








Monitorizar hadoop en código abierto ya es posible con este tutorial
Antes de entender cómo se debe monitorizar Hadoop (dentro del ámbito del código abierto), es preciso hacer una brevísima exposición de lo que es Hadoop, para ver que tiene una íntima relación con Big Data y además, de como manejar las enormes cantidades de datos. Para comenzar, digamos que los inconvenientes radican no solamente en la cantidad sino, también, en la heterogeneidad de los datos. En otras palabras y para ser más explícitos, es preciso tener en consideración que los problemas se presentan por la cantidad, con heterogeneidad.
A propósito de la heterogeneidad de los grandes datos, debemos tener en cuenta que hay tres tipos: La estructurada, semi-estructurada y la no estructurada. Anotemos que el sistema HDFS (Sistema Gestor de Bases de Datos Relacionales) se basa en datos estructurados, como en el sensible caso de las transacciones bancarias y de los datos operacionales, entre otros. Entonces, Hadoop se centra (y se especializa) en datos semi-estructurados y en los que son estructurados como texto, publicaciones de Facebook, audios, videos, registros y demás.
Por otro lado, anotemos que la tecnología del sistema Hadoop se ha desarrollado y se encuentra en un interesante nivel de demanda gracias a Big Data que, en su mayor parte, consiste en datos no estructurados y en diferentes formatos. Ahora, el principal problema consiste en el almacenamiento de colosales cantidades de datos, en vista de que no es posible almacenarlos en su sistema tradicional.
El segundo problema consiste en que el almacenamiento de datos heterogéneos es complejo. El almacenamiento es sólo una parte de un problema, ya que la cantidad de los datos no sólo es enorme sino que, también, se le encuentra en variados formatos. En tal virtud, es necesario el que nos cercioremos de que contamos con un sistema para almacenar esta heterogeneidad de datos, que se generan desde diversas fuentes.
El tercer problema a analizar, se trata del acceso y la velocidad de procesamiento. La capacidad de los discos duros está aumentando incuestionablemente, aunque la velocidad de transferencia de los mismos y la velocidad de acceso, no están aumentando con la misma rapidez. Veamos un ejemplo ilustrativo:
En caso de que sólo contemos con un canal de E/S de 100mbps y que, además, se encuentre procesando 1 TB de datos, el proceso mismo podría tardar casi tres horas (2,90 horas). Si contamos con unas cuatro máquinas, con cuatro canales de E/S para la misma cantidad de datos, esto es, 1 TB, el proceso “sólo” tardará unos 43 minutos, en este caso. Mediante la presentación de este simple (pero ilustrativo) ejemplo, nos damos cuenta, de inmediato, la importancia que implica saber cómo monitorizar Hadoop.
Para entrar en materia, comencemos por decir que existen muchas herramientas para analizar y optimizar el rendimiento de un clúster de Hadoop, tanto de código abierto, gratuito (pero de código cerrado), como de tipo comercial. Ahora, para los efectos que nos interesan particularmente, haremos alusión a las herramientas de código abierto. Resulta que cada componente de Hadoop (cuando se trata de código abierto, reiteramos) viene empaquetado con su respectiva interfaz administrativa que, justo es decirlo, puede utilizarse para recopilar métricas de rendimiento de todo el clúster.
Sin embargo y desafortunadamente, añadir dichas métricas para la correlación de fuentes múltiples y dispares, es ya de por sí un reto en sí mismo considerado. Pero, usted mismo puede hacerlo, mediante una guía que le presentaremos con la mayor claridad posible. Se trata, para más señas, de una guía para recopilar métricas de rendimiento de HDFS, YARN y de MapReduce, haciendo uso de las API HTTP expuestas para cada tecnología. Aclaremos, de paso, que una gran oferta de código abierto para la gestión de Hadoop y análisis de rendimiento, es el Proyecto Apache Ambari, que les brinda a los usuarios una interfaz gráfica que se encuentra bastante bien diseñada para la gestión de clústeres.
En otras palabras, digamos que en una sola interfaz, puede proporcionar, administrar y supervisar clústeres de miles de máquinas. Así las cosas, podemos anotar (sin temor a equivocaciones, ni a necias exageraciones) que se trata de una excelente herramienta para trabajar y, de paso, para monitorizar Hadoop. Veamos, entonces, cómo es que podemos recopilar métricas de Hadoop, para destacar, inicialmente, que nos enfocaremos en la monitorización de la “salud” y del desempeño de Hadoop, que brinda una amplia y variada gama de métricas sobre el rendimiento de la ejecución de trabajos, la salud y la utilización de recursos.
