








Parler d’un trop grand nombre d’alertes de cybersécurité, ce n’est pas parler de l’histoire de Pierre et le loup et de la façon dont les gens finissent par ignorer les faux avertissements, mais de leur grand impact sur les stratégies de sécurité et, surtout, sur le stress que cela cause à l’équipe informatique, qui, nous le savons bien, sont de plus en plus réduits et doivent remplir diverses tâches dans leur vie quotidienne.
La fatigue des alertes est un phénomène dans lequel un trop grand nombre d’alertes désensibilise les personnes chargées d’y répondre, ce qui entraîne des alertes manquées ou ignorées ou, pire, des réponses retardées. Les professionnels des opérations de sécurité informatique sont sujets à cette fatigue, car les systèmes sont surchargés de données et peuvent ne pas classer les alertes avec précision.
Définition de la fatigue d’alerte et son impact sur la sécurité organisationnelle
La fatigue des alertes, en plus d’être submergée de données à interpréter, détourne l’attention de ce qui est vraiment important. Pour mettre les choses en perspective, la tromperie est l’une des plus anciennes tactiques de guerre depuis les Grecs anciens : par la tromperie, l’attention de l’ennemi était détournée en donnant l’impression qu’une attaque se déroulait à un endroit, ce qui obligeait l’ennemi à concentrer ses ressources sur cet endroit afin d’attaquer sur un autre front. En transférant cela à une organisation, la cybercriminalité peut très bien provoquer et exploiter la fatigue du personnel informatique pour trouver des failles de sécurité. Le coût de cela peut être élevé en termes de continuité d’activité et de consommation de ressources (technologie, temps et ressources humaines), comme l’indique un article de Security Magazine sur une enquête menée auprès de 800 professionnels de l’informatique :
- 85 % des professionnels des technologies de l’information (TI) déclarent que plus de 20 % de leurs alertes de sécurité cloud sont des faux positifs. Plus il y a d’alertes, plus il devient difficile d’identifier ce qui est important et ce qui ne l’est pas.
- 59 % des personnes interrogées reçoivent plus de 500 alertes de sécurité dans le cloud public par jour. Le fait de devoir filtrer les alertes fait perdre un temps précieux qui pourrait être utilisé pour dépanner ou même prévenir les problèmes.
- Plus de 50 % des personnes interrogées passent plus de 20 % de leur temps à décider quelles alertes doivent être traitées en premier. La surcharge d’alertes et les taux de faux positifs contribuent non seulement au turnover, mais aussi à la perte d’alertes critiques. 55 % déclarent que leur équipe a négligé les alertes critiques dans le passé en raison d’une hiérarchisation inefficace des alertes, souvent sur une base hebdomadaire et même quotidienne.
Ce qui se passe, c’est que l’équipe chargée d’examiner les alertes devient désensibilisée. Par nature humaine, lorsque nous recevons un avertissement à propos de chaque petite chose, nous nous habituons à ce que les alertes soient sans importance, de sorte qu’on leur accorde de moins en moins d’importance. Cela signifie que nous devons trouver un équilibre : nous devons être conscients de l’état de notre environnement, mais trop d’alertes peuvent causer plus de dommages que l’aide qu’elles fournissent, car elles rendent difficile la hiérarchisation des problèmes.
Causes de la fatigue d’alerte
Alerte La fatigue est due à une ou plusieurs des causes suivantes :
Faux positifs
Il s’agit de situations dans lesquelles un système de sécurité identifie par erreur une action ou un événement bénin comme une menace ou un risque. Ils peuvent être causés par un certain nombre de facteurs, tels que des signatures de menaces obsolètes, des configurations de sécurité médiocres (ou trop zélées) ou des limitations dans les algorithmes de détection.
Manque de contexte
Les alertes doivent être interprétées, donc si les notifications d’alerte n’ont pas le contexte approprié, il peut être déroutant et difficile de déterminer la gravité d’une alerte. Cela entraîne des réponses tardives.
