









Prometheus cherche à devenir une nouvelle génération dans les outils de code ouvert de monitorage. Une approche différente et sans héritage du passé.
Depuis des années, beaucoup d’outils de supervision ont été liés à Nagios par leur architecture et philosophie ou directement étant un fork complet (CheckMk, Centreon, OpsView, Icinga, Naemon, Shinken, Vigilo NMS, NetXMS, OP5 et d’autres).
Prometheus software, toutefois, est fidèle à l’esprit « Open » : si tu veux l’utiliser, tu devras rassembler plusieurs parties différentes.
D’une certaine manière, comme Nagios, vous pouvez dire que c’est une espèce d’Ikea du monitorage : vous pourrez faire avec elle beaucoup de choses, mais vous aurez besoin de rassembler vous-même les pièces et de lui consacrer beaucoup de temps.
- Architecture Prometheus monitoring
- Voulez-vous surveiller vos systèmes gratuitement avec l’un des meilleurs logiciels de supervision qui existent ?
- Prometheus et les séries de données
- À quoi sert Prometheus
- Configuration dans Prometheus
- Rapports sur Prometheus
- Tableau de bord et écrans visuels
- Si vous avez besoin de traiter plus de sources de données dans Prometheus, vous pouvez toujours ajouter plus de serveurs.
- Supervision des systèmes avec Prometheus : exporters et collecteurs
- Conclusion
Architecture Prometheus monitoring
Prometheus, écrit dans le langage de programmation go, a une architecture basée sur l’intégration de technologies tierces libres :
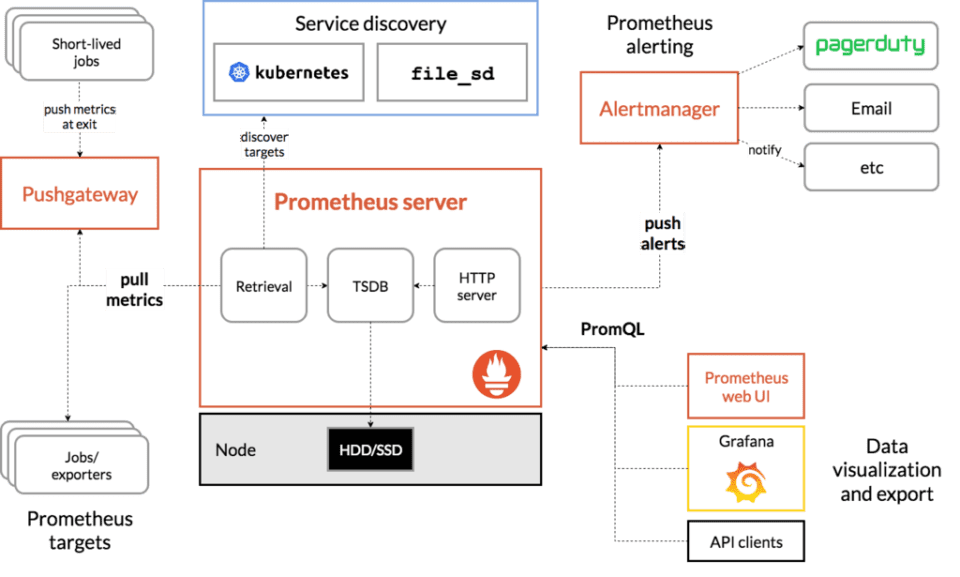
Au contraire d’autres systèmes plus connus, qui ont aussi beaucoup de plugins et pièces pour présenter des cartes, Prometheus a besoin des tiers pour, par exemple, visualiser des données (Grafana) ou exécuter des notifications (Pagerduty).
Tous ces éléments de haut niveau peuvent être remplacés par d’autres pièces, mais Prometheus fait partie d’un écosystème, non seul outil. C’est pourquoi il a des exporters et pièces clé qui essentiellement sont d’autres projets open source :
- HAProxy
- StatsD
- Graphite
- Grafana
- Pagerduty
- OpsGenie
- et beaucoup plus.