Durante la presente exposición, le diremos al lector cómo es que deberá recopilar métricas de los componentes más importantes de Hadoop, como es el caso de HDFS, YARN y MapReduce pero, eso sí, utilizando herramientas de desarrollo estándar, además de otras herramientas especializadas como Cloudera Manager y Apache Ambari.
La recopilación de métricas HDFS
HDFS emite métricas de dos fuentes
Los DataNodes y el Name Node que, en su mayor parte, cada una de estas dos métricas debe ser recogida en sus respectivos puntos de origen. Las dos fuentes anteriores emiten métricas mediante una interfaz HTTP y, también, a través de JMX. Así las cosas, nos enfocaremos en los siguientes tres temas, sin desentendernos de otros que también desarrollaremos en menor medida:
- Recopilación de métricas de NameNode a través de API.
- Recopilación de métricas de DataNode a través de API.
- Recopilación de métricas HDFS a través de JMX.
API de HTTP de NameNode
Resulta que NameNode brinda un resumen de las métricas de rendimiento y salud, mediante una interfaz de usuario web. Esa interfaz de usuario es accesible a través del puerto 50070, por lo que debemos apuntar un navegador web a: http://namenodehost:50070
Si bien es cierto que es aconsejable y cómodo disponer de un resumen, es posible que algunos (o muchos) lectores pretendan profundizar en algunas otras métricas, por lo que les sugerimos que, para apreciarlas todas, apunten su navegador a htpp://namenodehost:50070/jmx
Así si utilizamos la API o, bien, JMX, luego podremos encontrar una especie de “segunda parte” en MBean Hadoop:name=NameNode. VolumeFailtures Total.
En lo que respecta, esta vez, a NumDeadDataNodes, a NumLiveDataNodes, a NumLiveDecomDataNodes y a NumStaleDataNodes, tenemos que se pueden encontrar bajo el MBean Hadoop:name=FSNamesystemState,service=NameNode.
API HTTP de DataNode
Una visión general de la integridad de sus DataNodes, se encuentra disponible y a entera disposición de los usuarios en el panel de NameNode, bajo la pestaña denominada “Datanodes” (http://localhost:50070/dfshealth.html#tab-datanode). Sin embargo, con el fin de conseguir una vista mucho más detallada de un DataNode individual, es posible acceder a sus métricas mediante el DataNode API.
Ahora, para conseguir una vista y una visión más detallada de un DataNode individual, podremos acceder a nuestras métricas a través de DataNode API. De una manera predeterminada, DataNodes expone absolutamente todas sus métricas en el puerto 50075, a través de jmx. No parece, en un principio, muy ortodoxa la manera en que acabamos de escribir este apartado sobre JMX, pero es necesario hacerlo de cara a que el lector tenga una claridad absoluta y, de paso, para que nadie se equivoque. Por ejemplo en el caso de colocar jmx., la situación podría dar lugar a malos entendidos. Como bien nos dicen en Pandora FMS, “… un sistema de monitorización debe ser simple y sin embargo eficaz”.
Por otro lado, aclaremos que el hecho de golpear este punto extremo en su DataNode con su navegador o curl, nos proporciona todas las métricas en esta especie de segunda parte de esta serie. Veamos a continuación, lo referente a las métricas NameNode y DataNode a través de JMX, para ir completando la serie y, muy importante, de cara a seguir exponiendo el tema mediante una secuencia lógica de conceptos.
Métricas NameNode y DataNode mediante (o “a través de”) JMX
De la misma manera en que lo hace Kafka, Cassandra y otros sistemas fundamentados en Java, también exponen métricas mediante JMX, tanto en DataNode como en NameNode. Entonces, las interfaces de agente remoto de JMX, se encuentran desactivadas de forma predeterminada. Debido a esto, es preciso habilitarlas, estableciendo las siguientes opciones de JVM en hadoop-env.sh que, normalmente, son encontradas en $HADOOP_HOME/conf . Otra aclaración ortográfica, la debemos plantear en este apartado de la exposición: obsérvese que el “punto seguido” anterior fue ubicado separadamente de la palabra “conf”. Veamos, ahora sí:
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote
Dcom.sun.management.jmxremote.password.file=$HADOOP_HOME/conf/jmxremote.password-Dcom.sun.management.jmxremote.ssl=false
Dcom.sun.management.jmxremote.port=8004 $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote
Dcom.sun.management.jmxremote.password.file=$HADOOP_HOME/conf/jmxremote.password
Dcom.sun.management.jmxremote.ssl=false
Dcom.sun.management.jmxremote.port=8008 $HADOOP_DATANODE_OPTS"
La anterior configuración, obtenida de https://goo.gl/D9DAeK, va a abrir el puerto 8008 (en el DataNode) y el 8004 (en el NameNode). En ambos casos con la autenticación de la contraseña activada. A este respecto, sugerimos a los lectores consultar cómo configurar un entorno de usuario único, con la finalidad de contar con más información respecto de la manera de configurar el agente remoto JMX. Continuando con una secuencia lógica de la explicación, digamos que, una vez que se encuentre activada la contraseña, ya nos podremos conectar, mediante cualquier consola JMX como pueden ser, por ejemplo, JConsole o Jmxterm. La siguiente, es sólo un principio de conexión Jmxterm con el NameNode, teniendo en cuenta que existe una primera lista de MBeans disponibles y, luego, la perforación en el Hadoop:name=FSName,system,service=NameNodeMBean.
