibilité, mais peut également entraîner des incohérences si les mécanismes de résolution des conflits ne sont pas mis en œuvre (par exemple, si deux nœuds tentent d’écrire au même emplacement en même temps).

Théorème CAP et cohérence des bases de données NoSQL
Le théorème CAP a été présenté par le professeur Eric Brewer de l’UC Berkeley en 2000. Il explique qu’une base de données distribuée peut répondre à deux de ces trois qualités en même temps :
- Cohérence : Toutes les requêtes après l’opération d’écriture reçoivent la même valeur, quel que soit l’endroit où les requêtes sont effectuées.
- Disponibilité : La base de données répond toujours aux demandes, même en cas de défaillance.
- Tolérance de partition : Le système continue de fonctionner même si la communication entre certains nœuds est interrompue.

Selon ce schéma, nous pourrions choisir un SGBD qui est cohérent et tolérant aux partitions (MongoDB, HBase), disponible et tolérant aux partitions (DynamoDB, Cassandra) ou cohérent et disponible (MySQL), mais ne peut pas conserver les trois caractéristiques à la fois.
Chaque développement a ses exigences et le théorème CAP nous aide à trouver le SGBD qui correspond le mieux à vos besoins. Parfois, il est essentiel que les données soient cohérentes à tout moment (par exemple, dans un système de contrôle des stocks). Dans ces cas, nous travaillons généralement avec une base de données relationnelle. Dans les bases de données NoSQL, la cohérence n’est pas garantie à cent pour cent, car les modifications doivent se propager à tous les nœuds du cluster.
BASE et le modèle de cohérence éventuel en NoSQL
BASE est un concept confronté aux propriétés ACID (atomicité, consistance, isolation, durabilité) des bases de données relationnelles. Dans cette approche, nous donnons la priorité à la disponibilité des données par rapport à la cohérence immédiate, ce qui est particulièrement important dans les applications qui traitent des données en temps réel.
L’acronyme DE BASE signifie :
- Basically Available : La base de données envoie toujours une réponse, même si elle contient des erreurs si des lectures se produisent à partir de nœuds qui n’ont pas encore reçu la dernière écriture.
- Soft state : La base de données peut être dans un état incohérent lors de la lecture, il est donc possible que nous obtenions des résultats disparates à différentes lectures.
- Eventually Consistent : Une cohérence dans la base de données est atteinte une fois que les informations ont été diffusées à tous les nœuds. Jusque-là on parle d’une consistance éventuelle.
Bien que l’approche de BASE soit apparue en réponse à ACID, ce ne sont pas des options exclusives. En effet, certaines bases de données NoSQL comme MongoDB offrent une cohérence configurable.
Indexation des arbres dans les bases de données NoSQL. Quelles sont les structures les plus connues ?
Jusqu’à présent, nous avons vu comment les données sont distribuées et répliquées dans une base de données NoSQL, mais il nous reste à expliquer comment elles sont structurées efficacement pour faciliter leur recherche et leur récupération.
Les arbres sont les structures de données les plus utilisées. ls organisent les nœuds de manière hiérarchique à partir d’un nœud racine qui est le premier nœud de l’arbre, nœuds parent qui sont tous les nœuds qui ont au moins un enfant, et les nœuds enfants qui complètent l’arbre.
Le nombre de niveaux d’un arbre détermine sa hauteur. Il est important de prendre en compte la taille finale de l’arbre et le nombre de nœuds qu’il contient, car cela peut influencer les performances des requêtes et le temps de récupération des données.
Il existe différents index d’arbres que nous pouvons utiliser dans les bases de données NoSQL.
Arbres B
Ils sont des arbres équilibrés et idéaux pour les systèmes distribués pour leur capacité à maintenir la cohérence des indices, bien qu’ils puissent également être utilisés dans des bases de données relationnelles.
La caractéristique principale des arbres B est qu’ils peuvent avoir plusieurs nœuds enfants par nœud parent, mais ils gardent toujours leur hauteur équilibrée. Cela signifie qu’ils possèdent un nombre de niveaux identique ou très similaire dans chaque branche de l’arbre, une particularité qui permet de gérer efficacement les insertions et les suppressions.
