






Talking about too many cybersecurity alerts is not talking about the story of Peter and the Wolf and how people end up ignoring false warnings, but about its great impact on security strategies and, above all, on the stress it causes to IT teams, which we know are increasingly reduced and must fulfill multiple tasks in their day to day.
Alert Fatigue is a phenomenon in which excessive alerts desensitize the people in charge of responding to them, leading to missed or ignored alerts or, worse, delayed responses. IT security operations professionals are prone to this fatigue because systems are overloaded with data and may not classify alerts accurately.
Definición de Fatiga de Alertas y su impacto en la seguridad de la organización
Alert fatigue, in addition to overwhelming data to interpret, diverts attention from what is really important. To put it into perspective, deception is one of the oldest war tactics since the ancient Greeks: through deception, the enemy’s attention was diverted by giving the impression that an attack was taking place in one place, causing the enemy to concentrate its resources in that place so that it could attack on a different front. Taking this into an organization, cybercrime can actually cause and leverage IT staff fatigue to find security breaches. This cost could become considerable in business continuity and resource consumption (technology, time and human resources), as indicated by an article by Security Magazine on a survey of 800 IT professionals:
- 85% percent of information technology (IT) professionals say more than 20% of their cloud security alerts are false positives. The more alerts, the harder it becomes to identify which things are important and which ones are not.
- 59% of respondents receive more than 500 public cloud security alerts per day. Having to filter alerts wastes valuable time that could be used to fix or even prevent issues.
- More than 50% of respondents spend more than 20% of their time deciding which alerts need to be addressed first. Alert overload and false positive rates not only contribute to turnover, but also to the loss of critical alerts. 55% say their team overlooked critical alerts in the past due to ineffective prioritization of alerts, often weekly and even daily.
What happens is that the team in charge of reviewing the alerts becomes desensitized. By human nature, when we get a warning of every little thing, we get used to alerts being unimportant, so it is given less and less importance. This means finding the balance: we need to be aware of the state of our environment, but too many alerts can cause more damage than actually help, because they make it difficult to prioritize problems.
Causes of Alert Fatigue
Alert Fatigue is due to one or more of these causes:
False positives
These are situations where a security system mistakenly identifies a benign action or event as a threat or risk. They may be due to several factors, such as outdated threat signatures, poor (or overzealous) security settings, or limitations in detection algorithms.
Lack of context
Alerts must be interpreted, so if alert notifications do not have the proper context, it can be confusing and difficult to determine the severity of an alert. This leads to delayed responses.
Several security systems
Consolidation and correlation of alerts are difficult if there are several security systems working at the same time… and this gets worse when the volume of alerts with different levels of complexity grows.
Lack of filters and customization of cybersecurity alerts
If they are not defined and filtered, it may cause endless non-threatening or irrelevant notifications.
Unclear security policies and procedures
Poorly defined procedures become very problematic because they contribute to aggravating the problem.
Shortage of resources
It is not easy to have security professionals who know how to interpret and also manage a high volume of alerts, which leads to late responses.
The above tells us that correct management and alert policies are required, along with the appropriate monitoring tools to support IT staff.
Most common false positives
According to the Institute of Data, false positives faced by IT and security teams are:
False positives about network anomalies
These take place when network monitoring tools identify normal or harmless network activities as suspicious or malicious, such as false alerts for network scans, legitimate file sharing, or background system activities.
False malware positives
Antivirus software often identifies benign files or applications as potentially malicious. This can happen when a file shares similarities with known malware signatures or displays suspicious behavior. A cybersecurity false positive in this context can result in the blocking or quarantine of legitimate software, causing disruptions to normal operations.
False positives about user behavior
Security systems that monitor user activities can generate a cybersecurity false positive when an individual’s actions are flagged as abnormal or potentially malicious. Example: an employee who accesses confidential documents after working hours, generating a false positive in cybersecurity, even though it may be legitimate.
False positives can also be found in email security systems. For example, spam filters can misclassify legitimate emails as spam, causing important messages to end up in the spam folder. Can you imagine the impact of a vitally important email ending up in the Spam folder?
Consequences of Alert Fatigue
Alert Fatigue has consequences not only on the IT staff themselves but also on the organization:
False sense of security
Too many alerts can lead the IT team to think they are false positives, leaving out the actions that could be taken.
Late Response
Too many alerts overwhelm IT teams, preventing them from reacting in time to real and critical risks. This, in turn, causes costly remediation and even the need to allocate more staff to solve the problem that could have been avoided.
