








Superviser hadoop open source est désormais possible avec ce tutoriel
Avant de comprendre comment superviser Hadoop (dans le cadre d’open source), il est nécessaire de faire un très bref exposé de ce qu’est Hadoop, pour voir qu’il a une relation étroite avec le Big Data et en plus, comment gérer les énormes quantités de données. Pour commencer, disons que les inconvénients résident non seulement dans la quantité mais aussi dans l’hétérogénéité des données. En d’autres termes, et pour être plus explicite, il faut tenir compte du fait que les problèmes sont présentés par quantité, avec hétérogénéité.
Concernant l’hétérogénéité du big data, il faut garder à l’esprit qu’ il existe trois types : Le structuré, semi-structuré et non structuré. Notez que le système HDFS (Relational Database Management System) est basé sur des données structurées, comme dans le cas sensible des transactions bancaires et des données opérationnelles, entre autres. Hadoop se concentre donc (et se spécialise) sur les données semi-structurées et sur ce qui est structuré comme du texte, des publications Facebook, des audios, des vidéos, des journaux, etc.
Notons en revanche que la technologie du système Hadoop a été développée et se trouve à un niveau de demande intéressant grâce au Big Data qui, pour la plupart, est constitué de données non structurées et dans différents formats. Maintenant, le problème principal consiste à stocker des quantités colossales de données, car il n’est pas possible de les stocker dans le système traditionnel.
Le deuxième des problèmes est que le stockage de données hétérogènes est complexe. Le stockage n’est qu’une partie du problème, car la quantité de données est non seulement énorme, mais aussi dans une variété de formats. À ce titre, il est nécessaire de s’assurer que nous avons un système pour stocker cette hétérogénéité des données, qui est générée à partir de diverses sources.
Le troisième problème à analyser concerne l’accès et la vitesse de traitement. La capacité des disques durs augmente incontestablement, bien que leur vitesse de transfert et leur vitesse d’accès n’augmentent pas aussi rapidement. Regardons un exemple illustratif :
Dans le cas où nous n’avons qu’un canal d’E/S de 100 Mbps et que, en plus, il traite 1 To de données, le processus lui-même pourrait prendre près de trois heures (2,90 heures). Si vous avez environ quatre machines, avec quatre canaux d’E/S pour la même quantité de données, c’est-à-dire 1 To, le processus « ne prendra que » environ 43 minutes, dans ce cas. En présentant cet exemple simple (mais illustratif), nous nous rendons immédiatement compte de l’importance de savoir comment superviser Hadoop.
Pour saisir en la matière, commençons par dire qu’il existe de nombreux outils pour analyser et optimiser les performances d’un cluster Hadoop, à la fois open source, gratuit (mais fermé) et commercial. Désormais, pour les finalités qui nous intéressent particulièrement, nous ferons référence aux outils open source. Il s’avère que chaque composant de Hadoop (en ce qui concerne l’open source, nous le répétons) est livré avec son interface administrative respective qui, à juste titre, peut être utilisée pour collecter des métriques de performances à travers le cluster.
Malheureusement, cependant, l’ajout de telles mesures pour la corrélation de sources disparates et multiples est en soi un défi. Mais vous pouvez le faire vous-même, à l’aide d’un guide que nous vous présenterons le plus clairement possible. Il s’agit, en outre, d’un guide pour collecter des métriques de performances à partir de HDFS, YARN et MapReduce, en utilisant les API HTTP exposées pour chaque technologie. Précisons, qu’une excellente offre open source pour la gestion Hadoop et l’analyse des performances est le projet Apache Ambari, qui fournit aux utilisateurs une interface graphique assez bien conçue pour la gestion des clusters.
En d’autres termes, disons que sur une seule interface, vous pouvez provisionner, gérer et superviser des clusters de milliers de machines. Ainsi, on peut noter (sans crainte d’erreurs, ni d’exagérations insensées) que c’est un excellent outil pour travailler avec et, accessoirement, pour superviser Hadoop. Voyons donc comment nous pouvons collecter des métriques Hadoop, pour souligner dans un premier temps que nous allons nous concentrer sur la supervision de la « santé » et des performances de Hadoop, qui fournit une large gamme et variée de métriques sur les performances d’exécution des tâches, l’intégrité et l’utilisation des ressources.
Au cours de cette présentation, nous expliquerons au lecteur comment collecter des métriques pour les composants les plus importants de Hadoop, tels que HDFS, YARN et MapReduce, mais, oui, en utilisant des outils de développement standard, en plus d’autres outils spécialisés tels que Cloudera Manager et Apache Ambari.
