








Uso de Disco Rígido; monitorización desde el punto de vista cuantitativo
Recuerdo con cierta nostalgia los discos flexibles de cinco y un cuarto de pulgada, y luego los más robustos de tres y medio. Ya ni debería escribir la palabra rígido, pero me habéis pillado; es para que los más jóvenes pregunten: “Pero cuántos tipos de disco hay?”. O incluso, con el advenimiento de las Unidades de Estado Sólido (SSD): “¿Qué es un disco?”. Lo cierto es que la capacidad de almacenamiento es indetenible, llegando incluso al orden de los petabytes, por lo que necesitamos la monitorización para llevar cuenta de tan monstruosas cifras. Veamos.
Ocho bits hacen un byte y 1024 de ellos hacen un kibibyte
¿A que os he sorprendido? ¿A dónde ha ido la palabra kilobyte? Históricamente, en informática hemos cometido serios errores como acortar los años a dos cifras, o considerar que un kilobyte son mil bytes cuando en realidad son 1024. ¿Qué diferencia hacen 24 contra mil? “Son casi lo mismo”, me dicen. Pero ahora que los dispositivos de almacenamiento son gigantescos se comienzan a ver grandes diferencias.
Os explico (esto es necesario para comprender el software que veremos): un terabyte, o mejor dicho, un tebibyte, son exactamente:
1 099 511 627 776 bytes
Como sabemos, el prefijo tera indica un billón, un uno seguido por doce ceros, pero en este caso es 2⁴⁰ bytes. Rápidamente notamos ¡que tenemos cerca de cien millardos de bytes adicionales en vez de lo que habíamos pensado!
Pongámonos en perspectiva: los discos flexibles que usamos de 3½ tenían capacidad para guardar 1 474 560 letras (un byte por letra, ahora con Unicode UTF-8 esto varía según el idioma): ¡un tebibyte son poco más de 745 654 discos flexibles!
Almacenamiento en disco
Guardar y leer los ficheros tiene analogía con un libro: el índice indica dónde comienza y termina cada capítulo, sección o incluso un párrafo en particular, imágenes, prólogo, tablas, etc. Mientras más grande el libro (disco), más grande el índice (Tabla de Asignación de Archivos o FAT). Y aquí viene el caso que nos ocupa: ¿Cómo lidiar con millones de archivos?
Supongamos que tenemos 500 millones de archivos y necesitamos conocer dónde está ubicado uno en particular; por ejemplo, uno donde se guardan determinados registros de eventos. El software libre permite modificar y que guardemos donde mejor convenga, así que aunque las aplicaciones generalmente tienen ubicaciones predeterminadas, no siempre se siguen las reglas. ¿Qué tal si decenas de fotógrafos guardan cada uno en un sistema de almacenamiento masivo sus trabajos? Los nombres de ficheros serán muy parecidos, incluso las aplicaciones con búsqueda de archivos repetidos por nombre darán falsos positivos.
Otro problema es cómo se guardan los ficheros: generalmente en racimos de 4096 bytes (8 sectores de 512 bytes), así que un archivo de 4296 bytes en realidad ocupa 8192 en disco… ¿Cuánto «desperdiciamos»?
Herramienta duc
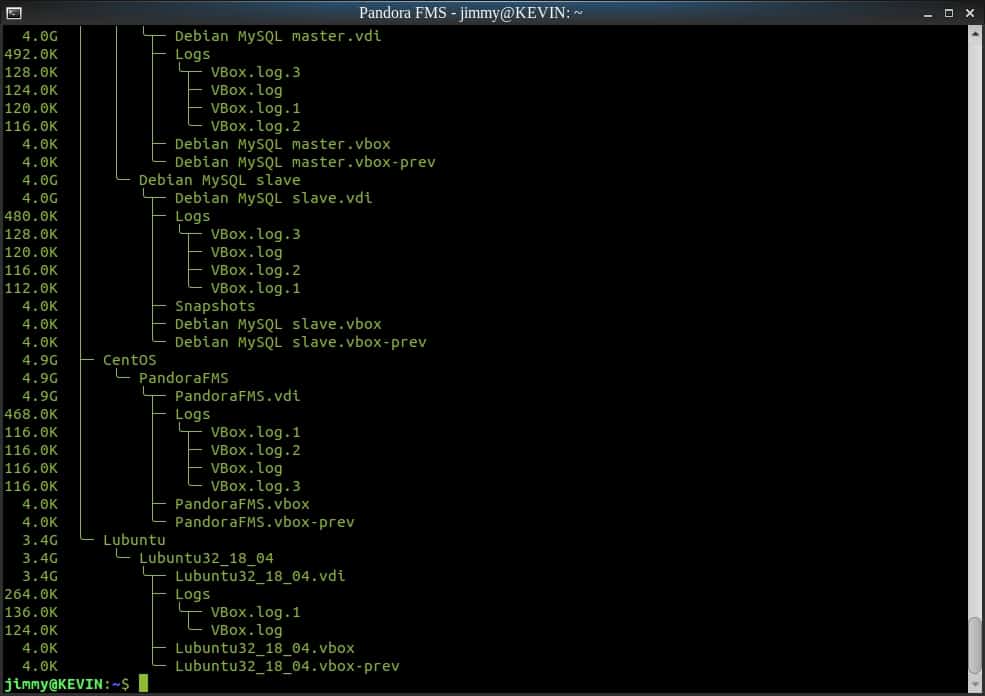
Leyenda: Herramienta duc vista de árbol de un catálogo
Para esto, y más, una herramienta comprobada para trabajar con tal cantidad de datos es duc. Es capaz de reportarnos en formato XML (uno de los tantos formatos utilizados por Pandora FMS para importar y/o exportar datos) cuánto ocupa cada fichero de «forma aparente» y de «forma real». La forma real son los sectores usados: a mayor cantidad de ficheros pequeños, mayor espacio «desperdiciado». Pero, ¿cómo trabaja duc?
