






Fixed Disk Usage should be monitored from a quantitative point of view
I remember with some nostalgia the five-and-a-quarter-inch floppy disks, and then the more robust three-and-a-half-inch floppy disks. I shouldn’t even write the word rigid anymore, but you’ve got me: it’s for younger people to ask: “But how many kinds of disk are there? Or even, with the advent of Solid State Drives (SSD): “What is a fixed disk?” The truth is that the storage capacity is unstoppable, even reaching the petabytes level, so we need monitoring to keep track of such huge numbers. Let’s have a look at fixed disk usage!
Eight bits make a byte and 1024 of them make a kibibyte. Fixed Disk Usage
I surprised you, didn’t I? Where did the word kilobyte go? Historically, in computing history we have made serious mistakes such as shortening the years to two figures, or considering that a kilobyte is a thousand bytes when in reality it is 1024. What difference does 24 make against a thousand? “They are almost the same”, they say. But now that the storage devices are gigantic, we are beginning to see big differences.
A terabyte, or rather, a tebibyte, is exactly:
1 099 511 627 776 bytes
The prefix tera indicates one billion, one followed by twelve zeros, but in this case it is 2⁴⁰ bytes. We quickly noticed that we have about a hundred billion additional bytes instead of what we thought!
Let’s put it in perspective: the floppy disks we used from 3½ were able to store 1 474 560 letters (one byte per letter, now with Unicode UTF-8 this varies depending on the language): a tebibyte is just over 745 654 floppy disks!
Fixed Disk Usage Storage
Saving and reading files is analogous: the index indicates where each chapter, section or even a particular paragraph begins and ends, images, prologue, tables, etc. The larger the disk, the larger the index (File Assignment Table or FAT). And here’s the case: How to deal with millions of files?
Let’s suppose we have 500 million files and need to know where a particular file is located; for example, one where certain event records are kept. Free software allows you to modify and save where it suits you best, so even though applications generally have default locations, the rules are not always followed. What if dozens of photographers each save their work in a mass storage system? File names will be very similar, even applications with repeated file searches by name will give false positives.
Another problem is how files are stored: usually in clusters of 4096 bytes (8 sectors of 512 bytes), so a 4296 bytes file actually occupies 8192 on disk… How much is ” wasted “?
Tool duc
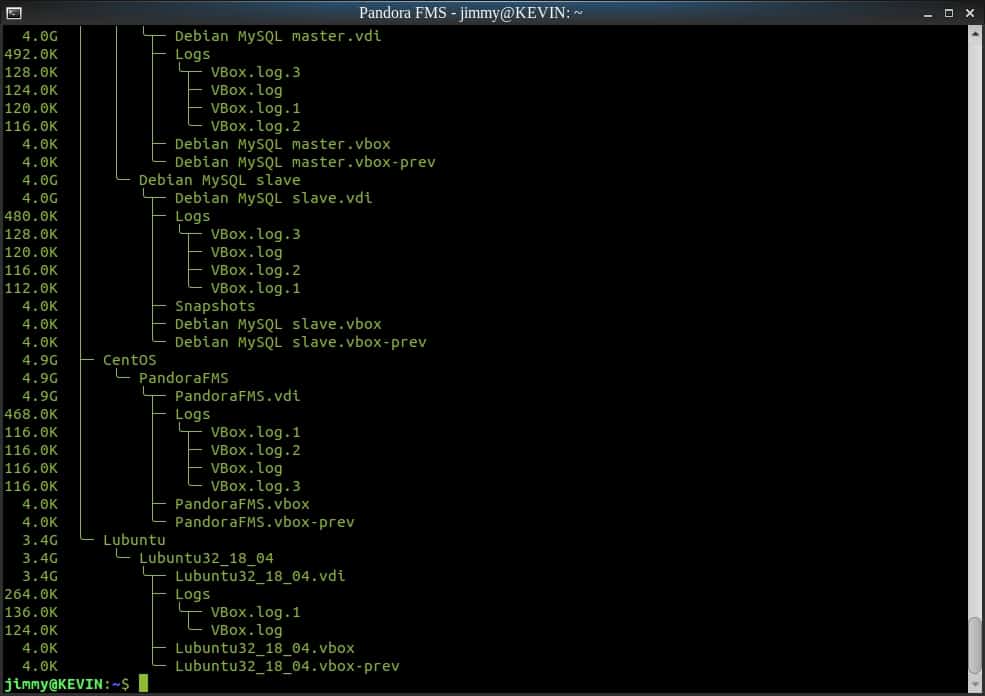
Description: Tool duc tree view of a catalog
A proven tool for working with such a large amount of data is duc. It is able to report in XML format (one of the many formats used by Pandora FMS to import and/or export data) how much each file occupies. The real shape is the sectors used: the more small files, the more “wasted” space. But how does duc work?
duc uses a very primitive database called Tokyo Cabinet (currently there is an improved version called Kyoto Cabinet) written in C language, with 64-bit variables and high resistance to data corruption. But, as the old TV commercials used to say, “wait, there’s more”: it saves space by compressing on the fly with no loss of speed, it supports multiprocesses and has options such as choosing or excluding file system types (.ext4, btrfs, etc. ).
This way, duc can start indexing our disks quickly and then keep hundreds of millions of records in as many catalogues (Tokyo Cabinet databases) as we need. We must, with cron, keep this catalogue(s) updated in order to pay for data for subsequent monitoring.
