









Base de données NoSQL: quelles sont ses caractéristiques?
Il n’y a pas de doute que la manière dont les applications Web traitent les données a considérablement changé au cours de la dernière décennie. De plus en plus de données sont collectées et de plus en plus d’utilisateurs accèdent à ces données au même temps. Cela signifie que l’extensibilité et la performance sont devenues des véritables défis pour les bases de données relationnelles basées sur des schémas. Mais aujourd’hui nous allons nous concentrer sur la base de données NoSQL.
L’évolution de NoSQL
Le problème de l’extensibilité de SQL a été reconnu par les entreprises Web 2.0, qui ont des besoins importants en matière de données et d’infrastructure, tels que Google, Amazon et Facebook. Seuls, ils devaient trouver leurs propres solutions à ce problème, avec des technologies telles que BigTable, DynamoDB et Cassandra.
Cet intérêt croissant a donné lieu à une série de systèmes de gestion de base de données NoSQL (SGBD), axés sur la performance, la fiabilité et la cohérence. Plusieurs structures d’indexation existantes ont été utilisées et améliorées dans le but d’améliorer la recherche et la performance de lecture.
Premièrement, il existait des types de bases de données NoSQL (propriétaires), développées par des grandes entreprises pour répondre à leurs besoins spécifiques, telles que BigTable de Google, censé être le premier système NoSQL, et DynamoDB d’Amazon.
Le succès de ces systèmes brevetés a initié le développement de plusieurs systèmes de bases de données de source ouverte et appartenant à des propriétaires similaires étant les plus populaires Hypertable, Cassandra, MongoDB, DynamoDB, HBase et Redis.
Qu’est-ce qui différencie NoSQL?
Une différence essentielle entre les bases de données NoSQL et les bases de données relationnelles traditionnelles réside dans le fait que NoSQL est une forme de stockage non structuré.
Cela signifie que NoSQL n’a pas de structure de table fixe comme celle trouvée dans les bases de données relationnelles.
Avantages et désavantages des bases de données NoSQL
Avantages
Les bases de données NoSQL présentent des nombreux avantages par rapport aux bases de données traditionnelles.
● Contrairement aux bases de données relationnelles, les bases de données NoSQL sont basées sur des paires clé-valeur
● Certains types de stockage de bases de données NoSQL incluent différents types de stockages, tels que les stockages de colonnes, de documents, de valeurs de clé, de graphiques, d’objets, de XML et d’autres modes d’entrepôt de données.
● Quelques types de stockage de bases de données NoSQL incluent les entrepôts de colonnes, de documents, de valeurs de clé, de graphiques, d’objets, de XML et d’autres types d’entrepôt de données.
● On pourrait dire que l’implémentation de bases de données NoSQL de source ouverte est rentable. Puisqu’ils n’ont pas besoin de frais de licence et peuvent fonctionner sur du matériel économique.
● Lorsque vous travaillez avec des bases de données NoSQL, qu’elles soient de source ouverte ou qu’elles soient propriétaires, l’extension est plus simple et moins coûteuse que travailler avec des bases de données relationnelles. La raison c’est qu’une processus d’extensibilité horizontale est effectuée et la charge est répartie sur tous les nœuds. Au lieu d’une extensibilité verticale, plus courant dans les systèmes de bases de données relationnelles.
Désavantages
Bien entendu, les bases de données NoSQL ne sont pas parfaites et ne constitueront pas toujours le choix idéal.
● La plupart des bases de données NoSQL ne prennent pas en charge les fonctions de fiabilité, qui sont soutenues par les systèmes de bases de données relationnelles. Ces caractéristiques de fiabilité peuvent être résumées comme suit: « atomicité, consistance, isolement et durabilité. » Cela signifie également que les bases de données NoSQL, qui ne supportent ces fonctionnalités, offrent une certaine cohérence en termes de performance et d’extensibilité.
● Afin de soutenir les fonctionnalités de fiabilité et de cohérence, les développeurs doivent implémenter leur propre code, ce qui ajoute une complexité supplémentaire au système.
● Cela pourrait limiter le nombre d’applications sur lesquelles nous pouvons compter pour effectuer des transactions sécurisées et fiables, telles que des systèmes bancaires.
● L’incompatibilité avec les requêtes SQL est l’une des complexités trouvées dans la plupart des bases de données NoSQL. Cela signifie qu’un langage de requête manuelle est nécessaire, ce qui rend les processus beaucoup plus lents et complexes.