Systèmes de sécurité multiples
Il est difficile de consolider et de corréler les alertes si plusieurs systèmes de sécurité fonctionnent en même temps… Et cela s’aggrave lorsque le volume d’alertes avec différents niveaux de complexité augmente.
Absence de filtres et de personnalisation des alertes de cybersécurité
L’absence de définition et de filtrage peut entraîner des notifications sans fin non menaçantes ou non pertinentes..
Politiques et procédures de sécurité peu claires
Des procédures mal définies deviennent très problématiques car elles contribuent à aggraver le problème.
Rareté des ressources
Il n’est pas facile d’avoir des professionnels de la sécurité qui savent interpréter et gérer un volume élevé d’alertes, ce qui entraîne des réponses tardives.
Cela nous indique que des politiques de gestion et d’alerte appropriées sont nécessaires, ainsi que les bons outils de supervision pour soutenir le personnel informatique.
Faux positifs les plus courants
Selon l’Institute of Data de l’Institute of Data, les faux positifs auxquels sont confrontées les équipes informatiques et de sécurité sont les suivants :
Faux positifs sur des anomalies dans le réseau
Ceux-ci se produisent lorsque les outils de supervision réseau identifient des activités réseau normales ou inoffensives comme suspectes ou malveillantes, telles que de fausses alertes pour des analyses réseau, le partage de fichiers légitimes ou les activités système en arrière-plan.
Faux positifs de logiciels malveillants
Les logiciels antivirus signalent souvent les fichiers ou les applications inoffensifs comme potentiellement malveillants. Cela peut se produire lorsqu’un fichier présente des similitudes avec signatures de logiciels malveillants connus ou affiche un comportement suspect. Dans ce contexte, un faux positif dans le domaine de la cybersécurité peut entraîner le blocage ou la mise en quarantaine de logiciels légitimes, ce qui perturbe les opérations normales.
Faux positifs sur le comportement de l’utilisateur
Les systèmes de sécurité qui supervisent les activités des utilisateurs peuvent générer un faux positif en matière de cybersécurité lorsque les actions d’un individu sont signalées comme anormales ou potentiellement malveillantes. Exemple : Un employé accédant à des documents confidentiels en dehors des heures de travail, générant un faux positif en cybersécurité, alors même qu’il peut être légitime.
Les faux positifs peuvent également être trouvés dans les systèmes de sécurité des e-mails. Par exemple, les filtres anti-spam peuvent classer à tort les e-mails légitimes comme spam, ce qui entraîne la chute de messages importants dans le dossier spam. Pouvez-vous imaginer l’impact qu’un courrier d’une importance vitale se retrouve dans le dossier Spam ?
Conséquences de la fatigue des alertes
La fatigue des alertes a des conséquences non seulement sur le personnel informatique lui-même, mais également sur l’organisation :
Faux sentiment de sécurité
Trop d’alertes peuvent amener l’équipe informatique à penser qu’il s’agit de faux positifs, laissant de côté les actions qui pourraient être prises.
Réponse tardive
Les alertes excessives saturent l’équipe informatique, l’empêchant de réagir à temps aux risques réels et critiques. Cela, à son tour, provoque des remèdes coûteux et même la nécessité d’affecter plus de personnel pour résoudre le problème qui aurait pu être évité.
Non-conformité réglementaire
Les violations de sécurité peuvent entraîner des amendes et des sanctions pour l’organisation.
Dommages de réputation pour l’organisation
Une violation de la sécurité de l’entreprise arrive à être divulguée (et nous avons vu des gros titres dans les nouvelles) et a un impact sur sa réputation. Cela peut entraîner une perte de confiance des clients… et donc générer moins de revenus.