Regulatory non-compliance
Security breaches can lead to fines and penalties for the organization.
Reputational damage to the organization
A breach of the company’s security gets disclosed (and we’ve seen headlines in the news) and impacts its reputation. This can lead to loss of customer trust… and consequently less revenue.
IT staff work overload
If the staff in charge of monitoring alerts feel overwhelmed with notifications, they may experience increased job stress. This has been one of the causes of lower productivity and high staff turnover in the IT area.
Deterioration of morale
Team demotivation can cause them to disengage and become less productive.
How to avoid these Alert Fatigue problems?
If alerts are designed before they are implemented, they become useful and efficient alerts, in addition to saving a lot of time and, consequently, reducing alert fatigue.
Prioritize
The best way to get an effective alert is to use the “less is more” strategy. You have to think about the absolutely essential things first.
- What equipment is absolutely essential? Hardly anyone needs alerts on test equipment.
- What is the severity if a certain service does not work properly? High impact services should have the most aggressive alert (level 1, for example).
- What is the minimum that is needed to determine that a computer, process, or service is not working properly?
Sometimes it is enough to monitor the connectivity of the device, some other times something more specific is needed, such as the status of a service.
Answering these questions will help us find out what the most important alerts are that we need to act on immediately.
Avoiding false positives
Sometimes it can be tricky to get alerts to only go off when there really is a problem. Setting thresholds correctly is a big part of the job, but more options are available. Pandora FMS has several tools to help avoid false positives:
Dynamic thresholds
They are very useful for adjusting the thresholds to the actual data. When you enable this feature in a module, Pandora FMS analyzes its data history, and automatically modifies the thresholds to capture data that is out of the ordinary.



- FF Thresholds: Sometimes the problem is not that you did not correctly define the alerts or thresholds, but that the metrics you use are not entirely reliable. Let’s say we are monitoring the availability of a device, but the connection to the network on which it is located is unstable (for example, a very saturated wireless network). This can cause data packets to be lost or even there are times when a ping fails to connect to the device despite being active and performing its function correctly. For those cases, Pandora FMS has the FF Threshold. By using this option you may configure some “tolerance” to the module before changing state. Thus, for example, the agent will report two consecutive critical data for the module to change into critical status.
- Use maintenance windows: Pandora FMS allows you to temporarily disable alerting and even event generation of a specific module or agent with the Quiet mode. With maintenance windows (Scheduled downtimes), this can be scheduled so that, for example, alerts do not trigger during X service updates in the early hours of Saturdays.
Improving alert processes
Once they have made sure that the alerts that are triggered are the necessary ones, and that they will only trigger when something really happens, you may greatly improve the process as follows:
- Automation: Alerting is not only used to send notifications; it can also be used to automate actions. Let’s imagine that you are monitoring an old service that sometimes becomes saturated, and when that happens, the way to recover it is to just restart it. With Pandora FMS you may configure the alert that monitors that service to try to restart it automatically. To do this, you just need to configure an alert command that, for example, makes an API call to the manager of said service to restart it.
- Alert escalation: Continuing with the previous example, with alert escalation you may make the first action performed by Pandora FMS, when the alert is triggered, to be the restart of the service. If in the next agent run, the module is still in critical state, you may configure the alert so that, for example, a ticket is created in Pandora ITSM.
- Alert thresholds: Alerts have an internal counter that indicates when configured actions should be triggered. Just by modifying the threshold of an alert you may go from having several emails a day warning you of the same problem to receiving one every two or three days.

This alert (executed daily) has three actions: at first, it is about restarting the service. If at the next alert execution, the module has not been recovered, an email is sent to the administrator, and if it has not yet been solved, a ticket is created in Pandora ITSM. If the alert remains triggered on the fourth run, a daily message will be sent through Slack to the group of operators.
Other ways to reduce the number of alerts
- Cascade Protection is an invaluable tool in setting up efficient alerting, by skipping triggering alerts from devices dependent on a parent device. With basic alerting, if you are monitoring a network that you access through a specific switch and this device has a problem, you will start receiving alerts for each computer on that network that you can no longer access. On the other hand, if you activate cascade protection on the agents of that network (indicating whether they depend on the switch), Pandora FMS will detect that the main equipment is down, and will skip the alert of all dependent equipment until the switch is operational again.