duc utiliza una base de datos muy primigenia llamada Tokyo Cabinet (actualmente hay una versión mejorada llamada Kyoto Cabinet) escrita en lenguaje C, con variables de 64 bits y con alta resistencia a la corrupción de datos. Pero, como decían los antiguos comerciales de televisión, «esperen, hay más»: ahorra espacio al comprimir sobre la marcha sin desmedro de velocidad, soporta multiprocesos y tiene opciones tales como escoger o excluir los tipos de sistema de archivo (.ext4, btrfs, etc.).
De esta manera, duc puede comenzar a indexar nuestros discos rápidamente y luego mantener actualizados y a la mano cientos de millones de registros en cuantos catálogos (bases de datos Tokyo Cabinet) necesitemos. Deberemos, con cron, mantener actualizados dicho(s) catalogo(s) para poder retribuir datos para su posterior monitorización.
Aparte de exportar en formato XML, también dispone de varias interfaces gráficas e incluso puede servir CGI en un servidor web Apache, permitiendo CSS personalizado por nosotros, si queremos.
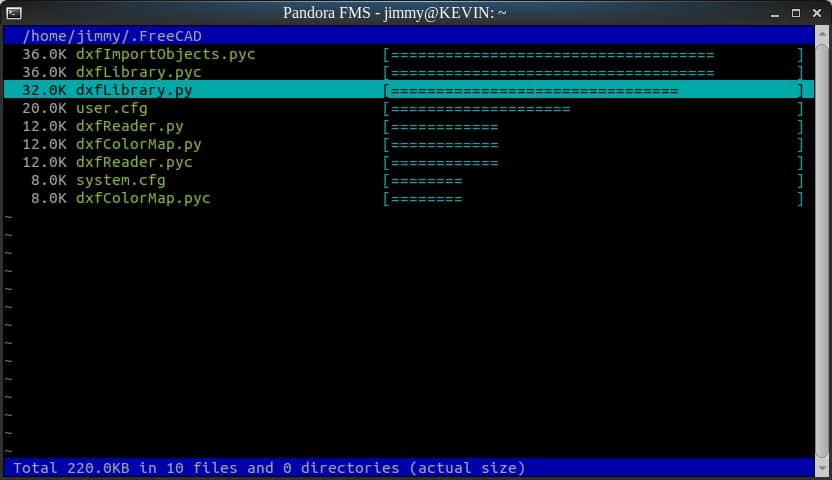
Leyenda: Herramienta duc por terminal de comandos
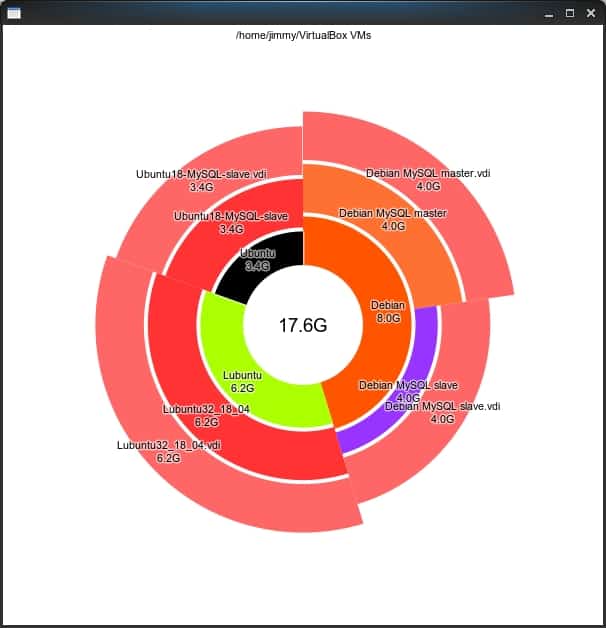
Leyenda: Herramienta duc en modo gráfico, escritorio de usuario
Herramienta stat
Un comando que viene en la mayoría de las distribuciones Linux, y que podremos incluso integrarlo a duc (es más fácil decirlo que programarlo) es stat, el cual nos retribuye rápidamente el propietario, las fechas de creación, acceso, modificación y cambio de estado. Para ello emplearemos el parámetro –format= acompañado de %U, %X, %Y y %Z (formato Epoch y listo para guardar en la base de datos para su monitorización). Deberemos esperar que los sistemas de archivos ofrezcan soporte para la fecha de creación; todo depende de la distro utilizada.