La recolección de contadores MapReduce
● Los contadores MapReduce: nos brindan información respecto de la ejecución de la tarea, precisamente, como el tiempo de CPU y, también, la memoria utilizada. Se deben descargar en la respectiva consola, al invocar trabajos de Hadoop desde la línea de comandos. Lo anterior, es ideal para efectos de la comprobación de puntos, a medida que se van ejecutando los trabajos. Eso sí: un análisis más detallado requiere de contadores de supervisión, a lo largo del tiempo.
● El ReduceManager, a su vez, también expone todo los contadores de MapReduce para cada uno de los puestos de trabajo. Entonces, para poder acceder a los contadores de MapReduce en nuestro ResourceManager, debemos navegar, primero, a la interfaz web de ResourceManager en htpp://resourcemanagerhost:80008 . Luego, podremos encontrar la aplicación que nos interesa para, luego, hacer clic en “Historial” que es una pestaña ubicada en la columna denominada “Seguimiento de la interfaz de usuario”.
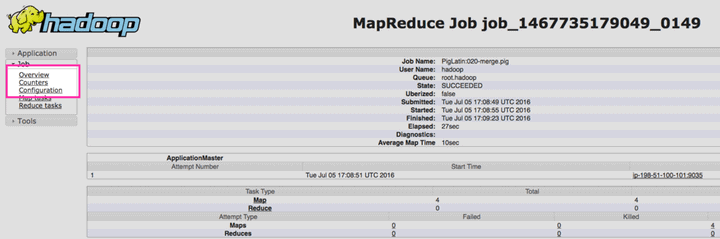
Debemos encontrar la aplicación que nos interesa y hacer clic en «Historial», en la columna “Seguimiento de la Interfaz de Usuario”. De cara a una mayor claridad, veamos una interesante imagen que nos podrá brindar mejores luces aún:

A continuación, esto es, en la página siguiente, debemos hacer clic en “Contadores”, que se encuentra en el menú de navegación de la izquierda, como lo podemos apreciar en la imagen siguiente que, al igual que la anterior, podrá ser agrandada por el lector.
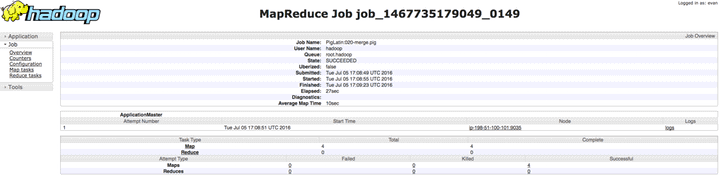
Por último (sólo de momento), debemos ver todos los contadores recopilados y asociados con el trabajo que hemos hecho y estamos haciendo:
La recopilación de métricas Hadoop YARN
API HTTP y YANR
YARN expone, de forma predeterminada, todas sus métricas en el puerto 98088, mediante el jmx punto final. Al golpear este punto final de API, YARN nos brinda todas las métricas para monitorizar Hadoop, en la segunda parte de esta serie. Al igual de lo que sucede con HDFS, cuando consultamos el punto final de JMX, este puede especificar MBeans mediante el qry parámetro, como lo vemos a continuación:
$ curl resourcemanagerhost:8000/jmx?qry=java.lang:type=Memory
Si lo que pretendemos, es sólo conseguir las métricas de la segunda parte de la serie, podemos consultar también el ws/v1/cluster/metrics endpoint.