Ils sont largement utilisés dans les systèmes de fichiers où il est nécessaire d’accéder rapidement à de grands ensembles de données.
Arbres T
Ce sont également des arbres équilibrés qui peuvent avoir au maximum deux ou trois nœuds enfants.
Contrairement aux arbres B qui sont conçus pour faciliter la recherche de gros volumes de données, les arbres T fonctionnent mieux dans les applications où un accès rapide à des données ordonnées est nécessaire.
Arbres AVL
Ils sont des arbres binaires,ce qui signifie que chaque nœud parent peut avoir au maximum deux nœuds enfants.
Une autre caractéristique remarquable des arbres AVL est qu’ils sont équilibrés en hauteur. Le système d’auto-équilibrage sert à s’assurer que l’arbre ne pousse pas de manière incontrôlée, ce qui pourrait nuire aux performances de la base de données.
Ils constituent un bon choix pour développer des applications nécessitant des consultations rapides et des opérations d’insertion et de suppression en temps logarithmique.
Arbres KD
Ce sont des arbres binaires et équilibrés qui organisent les données en plusieurs dimensions. Une dimension spécifique est créée à chaque niveau de l’arbre.
Ils sont utilisés dans des applications qui travaillent avec des données géospatiales ou des données scientifiques.
Arbres Merkle
Ils représentent un cas particulier de structures de données dans les systèmes distribués. Ils sont connus pour leur utilité dans Blockchain pour chiffrer les données de manière efficace et sécurisée.
Un arbre Merkle est un type d’arbre binaire qui offre une solution de premier ordre au problème de la vérification des données. Son créateur était un informaticien et cryptographe américain nommé Ralph Merkle en 1979.
Les arbres Merkle ont une structure mathématique composée de hachages de plusieurs blocs de données qui résument toutes les transactions dans un bloc.

Les données sont regroupées en plus grands ensembles de données et se rapportent aux nœuds principaux jusqu’à ce que toutes les données soient rassemblées au sein du système. En conséquence, on obtient la Merkle Root.
Comment est calculée la racine Merkle ?
1. Les données sont divisées en blocs d’une taille fixe.
2. Chaque bloc de données est soumis à une fonction de hachage cryptographique.
3. Les hachages sont regroupés par paires et une fonction est à nouveau appliquée à ces paires pour générer leurs hachages parents respectifs jusqu’à ce qu’il ne reste plus qu’un hachage qui est la racine Merkle.
La racine Merkle est en haut de l’arbre et c’est la valeur qui représente en toute sécurité l’intégrité des données. En effet, il est résolument lié à tous les ensembles de données et au hachage qui identifie chacun d’eux. Toute modification des données d’origine modifiera la racine Merkle. De cette façon, nous pouvons avoir la certitude que les données n’ont été modifiées à aucun moment.
C’est pourquoi les arbres Merkle sont fréquemment utilisés pour vérifier l’intégrité des blocs de données dans les transactions Blockchain.
Des bases de données NoSQL comme Cassandra se tournent vers ces structures pour valider les données sans sacrifier la vitesse et les performances.
Comparaison entre les systèmes de gestion de bases de données NoSQL
D’après ce que nous avons pu voir jusqu’à présent, les SGBD NoSQL sont extraordinairement complexes et variés. Chacun d’eux peut adopter un modèle de données différent et présenter des caractéristiques uniques de stockage, de consultation et d’évolutivité. Cet éventail d’options permet aux développeurs de sélectionner la base de données la plus adaptée aux besoins de leur projet.
Ci-dessous, nous allons prendre comme exemple deux des SGBD NoSQL les plus utilisés actuellement pour le développement d’applications évolutives et hautes performances : MongoDB et Apache Cassandra.
MongoDB
C’est un SGBD de type documentaire développé par 10gen en 2007. Il est open source et a été créé dans des langages de programmation tels que C++, C et JavaScript.