La collecte des métriques HDFS :
HDFS génère des métriques à partir de deux sources :
Les DataNodes et le Name Node qui, pour la plupart, chacune de ces deux métriques doivent être collectées à leurs points d’origine respectifs. Les deux sources précédentes émettent des métriques via une interface HTTP et également via JMX. Ainsi, nous nous concentrerons sur les trois thèmes suivants, sans en ignorer d’autres que nous développerons également dans une moindre mesure :
- Collection de métriques NameNode via l’API..
- Collection de métriques de DataNode via l’API.
- Collecte des métriques HDFS via JMX.
API de HTTP NameNode :
Il s’avère que NameNode fournit un résumé des mesures de performances et d’intégrité, à l’aide d’une interface utilisateur Web. Cette interface utilisateur est accessible via le port 50070, nous devons donc pointer un navigateur Web vers : http://namenodehost:50070
Bien qu’il soit vrai qu’il soit conseillé et confortable d’avoir un résumé, il est possible que certains (ou plusieurs) lecteurs veuillent se plonger dans d’autres métriques, nous vous suggérons donc, pour les apprécier toutes, de pointer votre navigateur vershtpp://namenodehost:50070/jmx
Donc, si vous utilisez l’API ou, enfin, JMX, alors vous pouvez trouver une sorte de « deuxième partie » dans MBean Hadoop:name=NameNode. VolumeFailtures Total.
En ce qui concerne, cette fois, NumDeadDataNodes, NumLiveDataNodes, NumLiveDecomDataNodes et NumStaleDataNodes peuvent être trouvés sous le MBean Hadoop:name=FSNamesystemState,service=NameNode.
API HTTP DataNode :
Un aperçu de l’intégrité de vos DataNodes, est disponible et accessible aux utilisateurs dans le panneau NameNode, sous l’onglet intitulé « Datanones » (http://localhost:50070/dfshealth.html#tab-datanode). Cependant, afin d’obtenir une vue beaucoup plus détaillée d’un DataNode individuel, ses métriques sont accessibles via l’API DataNode.
Désormais, pour obtenir une vue et une vision plus détaillées d’un DataNode individuel, nous pouvons accéder à nos métriques via l’API DataNode. Par défaut, DataNodes expose absolument toutes ses métriques sur le port 50075, via jmx. La façon dont nous venons d’écrire cette section sur JMX ne semble pas, au premier abord, très orthodoxe, mais il faut le faire pour que le lecteur ait une clarté absolue et, accessoirement, pour que personne ne fasse d’erreur. Par exemple dans le cas de placer jmx., la situation pourrait conduire à des malentendus. Comme ils nous le disent dans Pandora FMS, « … un système de supervision doit être simple et efficace ».
D’autre part, clarifions qu’atteindre ce point extrême dans votre DataNode avec votre navigateur ou curl, vous fournit toutes les métriques de ce type de deuxième partie de cette série. Voyons ci-dessous ce qui concerne les métriques NameNode et DataNode via JMX, pour compléter la série et, surtout, pour continuer à exposer le sujet à travers une séquence logique de concepts.
Métriques NameNode et DataNode utilisant (ou « via ») JMX.
De la même manière que Kafka, Cassandra et d’autres systèmes basés sur Java, ils exposent également des métriques à l’aide de JMX, à la fois dans DataNode et NameNode. Les interfaces d’agent distant JMX sont alors désactivées par défaut. Pour cette raison, il est nécessaire de les activer, en définissant les options JVM suivantes dans hadoop-env.sh qui se trouvent normalement dans $HADOOP_HOME/conf . Autre précision orthographique, il faut la relever dans cette partie de l’exposition : notez que le précédent « point » était placé séparément du mot « conf ». Voyons, maintenant oui :
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote
Dcom.sun.management.jmxremote.password.file=$HADOOP_HOME/conf/jmxremote.password-Dcom.sun.management.jmxremote.ssl=false
Dcom.sun.management.jmxremote.port=8004 $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote
Dcom.sun.management.jmxremote.password.file=$HADOOP_HOME/conf/jmxremote.password
Dcom.sun.management.jmxremote.ssl=false
Dcom.sun.management.jmxremote.port=8008 $HADOOP_DATANODE_OPTS"
La configuration précédente, obtenue à partir de https://goo.gl/D9DAeK, ouvrira le port 8008 (sur le DataNode) et 8004 (sur le NameNode). Dans les deux cas avec l’authentification par mot de passe activée. À cet égard, nous suggérons aux lecteurs de consulter comment configurer un environnement mono-utilisateur, afin d’avoir plus d’informations sur la façon de configurer l’agent distant JMX. En continuant avec une séquence logique de l’explication, disons qu’une fois le mot de passe activé, nous pouvons nous connecter, via n’importe quelle console JMX comme, par exemple, JConsole ou Jmxterm. Ce qui suit n’est qu’un début de la connexion Jmxterm avec le NameNode, en tenant compte du fait qu’il existe une première liste de MBeans disponibles, puis en explorant le Haddop:name=FSName,system,service=NameNodeMBean.