Las herramientas de terceros
Los métodos de recopilación nativa son útiles, en lo que respecta a la medición de la verificación puntual o, lo que es lo mismo, de un solo tajo. Sin embargo de lo anterior y con la finalidad de poder ver la imagen grande (que es lo adecuado y deseable), es necesario recopilar y añadir métricas en todos los sistemas, para efectos de establecer una necesaria correlación. Entonces, dos proyectos muy importantes, esto es, Cloudera Manager y Apache Ambari, nos brindan a los usuarios una plataforma unificada para efectos de la administración, la monitorización y de la gestión de Hadoop.
Estos dos proyectos nos proporcionan herramientas que nos sirven para la recopilación y visualización de métricas Hadoop y, también, algunas otras herramientas para efectuar tareas comunes de solución de problemas.
Apache Ambari
El objetivo de este proyecto, es el de facilitar la gestión de clústeres Hadoop mediante la creación de software, con el fin de lograr el aprovisionamiento, la gestión y, también, la supervisión de los clústeres Apache Hadoop. Se trata, indudablemente, de una excelente herramienta para administrar el clúster y, como ya lo anotamos, para su supervisión o monitorización. Veamos, a continuación, una instrucción para la instalación en varias plataformas, teniendo en consideración que, una vez instalado, debemos configurar Ambari con: ambari-server setup
Ahora, debemos tener en cuenta que Ambari instalará y, también, utilizará el paquete de base de datos PostgreSQL de manera predeterminada. Pero, si ya tenemos nuestro propio servidor de base de datos, nos podemos cerciorar (y asegurar) de introducir la configuración avanzada de la base de datos, cuando se nos solicite. Entonces, una vez se encuentre configurado, iniciamos el servidor con:service ambari-server start
De otro lado, para conectarnos al tablero de Ambari, debemos señalar nuestro navegador AmbariHost:8080 y proceder a ingresar con el usuario admin, de un lado, y la contraseña admin, de otra parte, ambos predeterminados. Una vez que estemos conectados, recibiremos una plantilla que es similar a la que veremos a continuación:
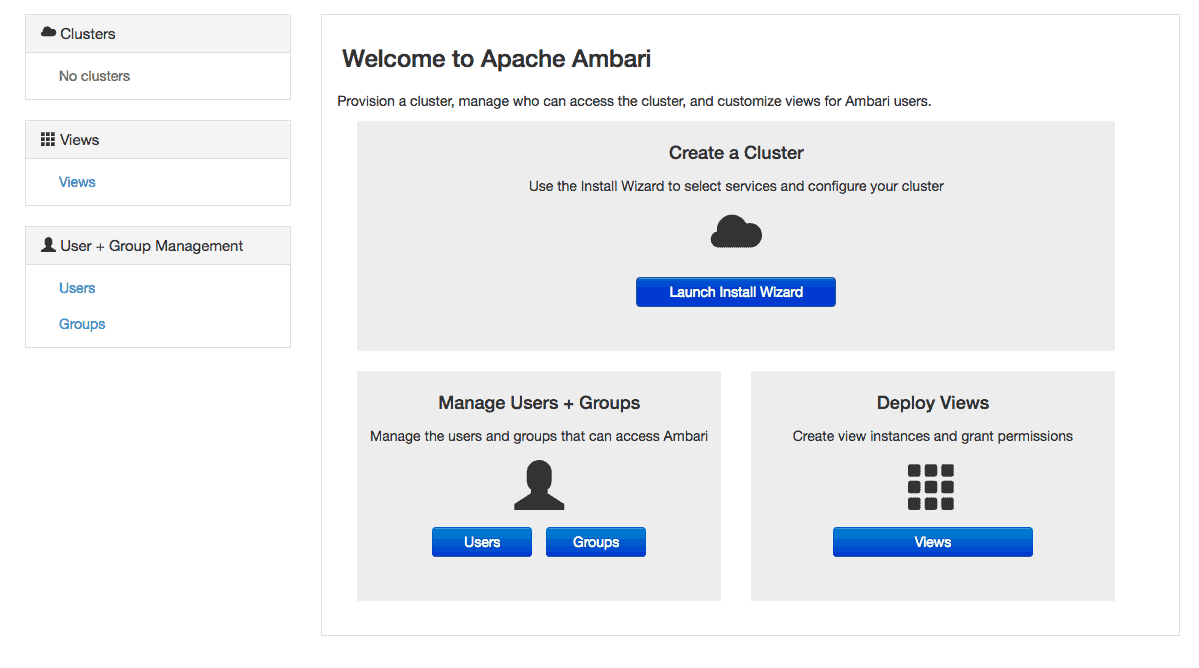
Veamos, entonces, y con base en la imagen anterior, cómo es que debemos proceder: para comenzar, seleccionamos “Iniciar Asistente de Instalación”. Luego, en la serie de pantallas que siguen, se les pedirá a los anfitriones las credenciales para conectarse a cada host del clúster. Luego, se les pedirá que configuren los parámetros específicos de la aplicación. A propósito de este tema de los parámetros de configuración, debemos tener en cuenta que los detalles de esta serán específicos de su propia implementación y de los servicios que se utilicen.