MongoDB est l’un des systèmes les plus populaires pour les bases de données distribuées. Les réseaux sociaux tels que LinkedIn, les entreprises de télécommunications telles que Telefónica ou les médias d’information tels que le Washington Post utilisent MongoDB.
Voyons quelques-unes de ses principales caractéristiques.
- Stockage dans la base de données avec MongoDB : MongoDB stocke les données dans des documents BSON (JSON binario). Chaque base de données est composée d’une collection de documents. Une fois que MongoDB est installé et que le Shell est en cours d’exécution, nous pouvons créer la base de données en indiquant simplement le nom que vous voulez utiliser. Si la base de données n’existe pas encore, MongoDB le créera automatiquement lors de l’ajout de la première collection. De même, une collection est créée automatiquement lorsque vous y stockez un document. Il suffit d’ajouter le premier document et d’exécuter l’instruction « insert » et MongoDB créera un champ ID en lui attribuant une valeur du type ObjectID qui est unique pour chaque machine au moment où l’opération est exécutée.
- Partitionnement dans la base de données avec MongoDB : MongoDB facilite la distribution des données sur plusieurs serveurs en utilisant la fonction sharding automatique. La fragmentation des données se produit au niveau de la collection, en répartissant les documents entre les différents nœuds du cluster. Pour effectuer cette distribution, une « clé de partition » définie comme champ est utilisée dans tous les documents de la collection. Les données sont fragmentées en « chunks » qui ont une taille par défaut de 64 Mo et sont stockées dans différentes cartes au sein du cluster, en veillant à ce qu’il y ait un équilibre. MongoBD supervise continuellement les chunks entre les nœuds du shard et, si nécessaire, effectue un rééquilibrage automatique pour s’assurer que la charge de travail supportée par les nœuds est équilibrée.
- Réplication dans base de données avec MongoDB : MongoDB utilise un système de réplication basé sur l’architecture maître-esclave. Le serveur maître peut effectuer des opérations d’écriture et de lecture, mais les nœuds esclaves ne font que des lectures (replica set). Les mises à jour sont communiquées aux nœuds esclaves via un journal d’opération appelé oplog.
- Consultations dans la base de données avec MongoDB : MongoDB dispose d’une puissante API qui permet d’accéder et d’analyser les données en temps réel, ainsi que de réaliser requêtes ad hoc, c’est-à-dire des requêtes directes sur une base de données qui ne sont pas prédéfinies. Cela permet aux utilisateurs d’effectuer des recherches personnalisées, de filtrer les documents et de trier les résultats par champs spécifiques. Pour effectuer ces consultations, MongoDB utilise la méthode « find » sur la collection souhaitée ou « findAndModify » pour consulter et mettre à jour les valeurs d’un ou plusieurs champs simultanément.
- Indexation dans la base de données avec MongoDB :MongoDB utilise des arbres B pour indexer les données stockées dans ses collections. Il s’agit d’une variante des arbres B avec des nœuds d’index contenant des clés et des pointeurs vers d’autres nœuds. Ces index stockent la valeur d’un champ spécifique, ce qui permet aux opérations de récupération et de suppression de données d’être plus efficaces.
- Cohérence dans la base de données avec MongoDB : À partir de la version 4.0 (la plus récente est la 6.0), MongoDB prend en charge les transactions ACID au niveau du document. La fonction « snapshot isolation » offre une vue cohérente des données et permet d’effectuer des opérations atomiques sur plusieurs documents au sein d’une seule transaction. Cette caractéristique est particulièrement pertinente pour les bases de données NoSQL, car elle apporte des solutions à différents problèmes liés à la cohérence, tels que les écritures concurrentes ou les requêtes qui renvoient des versions obsolètes d’un document. À cet égard, MongoDB se rapproche beaucoup de la stabilité des RDMS.
- Sécurité dans la base de données avec MongoDB : MongoDB dispose d’un niveau de sécurité élevé pour garantir la confidentialité des données stockées. Il dispose de plusieurs mécanismes d’authentification, d’une configuration des accès basée sur les rôles, d’un cryptage des données au repos et de la possibilité de restreindre l’accès à certaines adresses IP. En outre, il permet d’auditer l’activité du système et de garder une trace des opérations effectuées dans la base de données.
