








La infraestructura debe ser “invisible” para el usuario, pero visible para los estrategas de TI para asegurar el desempeño y los niveles de servicio que requiere el negocio, donde la observabilidad (como parte de SRE o ingeniería de confiabilidad del sitio) es esencial para comprender el estado interno de un sistema en función de sus resultados externos. Para obtener una observabilidad efectiva, existen cuatro pilares clave: métricas, eventos, logs (registros) y trazas (de seguimiento), que se resumen en el acrónimo MELT
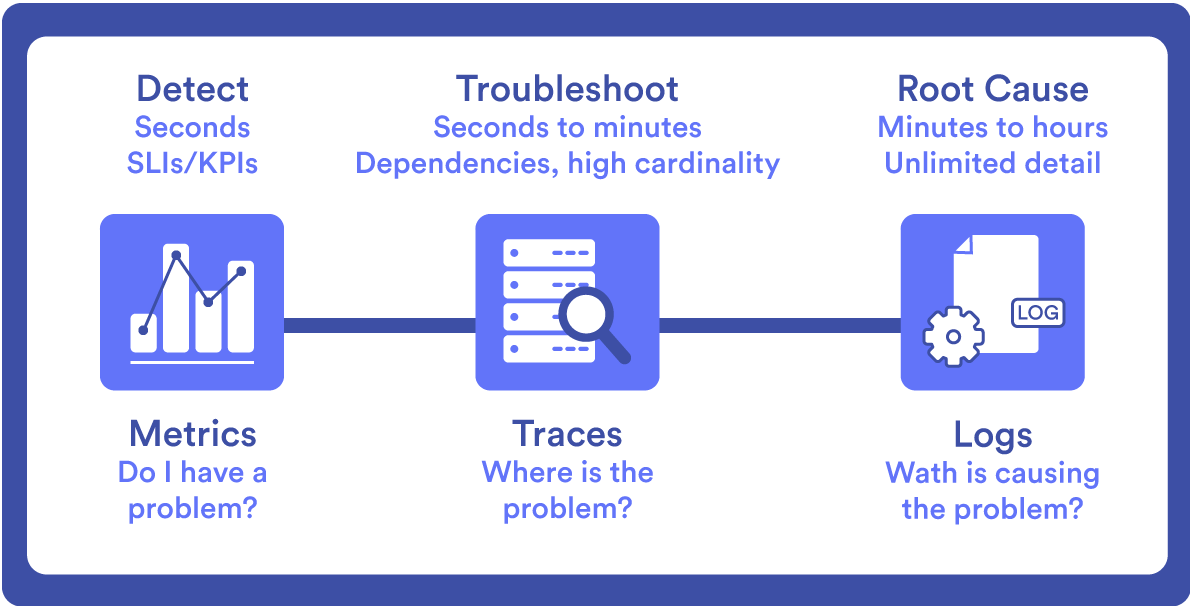
A continuación, definiremos cada uno de estos pilares.
Métricas
¿Qué son las Métricas?
Son medidas numéricas, normalmente periódicas, que brindan información sobre el estado de un sistema y el rendimiento.
Ejemplos de métricas útiles
Tiempos de respuesta, tasas de error, uso de CPU, consumo de memoria y rendimiento de la red.
Ventajas del uso de métricas
Las métricas permiten a los equipos de TI y seguridad realizar un seguimiento de los indicadores clave de rendimiento (Key Performance Indicators, KPI) para detectar tendencias o anomalías en el comportamiento del sistema.
Eventos
¿Qué son los Eventos?
Son sucesos o hechos discretos dentro de un sistema, que pueden abarcar desde la creación de un módulo hasta el inicio de sesión de un usuario en la consola. El evento describe el problema, origen (agente) y creación.
Ejemplos de eventos en sistemas
Acciones de los usuarios (intentos de login del usuario), respuestas de HTTP, cambios en el estado del sistema u otros incidentes notables.
Cómo los eventos proporcionan contexto
Los eventos suelen capturarse como datos estructurados, incluyendo atributos como marca de tiempo, tipo de evento y metadatos asociados, dando mayores elementos e información al equipo de TI para entender el comportamiento del sistema y detectar patrones o anomalías.
Logs
¿Qué son los logs?
Son registros detallados de los eventos y las acciones que ocurren en un sistema. También estos datos recolectados proporcionan una vista cronológica de la actividad del sistema, ofreciendo más elementos para la resolución de problemas y la depuración, el entendimiento del comportamiento de los usuarios y el seguimiento de los cambios en el sistema. Los logs pueden contener información como mensajes de error, seguimientos de pila, interacciones del usuario, notificaciones sobre cambios en el sistema.
Formatos comunes de logs
Normalmente, los logs usan archivos planos, ya sea en codificaciones de caracteres tipo ASCII y se almacenan en forma de texto. Los formatos más conocidos son Microsoft IIS3.0, NCSA, O’Reilly o W3SVC. Además, existen formatos especiales como ELF (Extended Log Format) y CLF (Common Log Format).
