








Monitorización de páginas web: Herramientas para extraer valores
Pandora FMS y la monitorización de páginas web
Dentro de mis múltiples ocupaciones está también la de contribuir a editar la Wikipedia, y allí está un maravilloso artículo sobre Pandora FMS donde se afirma que podemos hacer una Monitorización de Páginas Web para extraer, por ejemplo, el valor de las acciones de Google y alertar si caen por debajo de cierta cifra. ¡Aún eso es cierto hoy en día, aunque muchas cosas han cambiado!
Una de las cosas que ha cambiado son las páginas web, de tener un contenido estático a un contenido dinámico con tecnologías sencillas como JavaScript y AJAX del lado del cliente y PHP y MySQL del lado del servidor. Sí, las bases de datos que en un principio usamos con HTML estático y desde donde introdujimos líneas de comandos para conectar a la base de datos, consultar un valor y devolverlo al navegante, todo con total transparencia al usuario.
Con este antiguo esquema era relativamente sencilla la Monitorización de Páginas Web, de manera tal de obtener un valor simplemente descargando el código HTML y buscando una subcadena y sacar un dato, que en nuestro caso lo usamos con propósito de emitir una alerta. Ahora tenemos, por ejemplo, el robusto WordPress –con el que escribimos estas líneas- y que utilizan el 40% de los blog web del mundo, cifra nada despreciable. WordPress ayudó a cambiar el paradigma al no necesitar de ningún fichero que guarde código HTML: todo se guarda en bases de datos, lo que nos trae muchísimos beneficios (y algunos inconvenientes a la hora de monitorizar).
¿Cómo sabremos si un artículo en WordPress ha cambiado? Para comenzar, los temas –apariencia, fuente de texto, colores, imágenes de logotipo, etcétera- de una página web pueden cambiar con increíble rapidez, sin contar que los márgenes del artículo pueden contener enlaces de publicidad o hacia otros artículos de la misma web. Cualquier estrategia de Monitorización de Páginas Web que vaya más allá de saber si el sitio web deseado está en línea se va abajo con este dinamismo.
Aunque existen servicios web, como la página InspecturlCom, que pueden buscar un nombre de variable JavaScript –por ejemplo- y que ya hacen el trabajo de extraer datos de cualquier URL en HTML, este artículo va de proponer el uso de herramientas modernas para el lenguaje Python y extraer datos a fin de hacer la Monitorización de Páginas Web con Pandora FMS (en un principio lo haremos de una página web cualquiera). Las herramientas son Beautiful Soup y HTTP Requests. Iremos de menos a más, simplificando muchísimo, pero os advertimos que no os dejéis llevar a creer que esto es fácil: la tecnología subyacente es abundante y os tomará tiempo instalarla y comprobar nuestro código. Si eres lector o lectora cuya profesión es la programación, hasta algún error nos encontraréis (y si queréis nos lo diréis en los comentarios, abajo).
Entorno de trabajo para la monitorización de páginas web
Sí, antes de hacer cualquier cosa os contamos que usamos Ubuntu 18 y como todas las distribuciones GNU/Linux trae al lenguaje Python por defecto. Os recomendamos usar Python 3, simplemente escribís el siguiente comando python3 en una ventana terminal y os dirá si lo tenéis instalado. Aunque no es absolutamente necesario, nosotros hicimos una máquina virtual con VirtualBox donde alojamos un servidor web Apache, desde donde vamos a alojar la página de prueba. Recordad que aunque la página web sea dinámica siempre estará escrita en HTML, el cual podemos almacenar y replicar como una página web estática con propósitos didácticos. Para descargar una página web cualquiera a nuestra máquina virtual con servidor web Apache echaremos mano del comando curl, y aunque no entraremos en mayores detalles en este punto, podréis siempre solicitar man curl para conocer el uso y sus múltiples opciones. Mirad la siguiente figura:
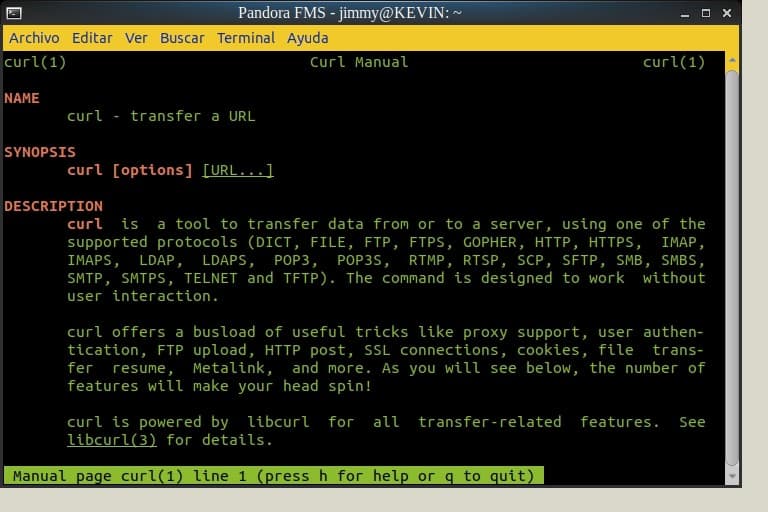
man curl (Licencia Creative Commons 3.0)
HTTP Requests
La primera herramienta que usaremos es HTTP for Humans™ o simplemente HTTP Requests, la cual es utilizada por empresas tales como Nike, Twitter, Microsoft, Amazon, Reddit, ¡y hasta por la Agencia Nacional de Seguridad estadounidense! Esto es así porque HTTP Requests está preparada para las modernas páginas web donde se necesita autenticación, mantener activa la conexión, datos persistentes en las sesiones –incluye galletitas-, soporte para servidores proxy, subidas fragmentadas de archivos, descompresión automática de contenido web y pare usted de contar.