NoSQL vs. Les bases de données relationnelles
Ce tableau offre une brève comparaison entre les fonctionnalités de NoSQL et celles des bases de données relationnelles :
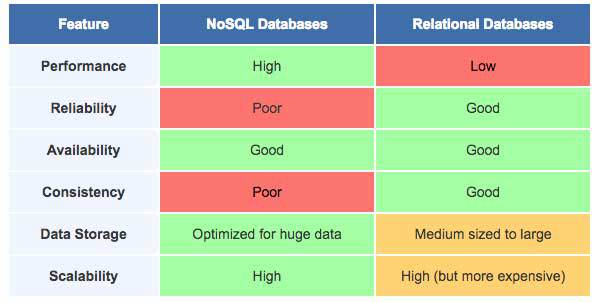
Il convient de noter que ce tableau présente une comparaison au niveau de la base de données, et pas sur les différents systèmes de gestion de base de données qui implémentent les deux modèles. Ces systèmes fournissent leurs propres techniques brevetées pour résoudre les problèmes et les défaillances rencontrés dans le système, en plus d’essayer d’améliorer considérablement la performance et la fiabilité.
Types de stockage de données NoSQL
Entrepôt de valeurs clé
Dans l’entrepôt du type valeur clé, une table de hachage est utilisée dans laquelle une clé unique pointe vers un élément.
Les clés peuvent être organisées par groupes clé logiques. Seulement ces clés doivent être uniques dans leur propre groupe. Cela permet d’avoir des clés identiques dans différents groupes logiques. Le tableau ci-dessous montre un exemple d’entrepôt de valeurs clé, dans lequel la clé est le nom de la ville et la valeur est l’adresse de l’université d’Ulster dans cette ville.

Certaines mises en œuvre de l’entrepôt de valeurs clé fournissent des mécanismes de stockage dans le cache, ce qui améliore considérablement sa performance.
Tout ce qui est nécessaire pour traiter les éléments stockés dans la base de données est la clé. Les données sont stockées sous la forme d’une chaîne, JSON ou BLOB (objet binaire volumineux).
L’un des plus gros défauts de cette forme de base de données est le manque de cohérence au niveau de la base de données. Ceci peut être ajouté par les développeurs avec leur propre code, même si cela demande plus d’effort et de temps.
La base de données NoSQL la plus connue qui est construite dans un entrepôt de valeurs clé est DynamoDB d’Amazon.
Entrepôt de documents
Les entrepôts de documents sont similaires aux entrepôts de valeurs clés, car ils ne possèdent pas de schéma et sont basés sur un modèle de valeur clé. Les deux manquent de cohérence au niveau de la base de données, ce qui permet aux applications de fournir plus de fiabilité.
Les différences les plus significatives sont:
– Dans l’entrepôt de documents, les valeurs (documents) fournissent un codage XML, JSON ou BSON (binaire codé JSON) pour les données stockées.
L’application de base de données la plus populaire, basée sur un entrepôt de documents, est MongoDB.
Stockage en colonnes
Les données sont stockées dans des colonnes au lieu d’être stockées dans des lignes (comme c’est le cas de la plupart des systèmes de gestion de base de données relationnelles).
Un entrepôt de colonnes est composé d’une ou de plusieurs familles de colonnes regroupées de manière logique dans certaines colonnes de la base de données. Une clé est utilisée pour identifier et pointer un certain nombre de colonnes dans la base de données. Chaque colonne contient des lignes de noms ou des nuplets, ainsi que des valeurs, ordonnées et séparées par des virgules.
Les entrepôts de colonnes ont un accès rapide de lecture et écriture aux données stockées. Dans un entrepôt de colonnes, les lignes correspondant à une seule colonne sont stockées sous la forme d’une seule entrée de disque, ce qui facilite l’accès lors des opérations de lecture et d’écriture.
Les bases de données les plus populaires qui utilisent l’entrepôt de colonnes incluent Google BigTable, HBase et Cassandra.
Base graphique
Dans un graphe d’une base de données NoSQL, une « structure de graphe dirigée » est utilisée pour représenter les données. Le graphique est composé d’arêtes et de nœuds.