Voulez-vous surveiller vos systèmes gratuitement avec l’un des meilleurs logiciels de supervision qui existent ?
Pandora FMS, dans sa version Open Source, est gratuit pour toujours et pour le nombre d’appareils que vous voulez.
Nous vous donnons plus de détails ici :
Prometheus et les séries de données
Si RRD vous est familier, vous avez raison.
Prometheus est conçu comme un cadre de collecte de données avec une structure indéfinie (valeur clé), plutôt que comme un outil de supervision. Cela permet de définir une syntaxe pour son évaluation et donc de ne la stocker qu’en cas d’événement de changement.
Prometheus ne stocke pas les données dans une base de données SQL.
Tout comme Graphite, qui fait quelque chose de similaire, comme d’autres systèmes d’une autre génération qui stockent des séries numériques dans des fichiers RRD, Prometheus stocke chaque série de données dans un fichier spécial.
Si vous recherchez un outil pour collecter des informations à partir d’une base de données de séries temporelles (en anglais » Time series database « ), vous devriez jeter un coup d’œil à OpenTSBD, InfluxDB ou Graphite.
À quoi sert Prometheus
Ou plutôt, à quoi Prometheus NE sert PAS.
Ils le disent eux-mêmes sur leur site Internet : si vous comptez utiliser cet outil pour collecter des logs, NE LE FAITES PAS, ils proposent à la place ELK.
Si vous souhaitez utiliser Prometheus pour superviser des applications, des serveurs ou des ordinateurs distants à l’aide de SNMP, vous pouvez le faire et générer de beaux graphiques avec Grafana, mais d’abord…
Configuration dans Prometheus
Toute la configuration du logiciel Prometheus se fait dans des fichiers texte YAML, avec une syntaxe assez complexe. De plus, chaque exportateur utilisé possède son propre fichier de configuration indépendant.
Avant une modification de la configuration, vous devez redémarrer le service pour vous assurer qu’il prend les modifications.
Rapports sur Prometheus
Par défaut, Prometheus monitoring n’a pas des types de rapport.
Vous devrez les programmer vous-même en utilisant leur API pour extraire les données.
Bien sûr, il existe des projets indépendants pour y parvenir.
Tableau de bord et écrans visuels
Pour avoir un tableau de bord dans Prometheus, vous devrez l’intégrer à Grafana.
Il existe une documentation sur la façon de le faire, puisque Grafana et Prometheus coexistent à l’amiable.
Évolutivité dans Prometheus
Si vous avez besoin de traiter plus de sources de données dans Prometheus, vous pouvez toujours ajouter plus de serveurs.
Chaque serveur traite sa propre charge de travail, car chaque serveur Prometheus est indépendant et peut fonctionner même si ses pairs tombent en panne.
Bien entendu, il faudra « diviser » les serveurs par zones fonctionnelles pour pouvoir les différencier, pa exemple : « service A, service B ». Pour que chaque serveur soit indépendant.
Cela ne semble pas être un moyen de « mise à l’échelle » tel que nous le comprenons, puisqu’il n’y a aucun moyen de synchroniser, de récupérer des données, il n’a pas de haute disponibilité ni de cadre d’accès commun aux informations sur les différents serveurs indépendants.
Mais comme nous l’avons prévenu au début, il ne s’agit pas d’une solution « fermée » mais d’un cadre pour concevoir votre propre solution finale.
Bien sûr, ne doutez pas que Prometheus est capable d’absorber beaucoup d’informations, dans un autre ordre de grandeur que d’autres outils plus connus.
Supervision des systèmes avec Prometheus : exporters et collecteurs
D’une manière ou d’une autre, chaque « façon » différente d’obtenir des informations avec cet outil nécessite un logiciel qu’ils appellent un « exporter ».
Il s’agit toujours d’un binaire avec son propre fichier de configuration YAML qui doit être géré indépendamment (avec son propre démon, fichier de configuration, etc.).