Para resumir, diremos que cumple a cabalidad –y mucho más- las funciones de curl, pero con la potencia de Python, lenguaje con el cual nuestros guiones podrán llegar a muchas plataformas: Microsoft Windows®, GNU/Linux, Mac®, etcétera, y donde además podremos instalar un agente software de Pandora FMS para ejecutarlos y hacer posibles nuestras labores de monitorización.
No forma parte ni viene incluido en el paquete de instalación de Python, por lo que tendréis que instalarlo mediante el comando pip install requests. A su vez, la herramienta pip la podréis instalar con apt-get install pip (Debian y derivados). Os dijimos que tras la aparente sencillez de este artículo subyace trabajo y cierto grado de complejidad; ¡tomad un café mientras se instala!
Una vez instalado HTTP Requests, podremos lanzar una ventana terminal, invocar python3 para luego usarlo como librería con import requests. Observad el siguiente código:
Python 3.6.3 |Anaconda, Inc.| (default, Nov 20 2017, 20:41:42)
[GCC 7.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>> url = "http://192.168.1.60/bcv.html"
>>> pagina = requests.get(url)
>>> print(pagina.status_code)
200
>>> print(pagina.encoding)
ISO-8859-1
>>>
Como veis, podemos conocer si la descarga de la web fue válida, ya que guardamos el resultado en la variable llamada “pagina_web” y consultamos su status_code, que debe ser 2XX (otros valores como 4XX o 5XX significan errores y podremos adaptar nuestro guion para manejarlos). Notad que la dirección que almacenamos en la variable url es la máquina virtual que os comentamos. Dicha variable también la podemos pasar por argumento al ejecutar nuestro guion para añadir dinamismo a la monitorización (podría incluso leer de un fichero una lista de direcciones). Si necesitáramos autorización para descargar la página usaremos lo siguiente:
>>> pagina = requests.get(url, auth=(‘usuario’,’contraseña’))
Recomendamos no escribir nuestras credenciales en nuestros guiones. Existen librerías para Python que cifran en ficheros, desde donde las podemos guardar y utilizar en su debido momento; HTTP Request soporta HTTPS, por lo que nuestros datos viajarán seguros por Internet.
Beautiful Soup
En el libro Alicia en el País de las Maravillas, de Lewis Carroll, en el capítulo 10 aparece la canción de la tortuga Mock y el nombre Beautiful Soup de esta librería hace alusión a dicho texto (hay gente que tiene mucha imaginación a la hora de nombrar las cosas). Nosotros, en cambio, iremos a por el valor en yuanes de la criptomoneda Petro y la entregaremos a Beautiful Soup en el formato normalizado de HTTP Requests.
