







Los falsos positivos (tambien los falsos negativos) son un tema recurrente en nuestra experiencia en monitorización, y después de un tiempo creemos que merece la pena hablar en exclusiva de ellos.
La mejor forma de abordar un problema suele ser con un ejemplo: Supongamos que usamos Pandora FMS para monitorizar una red de 500 servidores, en la que tenemos definido que se haga un chequeo de conectividad (ping) hacia cada IP. El resultado más habitual es que aparezcan todos los chequeos en verde, sin embargo, en algunas ocasiones y de manera aleatoria, aparece algún chequeo en rojo. Una vez que lo detectamos, hacemos un ping manualmente y comprobamos que funciona a la perfección.
La conclusión inicial a la que llegamos es que nuestro sistema de monitorización, en este caso Pandora FMS, está fallando, pero en realidad lo que está ocurriendo es que nuestro sistema de monitorización no está configurado correctamente, y es precisamente ahí donde reside el problema.
Para comprobarlo basta con hacer un ping a una de esas IP’s que de vez en cuando fallan y dejarlo durante horas. Veremos que muy de vez en cuando, en 1 de cada 1.000 chequeos o incluso en 1 de cada 10.000 el ping falla, pero no debemos preocuparnos porque es relativamente normal que las redes tengan ese comportamiento en algunas ocasiones.
La siguiente captura nos demuestra como todo nuestro sistema de monitorización está verde, y sin embargo, un ping desde la consola falla. En el caso de que en ese preciso momento Pandora FMS hiciera un chequeo, probablemente se hubiera puesto rojo.
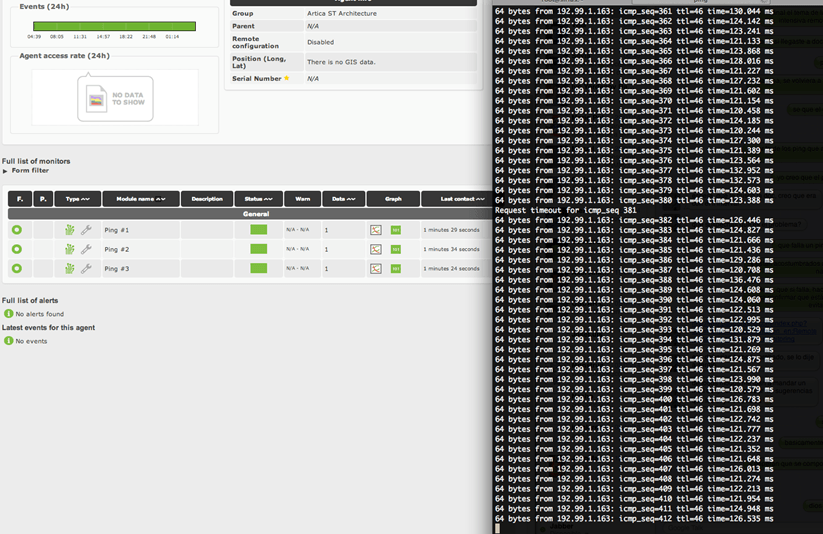
Todos los sistemas de monitorización cuentan con varios parámetros para controlar este comportamiento. Puede que nos interese tener el máximo nivel de detalle, que es como se comporta Pandora FMS por defecto, o por el contrario, puede que queramos atenuar el detalle para no alarmarnos ante el mínimo fallo. A continuación citamos varios mecanismos de control de los que dispone Pandora FMS (también presentes en otros sistemas de monitorización) para evitar este tipo de comportamiento:
-
- Nº de chequeos: En algunas ocasiones falla el primer ping, pero al volver a hacerlo funciona, razón por la cual casi todos los sistemas disponen de un número de intentos. Se ha llegado a dar el caso de sistemas donde el primer ping siempre fallaba, y solo funcionaba cuando se hacía una prueba consistente en hacer un ping con 3 intentos. En este tipo de casos (poco comunes) la mejor opción es usar chequeos muy adaptados (tipo plugin) en vez de usar una prueba estándar.
-
- Timeout: En el caso de querer chequear sistemas remotos puede que tengamos que aumentar el Timeout de respuesta. Si se trata de un LAN, un segundo es más que suficiente, probablemente en Internet nos encontraríamos con muchos falsos positivos provocados por un Timeout muy bajo. Por otro lado, fijar un Timeout demasiado alto, 10 segundos por ejemplo, supondría un lastre para la capacidad de nuestro servidor, dado que en el peor de los casos tendría que esperar 10 segundos por cada chequeo al considerar que el sistema no responde.
- Sensibilidad a la pérdida de paquetes: Puede ser difícil de creer, pero diferentes herramientas de “ping” se comportan de distinta manera, e incluso la misma herramienta de ping en sistemas diferentes se comportan de distinta manera. En algunos casos, la herramienta de monitorización nos permite “configurar” ese comportamiento de forma que se pueda afinar. No se puede comparar el resultado de herramientas como ping, fping, hping, o nmap, ya que van a devolver valores diferentes. Por ello, conviene saber si nuestra herramienta de monitorización dispone de ajustes, que generalmente son respecto a la tolerancia de pérdida de paquetes o a la velocidad de envío de información (muy relacionado con los parámetros Timeout y Nº de chequeos). Una mala configuración puede hacer que aparezcan muchos falsos positivos. En un caso extremo, gracias a esta intolerancia, podemos descubrir con nuestra herramienta de monitorización una red con una pérdida de paquetes que para otras herramientas es inapreciable. Este es un ejemplo real, visto con Pandora ICMP Enterprise server, usando el parámetro T3 en el escaneo de Nmap, en el cual se puede apreciar que algunos sistemas no responden de forma aleatoria debido a una pérdida de paquetes inapreciable para la mayoria de sistemas convencionales de monitorización.
- Flipflop: Así se conoce al fenómeno por el cual un elemento que generalmente se comporta de forma estable rebota de forma más o menos regular. Para evitar que esos rebotes afecten a cómo percibimos nosotros el valor, se le pone un umbral de rebote. Dado que esto a veces tiene “picos” supondremos que hay un problema cuando dicho fallo sucede dos veces seguidas.
- Umbral de Flipflop: Para no tener que esperar a que finalice el proceso normal de monitorización, fijaremos el umbral de Flipflop para controlar el elemento mucho mejor y más rápido. De esta manera, si algo falla, lo sabremos al instante. Generalmente se combina con el parámetro anterior (Flipflop) para que si falla, esperemos a tener una “confirmación”, pero dicha confirmación se realice en un tiempo más corto. Esto en Pandora FMS se conoce como monitorización intensiva. En el ejemplo anterior fijaríamos el umbral de Flipflop en 1 y el intervalo de Flipflop en 30 segundos, de esta manera, si algo falla nos quedaríamos pendientes y repetiríamos la prueba a los 30 segundos . Si la prueba volviera a fallar, daríamos como caído el monitor mandando una alerta al sistema, si no, consideraríamos que es un falso positivo y evitaríamos alertar al sistema.
En conclusión, antes de afirmar que nuestro sistema da falsos positivos, conviene repasar a fondo y ajustar debidamente todos estos elementos en nuestro software de monitorización para evitar alertas innecesarias.
 |
|
| ¿Quiere saber más sobre los falsos positivos en Pandora FMS? |
¿Quiere obtener Pandora FMS? |
El equipo de redacción de Pandora FMS está formado por un conjunto de escritores y profesionales de las TI con una cosa en común: su pasión por la monitorización de sistemas informáticos. Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring.