Formellement, un graphique est une représentation d’un ensemble d’objets dont certaines paires d’objets sont reliées par des liens. Les objets interconnectés sont représentés par des abstractions mathématiques, appelées sommets, et les liens qui connectent certaines paires de sommets sont appelés des arêtes. Donc un graphique est un type de représentation de données composé d’un ensemble de sommets et d’arêtes se connectant les uns aux autres, montrant visuellement leur relation mathématique.
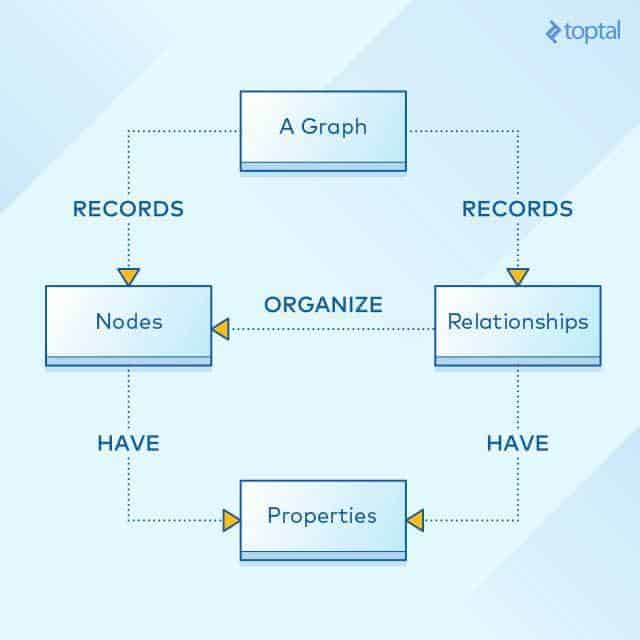
Ceci illustre graphiquement la structure d’une base de données, où des arêtes et des nœuds sont utilisés pour représenter et stocker les données. Ces nœuds sont organisés les uns avec les autres et sont représentés par les arêtes entre les nœuds. Les nœuds et les relations ont des propriétés définies.
Les bases de données graphiques sont souvent utilisées dans les applications de réseaux sociaux. Celles-ci permettent aux développeurs de se concentrer davantage sur les relations entre les objets au lieu des objets eux-mêmes. Dans ce contexte, ils permettent un environnement extensible et facile à utiliser.
Actuellement, InfoGrid et InfiniteGraph sont les bases de données graphiques les plus populaires.
Systèmes de gestion de bases de données NoSQL
Pour une brève comparaison des bases de données, le tableau suivant fournit une brève comparaison entre les différents systèmes de gestion de base de données NoSQL.
MongoDB possède un système de stockage de schémas flexible. Ce qui signifie que les objets stockés ne doivent pas nécessairement avoir la même structure ni les mêmes domaines. MongoDB possède également certaines fonctionnalités d’optimisation, qui distribuent des collections de données, améliorant la performance et aboutissant à un système plus équilibré.
D’autres systèmes de base de données NoSQL, tels qu’Apache CouchDB, sont également considérés comme des bases de données du type entrepôt de documents. Par conséquent, ils partagent de nombreuses fonctionnalités avec MongoDB, sauf pour qu’il est possible d’accéder à la base de données à l’aide des API RESTful.
REST est un style architectural constitué d’un ensemble coordonné de contraintes architecturales appliquées aux composants, aux connecteurs et aux éléments de données, tout dans le Web. Il est basé sur un protocole de communication empilable, client-serveur, un protocole de communication pouvant être mis en cache (par exemple, le protocole HTTP).
Les applications RESTful utilisent des requêtes HTTP pour publier, lire et supprimer des données.
En ce qui concerne les bases de données de bases de colonnes, Hypertable est une base de données NoSQL écrite en C ++ et basée sur BigTable de Google. Hypertable prend en charge la distribution d’entrepôts de données entre les nœuds afin de maximiser l’extensibilité, comme MongoDB et CouchDB.
Une des bases de données NoSQL les plus utilisées est Cassandra, développée par Facebook. Il s’agit d’une base de données d’entrepôts de colonnes qui inclut de nombreuses fonctionnalités visant la fiabilité et la tolérance aux pannes.
Cassandra
Cassandra est un système de gestion de base de données développé par Facebook, dont le but était de créer un SGBD sans défaillance et d’offrir une disponibilité maximale.
Cassandra est principalement une base de données d’entrepôts de colonnes. Certaines études considèrent Cassandra comme un système hybride, inspiré de BigTable de Google (base de données d’entrepôt de colonnes) et de DynamoDB d’Amazon (base de données de valeurs clé).