Para ello, instalaremos con pip install beautiful soup4, para luego continuar con nuestro guion. En una variable llamada HermosaSopa le indicaremos que nos analice y organice:
>>> HermosaSopa = Beautiful Soup(pagina.text, 'html.parser')
Una vez hecho esto, pasamos a la parte un tanto más difícil: nosotros debemos leer el código fuente de la página web y determinar cuál o cuáles etiquetas HTML contienen la última cotización. Como somos muy prácticos, con Mozilla Firefox pulsamos CTRL+U para ver el origen y CTRL+F para buscar el valor “416.31”. Os lo mostramos resaltado en la siguiente imagen:
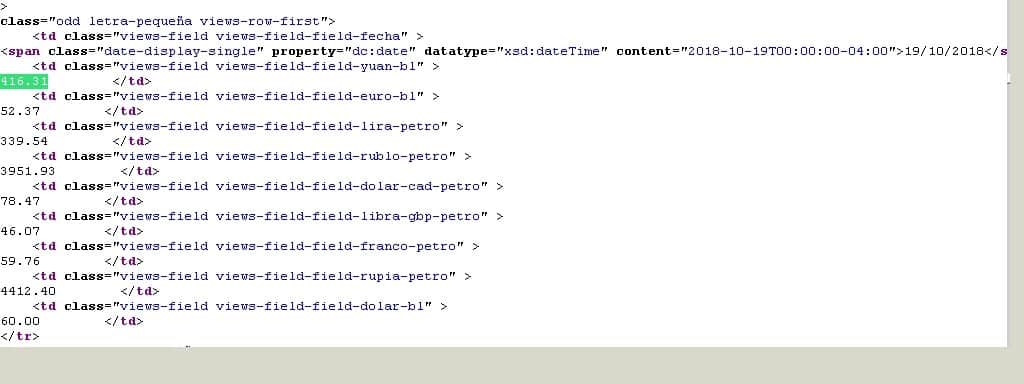
Código fuente HTML con el valor buscado (Licencia Creative Commons 3.0)
En los navegadores web modernos existe la opción de visualizar el DOM; sentiros libres de experimentarlo, nosotros nos vamos por la antigua escuela (mientras funcione).
Para finalizar usaremos el comando find_all, cuyo parámetro será class_ para que busque la muy larga etiqueta. Aquí es donde comenzaremos a ver la potencia de Python: el uso de listas nos permite especificar el primer valor “[0]”, porque de lo contrario obtendríamos todos los valores de la tabla en yuanes y de todos los días.
Con el comando get_text() extraemos solo lo que está entre
…
. Todo esto tiene sentido en el corto guion que combinaremos con el complemento para Pandora FMS; aquí los enlaces para crearlo, crear una alerta y visualizar los valores en la magnífica consola web.
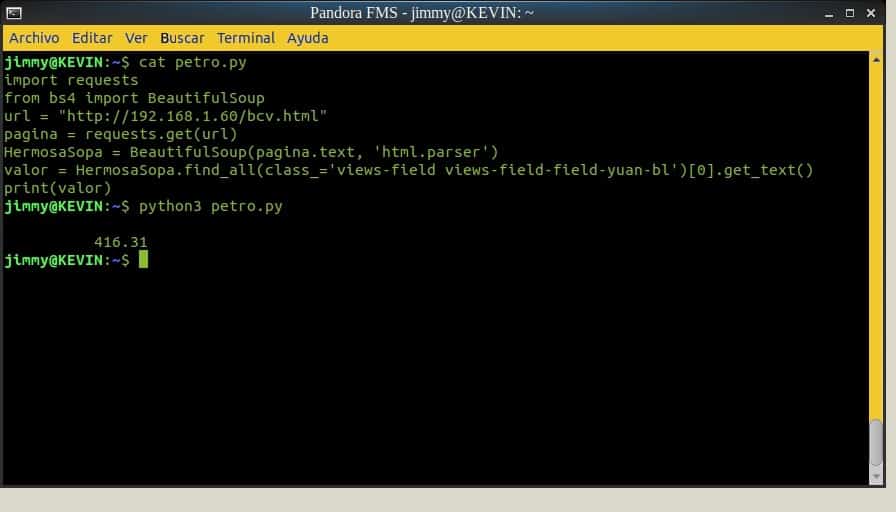
Guion en Python con HTTP Requests y BeautifulSoup (Licencia Creative Commons 3.0)
Por último os dejamos la indicación de que si quisiéramos obtener el valor en euros usaríamos “…-field-field-euro-bl” o en rublos “…-field-field-rublo-petro”, y así sucesivamente. Beautiful Soup también es capaz de manejar datos en XML. Os lanzamos, como reto, la tarea de extraer el valor de un día específico basado en las etiquetas datatype y content; esta última etiqueta contiene la fecha.
Pandora FMS
Con solo contactarnos os podemos ayudar a desarrollar nuevos complementos para Pandora FMS. Si tenéis cualquiera inquietud sobre este artículo, dejad abajo vuestro comentario y os responderemos. ¡Chao!

Programador desde 1993 en KS7000.net.ve (desde 2014 soluciones en software libre para farmacias comerciales en Venezuela). Escribe regularmente para Pandora FMS y ofrece consejos en el foro. También colaborador entusiasta en Wikipedia y Wikidata. Machacador de hierros en gimnasios y cuando puede se ejercita en ciclismo también. Fanático de la ciencia ficción. Programmer since 1993 in KS7000.net.ve (since 2014 free software solutions for commercial pharmacies in Venezuela). He writes regularly for Pandora FMS and offers advice in the forum. Also an enthusiastic contributor to Wikipedia and Wikidata. Crusher of irons in gyms and when he can he exercises in cycling as well. Science fiction fan.