Ce serait l’équivalent d’un plugin dans Nagios.
Ainsi, par exemple, Prometheus a des exportateurs pour SNMP (snmp_exporter), des journaux de supervision (grok_exporter), etc.
Exemple de configuration d’un exportateur snmp en tant que service :

Pour obtenir des informations d’un hébergeur, on peut installer un « node_exporter » qui fonctionne comme un agent classique, similaire à Nagios.
Ces « node_exporter » collectent des métriques de différents types, dans ce qu’ils appellent des « collecteurs ».
Par défaut, Prometheus a des dizaines de ces collecteurs activés. Vous pouvez les consulter tous en naviguant jusqu’à l’annexe 1 : collecteurs actifs.
Et, en plus, il existe de nombreux « exporters » ou plugins, pour obtenir des informations à partir de différents systèmes matériels et logiciels.
Bien que le nombre d’exportateurs soit pertinent (environ 200), il n’atteint pas le niveau des plugins disponibles pour Nagios (plus de 2000).
Voici un exemple d’exporter Oracle
Conclusion
L’approche de Prometheus en matière de monitorage moderne est beaucoup plus flexible que les outils plus anciens. Grâce à sa philosophie, nous pouvons l’intégrer plus facilement dans des environnements hybrides.
Cependant, il vous manquera des rapports, des tableaux de bord et un système de gestion de configuration centralisé.
C’est-à-dire une interface qui permet d’observer et de superviser des informations regroupées en services/hôtes.
Parce que Prometheus est un écosystème de traitement de données, pas un système de surveillance informatique typique.
Sa puissance en traitement de données est bien supérieure,, mais l’utilisation de ces données au quotidien la rend extrêmement complexe à gérer, car elle nécessite de nombreux fichiers de configuration, de nombreuses commandes externes distribuées, et tout doit être maintenu manuellement.
Annexe 1 : Collecteurs actifs sur Prometheus
Voici les collecteurs que Prometheus apporte en tant qu’actifs standard :
Ces « node_exporter » collectent des métriques de différents types, dans ce qu’ils appellent des « collectors », ce sont les collecteurs de séries qui sont activés :
| arp | Exposes ARP statistics from /proc/net/arp. |
| bcache | Exposes bcache statistics from /sys/fs/bcache/. |
| bonding | Exposes the number of configured and active slaves of Linux bonding interfaces. |
| btrfs | Exposes btrfs statistics |
| boottime | Exposes system boot time derived from the kern.boottime sysctl. |
| conntrack | Shows conntrack statistics (does nothing if no /proc/sys/net/netfilter/ present). |
| cpu | Exposes CPU statistics |
| cpufreq | Exposes CPU frequency statistics |
| diskstats | Exposes disk I/O statistics. |
| dmi | Expose Desktop Management Interface (DMI) info from /sys/class/dmi/id/ |
| edac | Exposes error detection and correction statistics. |
| entropy | Exposes available entropy. |
| exec | Exposes execution statistics. |
| fibrechannel | Exposes fibre channel information and statistics from /sys/class/fc_host/. |
| filefd | Exposes file descriptor statistics from /proc/sys/fs/file-nr. |
| filesystem | Exposes filesystem statistics, such as disk space used. |
| hwmon | Expose hardware monitoring and sensor data from /sys/class/hwmon/. |
| infiniband | Exposes network statistics specific to InfiniBand and Intel OmniPath configurations. |
| ipvs | Exposes IPVS status from /proc/net/ip_vs and stats from /proc/net/ip_vs_stats. |
| loadavg | Exposes load average. |
| mdadm | Exposes statistics about devices in /proc/mdstat (does nothing if no /proc/mdstat present). |
| meminfo | Exposes memory statistics. |
| netclass | Exposes network interface info from /sys/class/net/ |
| netdev | Exposes network interface statistics such as bytes transferred. |