Collecte des compteurs MapReduce :
● Les compteurs MapReduce :: Ils nous donnent des informations sur l’exécution de la tâche, précisément, comme le temps CPU et, aussi, la mémoire utilisée. Ils doivent être téléchargés sur la console respective lors de l’appel de travaux Hadoop à partir de la ligne de commande. Ce qui précède est idéal pour la vérification des points, tandis que les travaux sont en cours d’exécution. Bien sûr : une analyse plus détaillée nécessite de superviser les compteurs, au fil du temps.
● Le ReduceManager, à son tour, expose également tous les compteurs MapReeduce pour chacun des postes de travail. Pour accéder aux compteurs MapReduce dans notre ResourceManager, nous devons d’abord accéder à l’interface Web ResourceManager à htpp://resourcemanagerhost:80008 . Ensuite, vous pouvez trouver l’application qui vous intéresse puis cliquer sur « Historique » qui est un onglet situé dans la colonne intitulée « Supervision de l’interface utilisateur ».
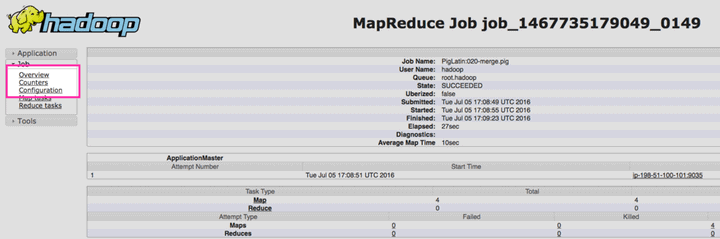
Il faut trouver l’application qui vous intéresse et cliquer sur « Historique » dans la colonne « Supervision de l’interface utilisateur ». Pour une plus grande clarté, voyons une image intéressante qui peut être plus clarifiant :

Ensuite, c’est-à-dire sur la page suivante, il faut cliquer sur « Compteurs », qui se trouve dans le menu de navigation à gauche, comme on peut le voir dans l’image suivante qui, comme la précédente, vous pouvez agrandir.
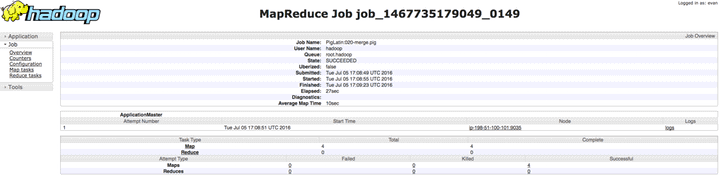
Enfin (juste pour l’instant), vous devriez voir tous les compteurs collectés et associés au travail que vous avez fait et faisez :
La collection de métriques Hadoop YARN :
API HTTP et YANR :
YARN expose, par défaut, toutes ses métriques sur le port 98088, à l’aide du point de terminaison jmx . En atteignant ce point de terminaison d’API, YARN nous donne toutes les métriques pour superviser Hadoop, dans la deuxième partie de cette série. Comme avec HDFS, lorsque nous interrogeons le point de terminaison JMX, il peut spécifier des MBeans à l’aide du paramètre qry , comme nous le voyons ci-dessous :
$ curl resourcemanagerhost:8000/jmx?qry=java.lang:type=Memory
Si vous voulez uniquement obtenir les métriques de la deuxième partie de la série, vous pouvez également consulter le point final ws/v1/cluster/metrics endpoint.
Outils tiers :
Les méthodes de collecte natives sont utiles lorsqu’il s’agit de mesures de vérification ponctuelle ou, en d’autres termes, de vérification ponctuelle. Cependant, pour avoir une vue d’ensemble (ce qui est approprié et souhaitable), il est nécessaire de collecter et d’ajouter des métriques dans tous les systèmes, afin d’établir une corrélation nécessaire. Ainsi, deux projets très importants, à savoir Cloudera Manager et Apache Ambari, nous fournissent aux utilisateurs une plate-forme unifiée à des fins d’administration, de supervision et de gestion Hadoop.