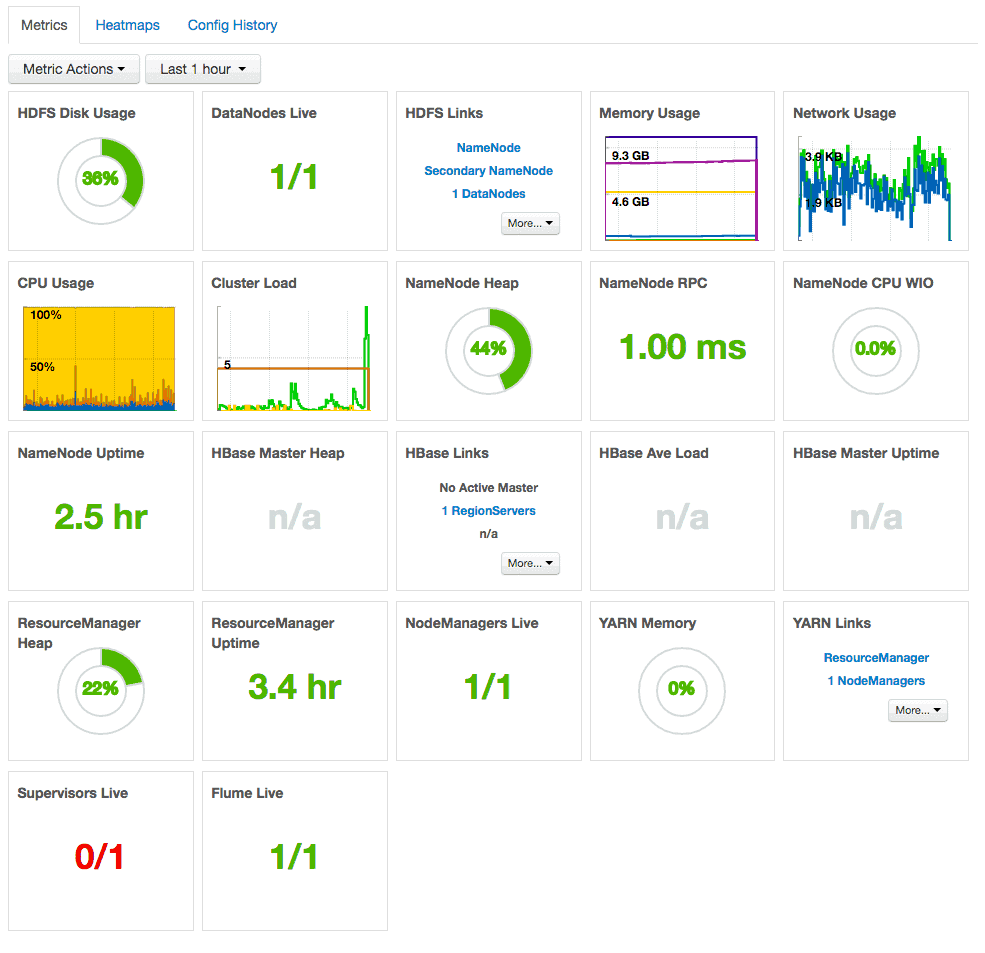
Una vez que todo esto se haya verificado, tendremos un panel de control detallado, que cuenta con información sobre el rendimiento y la salud en todo el clúster. Además, se nos informará sobre sobre la salud del mismo y acerca de los enlaces para que nos conectemos a la red de interfaces de usuario, para elementos específicos como NameNode y ResourceManager.
Cloudera Manager
Otra herramienta de terceros, es Cloudera Manager que es un método de administración de clústeres que se debe enviar como parte de la distribución comercial de Hadoop de Cloudera, pero que también se encuentra disponible como descarga gratuita. Para el caso de esta herramienta, tenemos que una vez que hayamos descargado e instalado los respectivos paquetes de instalación y que, además, hayamos configurado una base de datos para Cloudera Manager, debemos iniciar el servidor con:
service cloudera-scm-server start
Por último, si necesita más información, puede visitar la web de Pandora FMS, donde encontrará todo lo relacionado con la monitorización.
Rodrigo Giraldo, redactor técnico freelance. Abogado y estudiante de astrobiología, le apasiona la informática, la lectura y la investigación científica.