Son muchas las razones para hacer seguimiento a ciertos directorios o ficheros, muy alejados de la privacidad de los usuarios, porque cada aplicación crea sus usuarios virtuales y sus correspondientes ficheros. Si necesitamos conocer en tiempo real los cambios, adicionaremos a nuestro código la librería inode notify (inotify) y el propio kernel del sistema operativo nos ayudará en ese aspecto.
Herramienta duff
Aquí sí que deberemos instalar en nuestros sistemas Linux, ya sea con yum, apt, snap, etc., para poder tener este programa auxiliar en nuestro arsenal. Se encarga de buscar los ficheros «repetidos» con la particular característica de que crea un trozo de información virtualmente única («hash») para cada fichero. Esto crea una huella prácticamente única basada en el contenido del archivo: con un solo byte que cambie obtendremos un hash diferente, por lo que los hash son útiles para crear catálogos de respaldos «en la nube».
Así podremos saber a ciencia cierta si dos ficheros, a pesar de tener diferentes nombres, fechas, etc., tienen el mismo contenido (la posibilidad de que tengan diferente contenido con el mismo hash es una entre muchos millones -a eso se le denomina «colisión»-). Con duff podremos escoger niveles elevados de creación de hash, hasta SHA512 pero por defecto trabaja con SHA1.
Fíjense que aunque duff lee los ficheros en su totalidad, su contenido en sí mismo le tiene sin cuidado: para ello hay aplicaciones que buscan metadatos dentro de los documentos, ya sea basado en la extensión del archivo (ej. .odt, documento de texto; .xlsx, hoja de cálculo) o simplemente tanteando estructuras de datos conocidas contra el comienzo de cada fichero, si no tiene extensión o si la extensión no coincide con la estructura de datos.
Un paso más allá
Tenemos tiempo escuchando acerca de los sistemas operativos que utilizarán bases de datos como sistemas de archivos (OS-BD); es decir, el enfoque de duc pero combinado con stat y duff, además de los metadatos y datos clave dentro de los documentos, que estos dejarían de llamarse ficheros sino simplemente documentos. Por supuesto que los sistemas de archivos seguirán existiendo: si un usuario saca de su OS-BD en una unidad de almacenamiento externo lo más recomendable es sacarlo como fichero, porque desconocemos si el otro OS maneja tal tipo de base de datos (aunque con el software libre esto es subsanable rápidamente si se cuenta con conexión a Internet). Pandora FMS está más que preparado para monitorizar bases de datos, y de hecho su funcionamiento está basado en su uso intensivo.
Pandora FMS es un software de monitorización flexible, capaz de monitorizar dispositivos, infraestructuras, aplicaciones, servicios y procesos de negocio.
¿Quieres conocer mejor qué es lo que Pandora FMS puede ofrecerte? Descúbrelo entrando aquí.
Si cuentas con más de 100 dispositivos para monitorizar puedes contactar con el equipo de Pandora FMS a través del siguiente formulario.
Además, recuerda que si tus necesidades de monitorización son más limitadas tienes a tu disposición la versión OpenSource de Pandora FMS. Encuentra más información aquí.
No dudes en enviar tus consultas. ¡El equipo de Pandora FMS estará encantado de atenderte!

Programador desde 1993 en KS7000.net.ve (desde 2014 soluciones en software libre para farmacias comerciales en Venezuela). Escribe regularmente para Pandora FMS y ofrece consejos en el foro. También colaborador entusiasta en Wikipedia y Wikidata. Machacador de hierros en gimnasios y cuando puede se ejercita en ciclismo también. Fanático de la ciencia ficción. Programmer since 1993 in KS7000.net.ve (since 2014 free software solutions for commercial pharmacies in Venezuela). He writes regularly for Pandora FMS and offers advice in the forum. Also an enthusiastic contributor to Wikipedia and Wikidata. Crusher of irons in gyms and when he can he exercises in cycling as well. Science fiction fan.