Ces deux projets nous fournissent des outils pour collecter et afficher les métriques Hadoop, ainsi que d’autres outils pour les tâches de dépannage courantes.
Apache Ambari
L’objectif de ce projet est de faciliter la gestion des clusters Hadoop en créant des logiciels, afin de réaliser l’approvisionnement, la gestion et, aussi, la supervision des clusters Apache Hadoop. C’est sans aucun doute un excellent outil pour gérer le cluster et, comme nous l’avons déjà noté, pour sa supervision ou son monitoring. Voyons, ci-dessous, une instruction pour l’installation sur différentes plates-formes, en tenant compte du fait qu’une fois installé, il faut configurer Ambari avec : ambari-server setup
Maintenant, nous devons noter qu’Ambari installera et utilisera également le package de base de données PostgreSQL par défaut. Mais, si vous avez déjà votre propre serveur de base de données, vous pouvez vous assurer de saisir les paramètres avancés de la base de données, lorsque vous y êtes invité. Ainsi, une fois configuré, démarrez le serveur avec :service ambari-server start
Par contre, pour se connecter au tableau de bord Ambari, il faut pointer vers votre navigateur AmbariHost:8080 et accéder avec l’utilisateur admin, d’une part, et le mot de passe admin, d’autre part, les deux par défaut. Une fois que vous êtes connectés, vous recevrez un modèle similaire à celui que nous verrons ci-dessous :
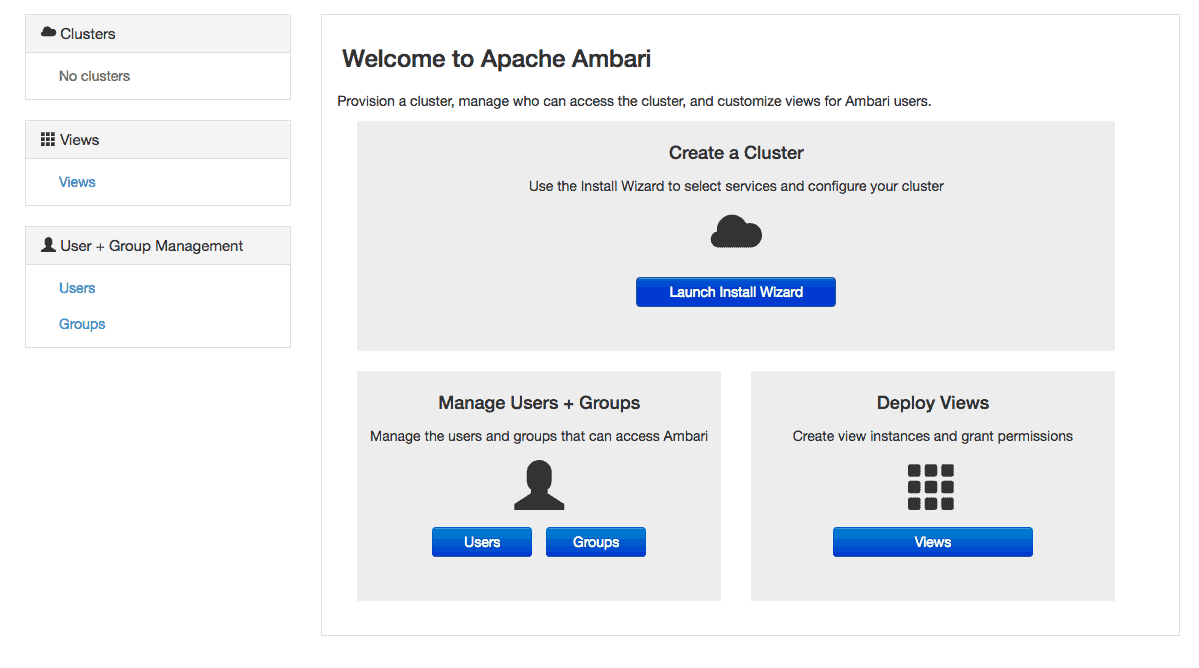
Voyons donc, et en nous basant sur l’image précédente, comment procéder : pour commencer, sélectionnez « Démarrer l’assistant d’installation ». Ensuite, dans la série d’écrans qui suivent, les hôtes se verront demander les informations d’identification pour se connecter à chaque hôte du grappe. Ensuite, il leur sera demandé de configurer les paramètres spécifiques à l’application. En ce qui concerne ce sujet des paramètres de configuration, vous devez garder à l’esprit que les détails seront spécifiques à votre propre implémentation et aux services utilisés.