Surcharge de travail pour le personnel informatique
Si le personnel chargé de la supervision des alertes se sent submergé par les notifications, il peut éprouver un stress professionnel accru. C’est l’une des causes de la baisse de productivité et de la forte rotation du personnel dans le domaine informatique.
Détérioration du moral
La démotivation de l’équipe peut les amener à cesser de s’impliquer et à devenir moins productifs.
Comment éviter ces problèmes de fatigue des alertes ?
Si les alertes sont conçues avant d’être mises en œuvre, elles deviennent des alertes utiles et efficaces, en plus de gagner beaucoup de temps et, par conséquent, de réduire la fatigue des alertes.
Prioriser
La meilleure façon d’obtenir une alerte efficace est d’utiliser la stratégie « moins, c’est plus ». Il faut d’abord penser aux choses absolument indispensables.
- Quels équipements sont absolument indispensables ? Presque personne n’a besoin d’alertes sur les équipements de test.
- Quelle est la gravité si un certain service ne fonctionne pas correctement ? Les services à fort impact doivent avoir l’alerte la plus agressive (niveau 1, par exemple).
- Qu’est-ce qui minimum est nécessaire pour déterminer qu’un équipement, un processus ou un service NE fonctionne pas correctement ? Parfois, il suffit de superviser la connectivité de l’appareil, à d’autres moments, quelque chose de plus spécifique est nécessaire, comme l’état d’un service.
Répondre à ces questions aidera à savoir quelles sont les alertes les plus importantes sur lesquelles nous devons agir immédiatement.
Éviter les faux positifs
Parfois, il peut être difficile de faire en sorte que les alertes ne se déclenchent que lorsqu’il y a vraiment un problème. La configuration correcte des seuils représente une grande partie du travail, mais d’autres options sont disponibles. Pandora FMS dispose de plusieurs outils pour aider à éviter les faux positifs :
Seuils dynamiques
Ils sont très utiles pour ajuster les seuils aux données réelles. En activant cette fonction dans un module, Pandora FMS analyse votre historique de données et modifie automatiquement les seuils pour capturer les données qui sortent de l’ordinaire.



- Seuils FF: Parfois, le problème n’est pas que nous n’avons pas défini correctement les alertes ou les seuils, mais que les métriques que nous utilisons ne sont pas entièrement fiables. Disons que nous supervisons la disponibilité d’un appareil, mais que la connexion au réseau sur lequel il se trouve est instable (par exemple, un réseau sans fil très saturé). Cela peut conduire à la perte de paquets de données ou même à des moments où un ping ne parvient pas à se connecter à l’appareil même s’il est actif et remplit correctement sa fonction. Pour ces cas, Pandora FMS dispose du Seuil FF (FF Threshold). En utilisant cette option, vous pouvez définir une certaine « tolérance » au module avant de changer d’état. Ainsi, par exemple, l’agent rapportera deux données critiques consécutives pour que le module passe à l’état critique.
- Utiliser des fenêtres de maintenance: Pandora FMS permet de désactiver temporairement l’alerte et même la génération d’événements d’un module ou d’un agent spécifique avec le mode silencieux (Quiet). Avec les fenêtres de maintenance (Scheduled downtimes), cela peut être programmé pour que, par exemple, aucune alerte ne saute lors des mises à jour du service X le samedi matin.
Améliorer les processus d’alerte
Une fois qu’ils se sont assurés que les alertes déclenchées sont nécessaires et qu’elles ne sauteront que lorsque quelque chose se produira réellement, vous pouvez améliorer le processus comme suit :
- Automatisation: L’alerte ne sert pas seulement à envoyer des notifications ; elle peut également être utilisée pour automatiser des actions. Imaginons que vous supervisez un ancien service qui est parfois saturé, et lorsque cela se produit, la façon de le récupérer est simplement de le redémarrer. Avec Pandora FMS, vous pouvez configurer l’alerte qui supervise ce service pour qu’il essaie de le redémarrer automatiquement. Pour ce faire, il suffit de configurer une commande d’alerte qui, par exemple, appelle l’API du gestionnaire de ce service pour le redémarrer.