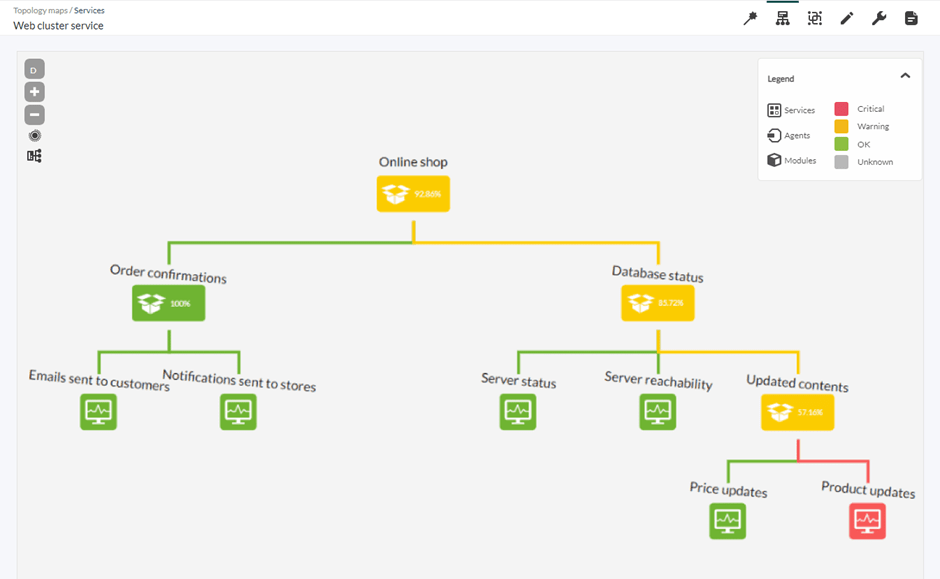
- Using services can help you not only reduce the number of alerts triggered, but also the number of alerts configured. If you have a cluster of 10 machines, it may not be very efficient to have an alert for each of them. Pandora FMS allows you to group agents and modules into Services, along with hierarchical structures in which you may decide the weight of each element and alert based on the general status.
Implement an Incident Response Plan
Incident response is the process of preparing for cybersecurity threats, detecting them as they arise, responding to quell them, or mitigating them. Organizations can manage threat intelligence and mitigation through incident response planning. It should be remembered that any organization is at risk of losing money, data, and reputation due to cybersecurity threats.
Incident response requires assembling a team of people from different departments within an organization, including organizational leaders, IT staff, and other areas involved in data control and compliance. The following is recommended:
- Plan how to analyze data and networks for potential threats and suspicious activity.
- Decide which incidents should be responded to first.
- Have a plan for data loss and finances.
- Comply with all applicable laws.
- Be prepared to submit data and documentation to the authorities after a violation.
Finally, a timely reminder: incident response became very important starting with GDPR with extremely strict rules on non-compliance reporting. If a specific breach needs to be reported, the company must be aware of it within 72 hours and report what happened to the appropriate authorities. A report of what happened should also be provided and an active plan to mitigate the damage should be presented. If a company does not have a predefined incident response plan, it will not be ready to submit such a report.
The GDPR also requires to know if the organization has adequate security measures in place. Companies can be heavily penalized if they are scrutinized after the breach and officials find that they did not have adequate security.
Conclusion
The high cost to both IT staff (constant turnover, burnout, stress, late decisions, etc.) and the organization (disruption of operations, security breaches and breaches, quite onerous penalties) is clear. While there is no one-size-fits-all solution to prevent over-alerting, we do recommend prioritizing alerts, avoiding false positives (dynamic and FF thresholds, maintenance windows), improving alerting processes, and an incident response plan, along with clear policies and procedures for responding to incidents, to ensure you find the right balance for your organization.
Contact us to accompany you with the best practices of Monitoring and alerts.
If you were interested in this article, you can also read: Dynamic thresholds in monitoring. Do you know what they are used for?

Market analyst and writer with +30 years in the IT market for demand generation, ranking and relationships with end customers, as well as corporate communication and industry analysis.
Analista de mercado y escritora con más de 30 años en el mercado TIC en áreas de generación de demanda, posicionamiento y relaciones con usuarios finales, así como comunicación corporativa y análisis de la industria.
Analyste du marché et écrivaine avec plus de 30 ans d’expérience dans le domaine informatique, particulièrement la demande, positionnement et relations avec les utilisateurs finaux, la communication corporative et l’anayse de l’indutrie.