Importancia de la centralización de logs
La centralización de los logs asegura una visión completa y más contextualizada del sistema en cualquier momento. Esto permite detectar problemas de manera proactiva y problemas potenciales, así como tomar medidas antes de que se conviertan en problemas mayores. También esta centralización permite contar con los elementos esenciales para auditorías y el cumplimiento regulatorio, ya que se puede demostrar el cumplimiento de políticas y regulaciones sobre seguridad.
Trazas
¿Qué son las Trazas?
Las trazas proporcionan una vista detallada del flujo de solicitudes a través de un sistema distribuido. Esto es porque captan la ruta de una solicitud a medida que atraviesa múltiples servicios o componentes, incluyendo el tiempo en cada paso. De esta manera, las trazas ayudan a comprender las dependencias y los potenciales cuellos de botella en el rendimiento, sobre todo en un sistema complejo. También las trazas permiten analizar cómo se puede optimizar la arquitectura del sistema para mejorar el rendimiento general y, en consecuencia, la experiencia del usuario final.
Ejemplos de trazas en sistemas distribuidos
- El intervalo o span es una operación cronometrada y con nombre que representa una parte del flujo de trabajo. Por ejemplo, los intervalos pueden incluir consultas de datos, interacciones por parte del navegador, llamadas a otros servicios, etc.
- Las transacciones pueden constar de varios tramos y representan una solicitud completa de un extremo a otro que viaja a través de varios servicios en un sistema distribuido.
- Los identificadores únicos para cada uno, con el fin de rastrear el recorrido de la solicitud a través de diferentes servicios. Esto ayuda a visualizar y analizar la ruta y la duración de la solicitud.
- La propagación del contexto de la traza implica pasar el contexto de la traza entre servicios.
- La visualización de la traza para mostrar el flujo de solicitudes a través del sistema, lo que ayuda a identificar fallos o cuellos de botella en el rendimiento.
También, las trazas proporcionan datos detallados para que los desarrolladores puedan realizar un análisis de causa raíz y con esa información abordar problemas relacionados con la latencia, los errores y las dependencias.
Desafíos en la instrumentación de trazas
La instrumentación de trazas puede ser difícil básicamente por dos factores:
- Cada componente de una solicitud debe modificarse para transmitir los datos de rastreo.
- Muchas aplicaciones se basan en bibliotecas o marcos de trabajo que usan el código abierto, por lo que pueden requerir una instrumentación adicional.
Implementación de MELT en sistemas distribuidos
Adoptar la observabilidad a través de MELT implica Telemetría; es decir, la recopilación y transmisión automática de datos desde fuentes remotas a una ubicación centralizada para su monitorización y análisis. De los datos recolectados, se deben aplicar los principios de la telemetría (analizar, visualizar y alertar) para construir sistemas resilientes y confiables.
Recolección de datos de telemetría
Los datos son la base de MELT, en que existen tres principios fundamentales de telemetría:
- Analizar los datos recopilados permite obtener información importante, apoyándose en técnicas estadísticas, algoritmos de aprendizaje automático (Machine Learning) y métodos de minería de datos para identificar patrones, anomalías y correlaciones.
Al analizar las métricas, eventos, logs y trazas, los equipos de TI pueden descubrir problemas de rendimiento, detectar amenazas a la seguridad y entender el comportamiento del sistema. - Visualizar los datos los hace accesibles y comprensibles para las partes interesadas. Las técnicas de visualización eficaces son los paneles, cuadros y gráficos que representan los datos de forma clara y concisa. En una sola vista, tú y tu equipo podéis monitorizar el estado del sistema, identificar tendencias y comunicar hallazgos de manera efectiva.
- Alertar es un aspecto crítico de la observabilidad. Cuando se configuran alertas basadas en umbrales predefinidos o algoritmos de detección de anomalías, los equipos de TI pueden identificar y responder proactivamente a los problemas. Las alertas se pueden activar en función de métricas que superen ciertos límites, eventos que indiquen fallos del sistema o patrones específicos en logs o trazas.
Gestión de datos agregados
Implementar MELT implica manejar una gran cantidad de datos de distintas fuentes como logs de aplicaciones, de los sistemas, tráfico de redes, servicios e infraestructura de terceros. Todos estos datos deben concentrarse en un lugar y agregarse en la forma más simplificada para observar el rendimiento del sistema, detectar irregularidades y su origen, así como también reconocer problemas potenciales. De ahí que se requiere una gestión de datos agregados basada en una organización definida, capacidad de almacenamiento y análisis adecuado para obtener información valiosa.
Agregar datos es especialmente útil para los logs, que constituyen la mayor parte de los datos de telemetría recopilados. Los logs también se pueden agregar con otras fuentes de datos para proporcionar información complementaria sobre el rendimiento de la aplicación y el comportamiento del usuario.
Importancia de MELT en la observabilidad
MELT ofrece un enfoque integral para la observabilidad, con información sobre el estado, el rendimiento y el comportamiento del sistema, a partir de lo cual los equipos de TI pueden detectar, diagnosticar y resolver problemas de manera eficiente.