- Mise à l’échelle des alertes: En suivant l’exemple ci-dessus, avec la mise à l’échelle des alertes, vous pouvez faire en sorte que la première action effectuée par Pandora FMS, lorsque l’alerte est déclenchée, soit une réinitialisation du service. Si lors de l’exécution suivante de l’agent, le module est toujours dans un état critique, vous pouvez configurer l’alerte pour que, par exemple, un ticket soit créé dans Pandora ITSM.
- Seuils d’alerte: Les alertes ont un compteur interne qui indique quand les actions configurées doivent être déclenchées. En modifiant simplement le seuil d’une alerte, vous pouvez passer d’avoir plusieurs courriels par jour vous informant du même problème à en recevoir un tous les deux ou trois jours.

Cette alerte (d’exécution quotidienne) comporte trois actions : dans un premier temps, il s’agit de redémarrer le service. Si l’exécution d’alerte suivante n’a pas été récupérée, un courrier électronique est envoyé à l’administrateur, et si elle n’a pas encore été résolue, un ticket est créé dans Pandora ITSM. Si l’alerte reste déclenchée à la quatrième exécution, un message quotidien sera envoyé par Slack au groupe d’opérateurs.
Autres moyens de réduire le nombre d’alertes
- La protection en cascade (Cascade Protection) est un outil inestimable dans la configuration d’une alerte efficace, en omettant le déclenchement d’alertes d’appareils dépendant d’un appareil principal. Avec une alerte de base, si vous supervisez un réseau auquel vous accédez via un commutateur spécifique et que cet appareil a un problème, vous commencerez à recevoir des alertes pour chaque ordinateur de ce réseau auquel vous ne pouvez plus accéder. En revanche, si vous activez la protection en cascade sur les agents de ce réseau (indiquant qu’ils dépendent du commutateur), Pandora FMS détectera que l’équipement principal est en panne et ignorera l’alerte de tous les équipements dépendants jusqu’à ce que le commutateur redevienne opérationnel.
- L’utilisation de services peut nous aider non seulement à réduire le nombre d’alertes déclenchées, mais aussi le nombre d’alertes configurées. Si vous avez un cluster de 10 machines, il n’est peut-être pas très efficace d’avoir une alerte pour chacune d’elles. Pandora FMS permet de regrouper des agents et des modules dans les Services, ainsi que des structures hiérarchiques dans lesquelles vous pouvez décider du poids de chaque élément et alerter en fonction de l’état général.
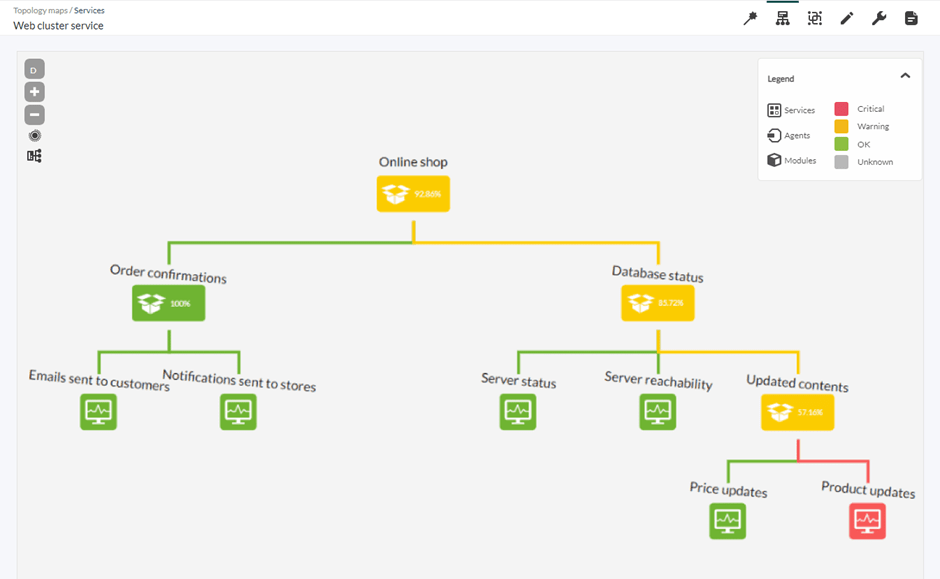
Mettre en œuvre un plan de réponse aux incidents
La réponse aux incidents est le processus de préparation aux menaces de cybersécurité, de détection de celles-ci au fur et à mesure de leur apparition, de réponse pour les étouffer ou les atténuer. Les organisations peuvent gérer l’intelligence et l’atténuation des menaces grâce à la planification de la réponse aux incidents. N’oubliez pas que toute organisation risque de perdre de l’argent, des données et de la réputation en raison des menaces à la cybersécurité.