Apache Cassandra
C’est un SGBD orienté colonnes qui a été développé par Facebook pour optimiser les recherches au sein de sa plateforme. L’un des créateurs de Cassandra est l’informaticien Avinash Lakshman qui a précédemment travaillé avec Amazon, faisant partie du groupe d’ingénieurs qui a développé DynamoDB. Pour cette raison, il n’est pas étonnant qu’il partage certaines caractéristiques avec cet autre système.
En 2008, il a été lancé en tant que projet open source et en 2010, il est devenu un projet de haut niveau de la Fondation Apache. Depuis lors, Cassandra n’a cessé de croître pour devenir l’un des SGBD NoSQL les plus populaires.
Bien qu’aujourd’ hui Meta utilise d’autres technologies, Cassandra fait toujours partie de son infrastructure de données. D’autres entreprises qui l’utilisent sont Netflix, Apple ou Ebay. En termes d’évolutivité, elle est considérée comme l’une des meilleures bases de données NoSQL.

Voyons quelques-unes de ses caractéristiques les plus remarquables :
- Stockage dans la base de données avec Apache Cassandra : Cassandra utilise un modèle de données de type « Column Family », qui est similaire aux bases de données relationnelles, mais plus flexible. Il ne se réfère pas à une structure hiérarchique de colonnes qui contiennent d’autres colonnes, mais plutôt à une collection de paires clé-valeur, où la clé identifie une ligne et la valeur est un ensemble de colonnes. C’est une conception conçue pour stocker de grandes quantités de données et effectuer des opérations d’écriture et de lecture plus efficaces.
- Partitionnement dans la base de données avec Apache Cassandra : Pour la distribution des données Cassandra utilise un partitionneur qui répartit les données sur différents nœuds du cluster. Ce partiteur utilise l’algorithme « consistent hashing » pour attribuer une clé de partition unique à chaque ligne de données. Les données possédant la même clé de partition seront ensemble sur les mêmes nœuds. Il prend également en charge de nœuds virtuels (vnodes), ce qui signifie qu’un même nœud physique peut avoir plusieurs plages de données.
- Réplication de la base de données avec Apache Cassandra : Cassandra propose un modèle de réplication basé sur Peer to peer dans lequel tous les nœuds du cluster acceptent les lectures et les écritures. Ne dépendant pas d’un nœud maître pour traiter les demandes, la possibilité d’un goulot d’étranglement est minime. Les nœuds communiquent entre eux et partagent des données à l’aide d’un protocole de gossiping.
- Requêtes de la base de données avec Apache Cassandra : Tout comme MongoDB, Cassandra prend également en charge les requêtes ad hoc, mais celles-ci ont tendance à être plus efficaces si elles sont basées sur la clé primaire. De plus, il dispose de son propre langage de requête appelé CQL (Cassandra Query Language) avec une syntaxe similaire à SQL, mais qui, au lieu d’utiliser des joints, mise sur la dénormalisation des données.
- Indexation de la base de données avec Apache Cassandra : Cassandra utilise des index secondaires pour permettre des requêtes efficaces sur des colonnes qui ne font pas partie de la clé primaire. Ces index peuvent concerner des colonnes individuelles ou plusieurs colonnes (SSTable Attached Secondary Index). Ils sont créés pour permettre des requêtes complexes de plage, de préfixe ou de recherche de texte sur un grand nombre de colonnes.
- Cohérence de la base de données avec Apache Cassandra : Lors de l’utilisation d’une architecture Peer to Peer Cassandra joue avec la consistance éventuelle. Les données sont diffusées de manière asynchrone sur plusieurs nœuds. Cela signifie que pendant une courte période de temps, il peut y avoir des divergences entre les différentes répliques. Cependant, Cassandra fournit également des mécanismes pour configurer le niveau de cohérence. Lorsqu’un conflit se produit (par exemple, si les répliques ont des versions différentes), utilisez l’horodatage (timestamp) et considérez la version la plus récente comme valide. En outre, il effectue des réparations automatiques pour maintenir la cohérence et l’intégrité des données en cas de défaillance matérielle ou d’autres événements qui causent des écarts entre les répliques.