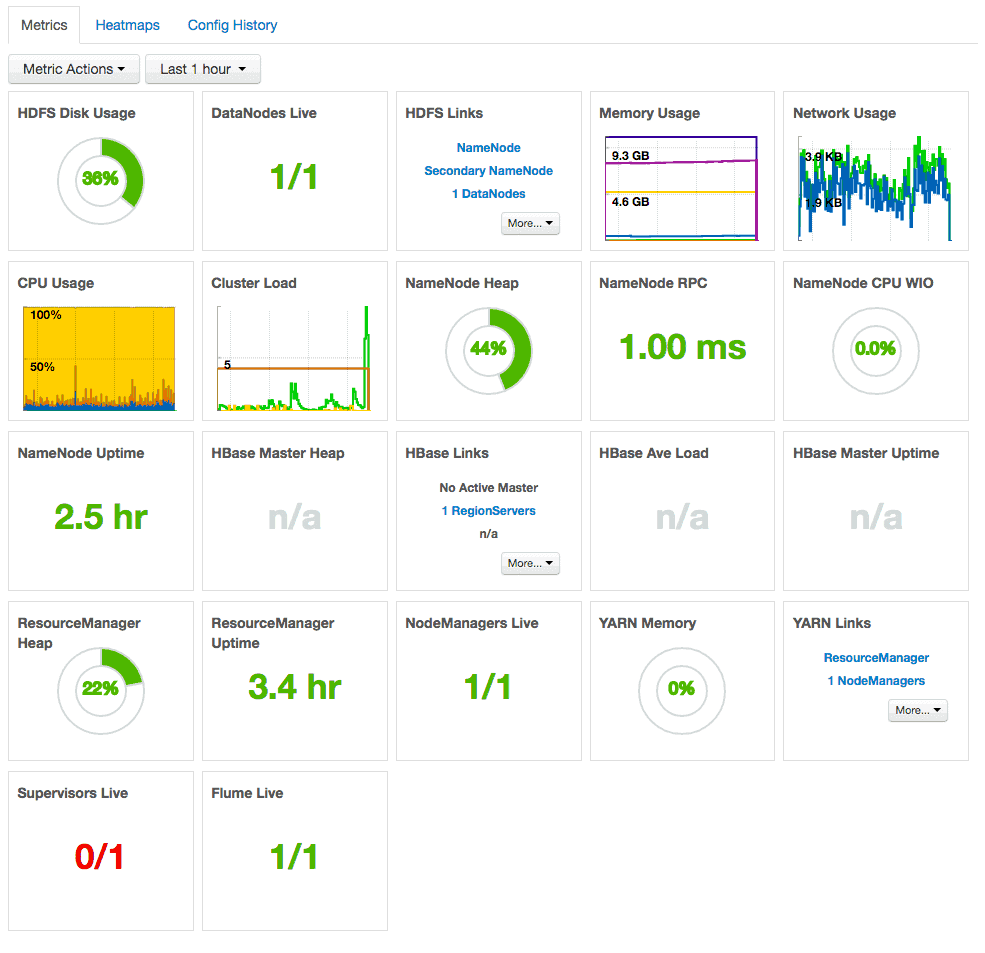
Une fois que tout cela aura été vérifié, vous disposerez d’un tableau de bord détaillé contenant des informations sur les performances et l’état de santé du grappe. De plus, vous serez informés de son état de santé et des liens permettant de vous connecter au réseau d’interfaces utilisateur, pour des éléments spécifiques tels que NameNode et ResourceManager.
Cloudera Manager
Un autre outil tiers est Cloudera Manager, qui est une méthode de gestion de grappe qui doit être livrée dans le cadre de la distribution commerciale Hadoop de Cloudera, mais est également disponible en téléchargement gratuit. Dans le cas de cet outil, une fois que vous avez téléchargé et installé les packages d’installation respectifs et, en plus, vous avez configuré une base de données pour Cloudera Manager, vous devez démarrer le serveur avec :
service cloudera-scm-server start
Pour finir, vous pouvez entrer Pandora FMS ou, alternativement, au blog où vous trouverez tout ce qui concerne la supervision de, pratiquement tout ce qui a à voir avec des sujets similaires aux nôtres. Ce n’est plus le moment de continuer à recourir à des explications extrêmement complexes, qui prolifèrent sur internet.
Rodrigo Giraldo, rédacteur technique indépendant. Avocat et étudiant en astrobiologie, il est passionné d’informatique, de lecture et de recherche scientifique.