Apart from exporting in XML format, it also has several graphical interfaces and can even serve CGI on an Apache web server, allowing custom CSS for us, if we want.
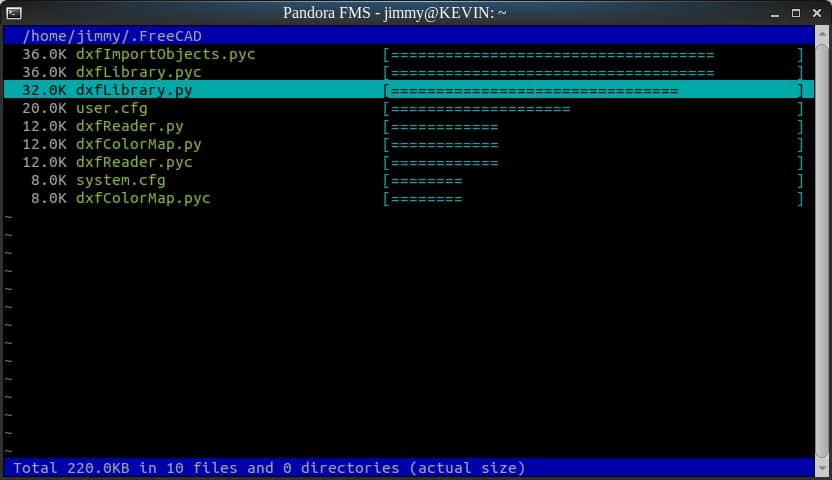
Description: Tool duc per command terminal
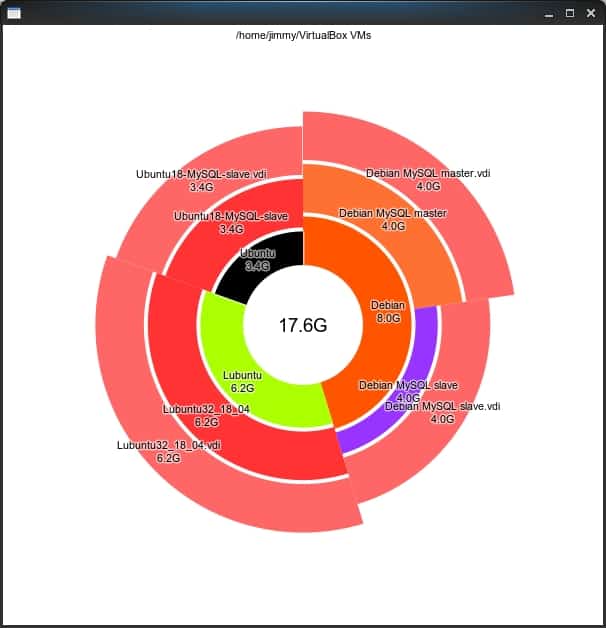
Caption: duc tool in graphical mode, user desktop
Stat tool
A command that comes in most Linux distributions, and that we will even be able to integrate to duc (it is easier said than to program it) is stat, the dates of creation, access, modification and change of state. To do this we will use the parameter –format= accompanied by %U, %X, %Y and %Z (Epoch format and ready to save in the database for monitoring). We will have to wait for file systems to support the creation date; it all depends on the distro used.
There are many reasons to keep track of certain directories or files, very far from the privacy of users, because each application creates its virtual users and their corresponding files. If we need to know in real time the changes, we will add to our code the inode notify library (inotify) and the kernel of the operating system itself will help us in that aspect.
duff tool
Here we will have to install in our Linux systems, either with yum, apt, snap, etc., to be able to have this auxiliary program in our arsenal. It searches for “repeated” files with the particular characteristic that it creates a virtually unique piece of information (“hash”) for each file. This creates a virtually unique footprint based on the content of the file: with a single byte that changes we’ll get a different hash, so hashes are useful for creating backup catalogs “in the cloud”.
So we can know for sure if two files, despite having different names, dates, etc., have the same content (the possibility that they have different content with the same hash is one among many millions – that is called a “collision”-). With duff we will be able to choose high levels of hash creation, up to SHA512 but by default it works with SHA1.
Although duff reads files in their entirety, its content itself is careless: there are applications that search for metadata within documents, either based on the file extension (e.g. .odt, text document; .xlsx, spreadsheet) or simply by testing known data structures against the beginning of each file, if it does not have an extension or if the extension does not match the data structure.
A step beyond on fixed disk usage
We have been hearing about the operating systems that will use databases as file systems (OS-BD); that is, the duc approach but combined with stat and duff, as well as the metadata and key data within the documents, which would no longer be called files but simply documents. Of course, file systems will continue to exist: if a user removes his OS-BD on an external storage unit, we have to remove it as a file, because we do not know if the other OS handles such a database type (although with free software this is quickly done if you have an Internet connection). Pandora FMS is quite ready to monitor databases, and in fact its operation is based on its intensive use.
Pandora FMS is a flexible monitoring software, capable of monitoring devices, infrastructures, applications, services and business processes.
Do you want to know better what Pandora FMS can offer you? Find out here.
If you have more than 100 devices to monitor you can contact the Pandora FMS team through the following form.
Also, remember that if your monitoring needs are more limited you have at your disposal the OpenSource version of Pandora FMS. Find more information here.
Don’t hesitate to send us your questions. Our Pandora FMS team will be delighted to help you!
Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring. Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring.