Mejoras en la fiabilidad y rendimiento del sistema
Adoptar la observabilidad respalda los objetivos de las SER:
- Reducir el trabajo asociado con la gestión de incidentes, particularmente en torno al análisis de causas, mejorando el tiempo de actividad y el tiempo promedio para reparar/resolver (Mean Time To Repair, MTTR).
- Proporcionar una plataforma para monitorizar y adaptar según los objetivos en los niveles de servicio o contratos de niveles de servicio y sus indicadores (Ver ¿Qué son SLA, SLO y SLI?). También da los elementos para una posible solución cuando no se cumplen los objetivos.
- Aliviar la carga del equipo de TI cuando se trata de grandes cantidades de datos, reduciendo el agotamiento o exceso de alertas. También esto lleva a impulsar la productividad, la innovación y la entrega de valor.
- Respaldar equipos multifuncionales y autónomos. Se logra una mejor colaboración con los equipos de DevOps.
Creación de una cultura de observabilidad
Las métricas son el punto de partida para la observabilidad, por lo que se debe crear una cultura de observabilidad donde la recopilación y el análisis adecuado son la base para una toma de decisiones informada y cuidadosa, además de brindar los elementos para anticipar eventos e incluso planear la capacidad de la infraestructura que soporta la digitalización del negocio y la mejor experiencia de los usuarios finales.
Herramientas y técnicas para implementar MELT
- Monitorización del Rendimiento de Aplicaciones (APM, Application Performance Monitoring): APM se utiliza para monitorizar, detectar y diagnosticar problemas de rendimiento en sistemas distribuidos. Proporciona visibilidad de todo el sistema al recopilar datos de todas las aplicaciones y trazar los flujos de datos entre los componentes.
- Análisis AIOps: Son herramientas que utilizan inteligencia artificial y ML para optimizar el rendimiento del sistema y reconocer problemas potenciales.
- Análisis automatizado de la Causa Raíz: La IA identifica automáticamente la causa raíz de un problema, lo que ayuda a detectar y abordar rápidamente los problemas potenciales y optimizar el rendimiento del sistema.
Beneficios de implementar MELT
La fiabilidad y el rendimiento de los sistemas requiere de observabilidad, la cual debe basarse en la implementación de MELT, con datos sobre métricas, eventos, registros y trazas. Toda esta información debe analizarse y ser accionable para abordar problemas de manera proactiva, optimizar el rendimiento y lograr una experiencia satisfactoria para los usuarios y clientes finales.
Pandora FMS: Una solución integral para MELT
Pandora FMS es la solución de monitorización completa para una observabilidad total, ya que su plataforma permite centralizar los datos para obtener una visión integrada y contextualizada, con información para analizar grandes volúmenes de datos de diversas fuentes. En una sola vista es posible ver el estado y las tendencias en el comportamiento de los sistemas, además de generar alertas en forma inteligente y eficiente. También genera información que puede compartirse con clientes o proveedores para dar cumplimiento a los estándares y los objetivos de servicios y rendimiento de los sistemas. Para implementar MELT:
- Pandora FMS unifica la monitorización de los servicios y aplicaciones independientemente del modelo operativo e infraestructuras (física o SaaS, PaaS o IaaS).
- Con Pandora FMS, puedes recopilar y almacenar todo tipo de Logs (incluyendo eventos de Windows) para poder buscar y configurar alertas. Los registros se almacenan en un almacenamiento que no es SQL que te permite guardar datos de diversas fuentes durante bastante tiempo, apoyando a los esfuerzos de cumplimiento y auditorías. Ampliando este tema, te invitamos a leer el documento Registros de Infraestructura, La clave para resolver las nuevas preguntas de cumplimiento, seguridad y negocio.
- Pandora FMS ofrece diseños personalizados de paneles de control o dashboards para mostrar datos en tiempo real y datos de histórico de varios años. Se puede predefinir informes sobre cálculos de disponibilidad, reportes de SLA (mensual, semanal o diario), histogramas, gráficos, reportes de planificación de capacidad, informes de eventos, inventarios y configuración de componentes, entre otros.
- Con Pandora FMS puedes monitorizar el tráfico en tiempo real, obteniendo una visión clara del volumen de solicitudes y transacciones. Esta herramienta te permite identificar patrones de uso, detectar picos inesperados y planificar la capacidad de manera efectiva.
- Con la premisa de que es mucho más eficaz mostrar visualmente el origen de un fallo que simplemente recibir cientos de eventos por segundo. Pandora FMS ofrece el valor de su monitorización, que permite filtrar toda la información y mostrar sólo lo crítico para tomar decisiones oportunas.

EN: Market analyst and writer with +30 years in the IT market for demand generation, ranking and relationships with end customers, as well as corporate communication and industry analysis.
ES: Analista de mercado y escritora con más de 30 años en el mercado TIC en áreas de generación de demanda, posicionamiento y relaciones con usuarios finales, así como comunicación corporativa y análisis de la industria.
FR: Analyste du marché et écrivaine avec plus de 30 ans d’expérience dans le domaine informatique, particulièrement la demande, positionnement et relations avec les utilisateurs finaux, la communication corporative et l’anayse de l’indutrie.