| netstat | Exposes network statistics from /proc/net/netstat. This is the same information as netstat -s. |
| nfs | Exposes NFS client statistics from /proc/net/rpc/nfs. This is the same information as nfsstat -c. |
| nfsd | Exposes NFS kernel server statistics from /proc/net/rpc/nfsd. This is the same information as nfsstat -s. |
| nvme | Exposes NVMe info from /sys/class/nvme/ |
| os | Expose OS release info from /etc/os-release or /usr/lib/os-release |
| powersupplyclass | Exposes Power Supply statistics from /sys/class/power_supply |
| pressure | Exposes pressure stall statistics from /proc/pressure/. |
| rapl | Exposes various statistics from /sys/class/powercap. |
| schedstat | Exposes task scheduler statistics from /proc/schedstat. |
| sockstat | Exposes various statistics from /proc/net/sockstat. |
| softnet | Exposes statistics from /proc/net/softnet_stat. |
| stat | Exposes various statistics from /proc/stat. This includes boot time, forks and interrupts. |
| tapestats | Exposes statistics from /sys/class/scsi_tape. |
| textfile | Exposes statistics read from local disk. The –collector.textfile.directory flag must be set. |
| thermal | Exposes thermal statistics like pmset -g therm. |
| thermal_zone | Exposes thermal zone & cooling device statistics from /sys/class/thermal. |
| time | Exposes the current system time. |
| timex | Exposes selected adjtimex(2) system call stats. |
| udp_queues | Exposes UDP total lengths of the rx_queue and tx_queue from /proc/net/udp and /proc/net/udp6. |
| uname | Exposes system information as provided by the uname system call. |
| vmstat | Exposes statistics from /proc/vmstat. |
| xfs | Exposes XFS runtime statistics. |
| zfs | Exposes ZFS performance statistics. |
Annexe 2: Exemple d’exportateur Oracle
Voici un exemple du type d’informations renvoyées par un exportateur Oracle, qui est appelé en configurant un fichier et une série de variables d’environnement qui définissent les informations d’identification et le SID :
- oracledb_exporter_last_scrape_duration_seconds
- oracledb_exporter_last_scrape_error
- oracledb_exporter_scrapes_total
- oracledb_up
- oracledb_activity_execute_count
- oracledb_activity_parse_count_total
- oracledb_activity_user_commits
- oracledb_activity_user_rollbacks
- oracledb_sessions_activity
- oracledb_wait_time_application
- oracledb_wait_time_commit
- oracledb_wait_time_concurrency
- oracledb_wait_time_configuration
- oracledb_wait_time_network
- oracledb_wait_time_other
- oracledb_wait_time_scheduler
- oracledb_wait_time_system_io
- oracledb_wait_time_user_io
- oracledb_tablespace_bytes
- oracledb_tablespace_max_bytes
- oracledb_tablespace_free
- oracledb_tablespace_used_percent
- oracledb_process_count
- oracledb_resource_current_utilization
- oracledb_resource_limit_value
Pour avoir une idée de comment configurer un exportateur, voyons un exemple, avec un fichier de configuration d’exportateur JMX :
---
startDelaySeconds: 0
hostPort: 127.0.0.1:1234
username:
password:
jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
whitelistObjectNames: ["org.apache.cassandra.metrics:*"]
blacklistObjectNames: ["org.apache.cassandra.metrics:type=ColumnFamily,*"]
rules:
- pattern: 'org.apache.cassandra.metrics<type=(\w+), name=(\w+)><>Value: (\d+)'
name: cassandra_$1_$2
value: $3
valueFactor: 0.001
labels: {}
help: "Cassandra metric $1 $2"
cache: false
type: GAUGE
attrNameSnakeCase: false
L’équipe éditoriale de Pandora FMS est composée d’un groupe de rédacteurs et de professionnels de l’informatique ayant un point commun : leur passion pour la surveillance des systèmes informatiques. L’équipe éditoriale de Pandora FMS est composée d’un groupe de rédacteurs et de professionnels de l’informatique ayant un point commun : leur passion pour la surveillance des systèmes informatiques.