- Sécurité de la base de données avec Apache Cassandra : Pour utiliser Cassandra dans un environnement sécurisé, il est nécessaire d’effectuer des configurations, car de nombreuses options ne sont pas activées par défaut. Par exemple, activez le système d’authentification et définir des autorisations pour chaque rôle d’utilisateur. En outre, il est essentiel de crypter les données en transit et au repos. Pour la communication entre les nœuds et le client, les données en transit peuvent être cryptées en utilisant SSL/TLS.
Défis dans l’administration des bases de données NoSQL. Comment Pandora FMS aide-t-il ?
Les SGBD NoSQL offrent aux développeurs la possibilité de gérer de gros volumes de données et d’évoluer horizontalement en ajoutant plusieurs nœuds à un cluster.
Pour gérer ces infrastructures distribuées, il est nécessaire de maîtriser différentes techniques de partitionnement et de réplication des données (par exemple, nous avons vu que MongoDB utilise une architecture maître-esclave, tandis que Cassandra privilégie la disponibilité avec le modèle Peer to peer).
Contrairement aux RDMS qui partagent de nombreuses similitudes, dans les bases de données NoSQL, il n’y a pas de paradigme commun et chaque système a ses propres API, langages et une implémentation différente, donc s’habituer à travailler avec chacun d’eux peut être un véritable défi.
Étant donné que la supervision est un composant fondamental pour l’administration de toute base de données, nous devons être pragmatiques et nous appuyer sur les ressources qui nous facilitent la vie.
MongoDB et Apache Cassandra disposent toutes deux de commandes qui renvoient des informations sur l’état du système et permettent de diagnostiquer les problèmes avant qu’ils ne deviennent des défaillances critiques. Une autre possibilité consiste à utiliser le logiciel Pandora FMS pour simplifier l’ensemble du processus.
Comment le faire ?
S’il s’agit d’une base de données sur MongoDB, nous devons télécharger le plugin Pandora FMS pour MongoDB. Ce plugin utilise la commande mongostat pour collecter des informations de base sur les performances du système. Une fois les mesures pertinentes obtenues, elles sont envoyées au serveur de données de Pandora FMS pour analyse.
En revanche, si la base de données fonctionne avec Apache Cassandra, nous devons télécharger le plugin correspondant à ce système. Ce plugin obtient les informations en exécutant en interne l’outil nodetool, qui est déjà inclus dans l’installation standard de Cassandra et offre une large gamme de commandes pour superviser l’état des serveurs. Une fois les résultats analysés, le plugin structure les données au format XML et les envoie au serveur Pandora FMS pour une analyse et une visualisation ultérieures.
Pour que ces plugins fonctionnent correctement, il faut copier les fichiers dans le répertoire des plugins de l’agent Pandora FMS, éditer le fichier de configuration et enfin redémarrer le système (la procédure est très bien expliquée dans les articles liés).
Une fois que les plugins sont actifs, nous pouvons superviser l’activité des nœuds du cluster dans une vue graphique et recevoir des alertes en cas de défaillance. Ces options d’automatisation et d’autres nous aident à économiser beaucoup de temps et de ressources dans la maintenance des bases de données NoSQL.
¡Créez un compte gratuit et découvrez tous les utilitaires de Pandora FMS pour propulser votre projet numérique !
Et si vous avez des doutes sur la différence entre NoSQL et SQL, vous pouvez consulter notre article « NoSQL vs SQL : principales différences et quand choisir chacune d’entre elles« .

J’ai étudié la philologie, mais les circonstances de la vie m’ont amenée à travailler dans le secteur du marketing en tant que rédactrice de contenu. Je suis passionnée par le monde du blogging et par l’opportunité d’apprendre qui accompagne chaque nouveau projet. Je vous invite à suivre mes articles sur le blog de Pandora FMS pour découvrir les tendances technologiques qui transforment le monde des affaires.