La réponse aux incidents nécessite de réunir une équipe de personnes de différents départements au sein d’une organisation, y compris les dirigeants de l’organisation, une partie du personnel informatique et d’autres domaines impliqués dans le contrôle et la conformité des données. Il est recommandé de :
- Planifier comment analyser les données et les réseaux à la recherche de menaces potentielles et d’activités suspectes.
- Décider quels incidents doivent recevoir une réponse en premier.
- Avoir un plan pour la perte de données et de finances.
- Se conformer à toutes les lois pertinentes.
- Être prêt à présenter des données et des documents aux autorités après une infraction.
Enfin, un rappel opportun : la réponse aux incidents est devenue très importante à partir du GDPR avec des règles extrêmement strictes sur les rapports de non-conformité. Si un manquement spécifique doit être signalé, l’entreprise doit en prendre connaissance dans les 72 heures et communiquer ce qui s’est passé aux autorités compétentes. Un rapport sur ce qui s’est passé doit également être fourni et un plan actif doit être présenté pour atténuer les dommages. Si une entreprise n’a pas de plan de réponse aux incidents prédéfini, elle ne sera pas prête à soumettre un tel rapport.
La RPDG exige également de savoir si l’organisation dispose des mesures de sécurité appropriées. Les entreprises peuvent être lourdement pénalisées si elles sont examinées après l’infraction et que les fonctionnaires découvrent qu’elles n’étaient pas suffisamment sécurisées.
Conclusion
Le coût élevé est clair tant pour le personnel informatique (rotation constante, épuisement, stress, décisions tardives, etc.) que pour l’organisation (interruption des opérations, fuites et failles de sécurité, pénalités assez lourdes). Bien qu’il n’y ait pas de solution unique pour éviter les alertes excessives, il est recommandé de prioriser les alertes, d’éviter les faux positifs (seuils dynamiques et FF, fenêtres de maintenance), d’améliorer les processus d’alerte et un plan de réponse aux incidents, ainsi que des politiques et des procédures claires pour répondre aux incidents, afin de vous assurer de trouver le bon équilibre pour votre organisation.
Contactez-nous pour vous accompagner avec les meilleures pratiques de Supervision et alertes.
Si cet article vous a intéressé, vous pouvez également lire : Savez-vous à quoi servent les seuils dynamiques dans la surveillance ?

EN: Market analyst and writer with +30 years in the IT market for demand generation, ranking and relationships with end customers, as well as corporate communication and industry analysis.
ES: Analista de mercado y escritora con más de 30 años en el mercado TIC en áreas de generación de demanda, posicionamiento y relaciones con usuarios finales, así como comunicación corporativa y análisis de la industria.
FR: Analyste du marché et écrivaine avec plus de 30 ans d’expérience dans le domaine informatique, particulièrement la demande, positionnement et relations avec les utilisateurs finaux, la communication corporative et l’anayse de l’indutrie.