Ceci est réalisé en fournissant un système de valeurs clé. Mais les clés de Cassandra pointent à un ensemble de familles de colonnes, dépendant du système de fichiers distribué « BigTable » de Google et des caractéristiques de disponibilité de Dynamo (table de hachage distribuée).
Cassandra est conçue pour stocker d’énormes quantités de données réparties sur différents nœuds. Cassandra est un SGBD conçu pour gérer des quantités énormes de données, réparties sur de nombreux serveurs, tout en fournissant un service hautement disponible sans un seul point de défaillance, essentiel pour un service de qualité comme Facebook.
Les principales caractéristiques de Cassandra incluent :
● Il n’y a pas un seul point de défaillance. Pour ce faire, Cassandra doit fonctionner comme un grappe de nœuds. Cela ne signifie pas que les données de chaque grappe sont les mêmes, cependant, le logiciel de gestion doit être le même. En cas de défaillance de l’un des nœuds, les données de ce nœud sont inaccessibles. Cependant, les autres nœuds (et données) restent accessibles.
● Un hachage distribué est un schéma qui fournit une fonctionnalité de table de hachage, de sorte que l’ajout ou la suppression d’une fente ne modifie pas de manière significative l’attribution de clés à ces emplacements. Cela permet de distribuer la charge sur les serveurs ou les nœuds en fonction de leur capacité et, ainsi, de minimiser les temps d’arrêt.
● Interface client relativement facile à utiliser. Cassandra utilise Apache Thrift pour son interface client. Apache Thrift propose un client RPC dans plusieurs langues, mais la plupart des développeurs préfèrent des alternatives de source ouverte construites sur Apple Thrift, telles que Hector.
● Autres fonctionnalités de disponibilité. Une des caractéristiques de Cassandra est la réplication des données. Fondamentalement, il reflète les données aux autres nœuds du grappe. La réplication peut être aléatoire ou spécifique pour optimiser la protection des données, en la plaçant par exemple dans un nœud d’un autre centre de données. Une autre caractéristique de Cassandra est la politique de partition. La directive de partition détermine le noeud sur lequel la clé sera placée. Cela peut aussi être aléatoire ou ordonné. En utilisant les deux types de politiques de partition, Cassandra peut parvenir à un équilibre entre l’équilibrage de la charge et l’optimisation des performances des requêtes.
● Cohérence. Des fonctions telles que la réplication font de la cohérence un défi. Cela est dû au fait que tous les nœuds doivent être mis à jour à tout moment avec les valeurs les plus récentes. Toutefois, Cassandra tente de maintenir un équilibre entre les actions de réplication et les actions de lecture / écriture en fournissant cette personnalisation au développeur.
● Actions de lecture / écriture. Le client envoie une demande à un seul noeud Cassandra. Selon la politique de réplication, le nœud stocke les données dans le grappe. Chaque nœud effectue d’abord la modification de données dans l’enregistrement de confirmation, puis met à jour la structure de la table avec la modification, les deux étant effectués de manière synchrone. L’opération de lecture est également très similaire, une demande de lecture est envoyée à un seul nœud et ce dernier est celui qui détermine quel nœud contient les données, en fonction de la politique de partition / emplacement.
MongoDB
MongoDB est une base de données libre de diagrammes, orientée vers les documents, écrite en C ++. La base de données est basée sur l’entrepôt de documents, ce qui signifie qu’elle stocke des valeurs (dénommés documents) sous la forme de données codées.
Le choix du format encodé dans MongoDB est JSON. Il est très puissant, car même si les données sont imbriquées dans les documents JSON, elles seront toujours consultables et indexables.
Les sous-sections qui suivent décrivent certaines des principales fonctionnalités disponibles dans MongoDB.
Shards / Fragments
Sharding c’est le partitionnement et la distribution des données via plusieurs machines (nœuds). Un fragment est une collection de nœuds MongoDB. Contrairement à Cassandra, où les nœuds étaient répartis de manière symétrique.
L’utilisation de fragments implique également la possibilité de scalabilité horizontale via plusieurs nœuds. Dans le cas où il y a une application qui utilise un seul serveur de base de données, il peut devenir grappe fragmenté, avec très peu de modifications dans le code de l’application originale, pour la manière dont Sharding est exécutée par MongoDB. Oftware est presque découplé des API publiques.
Langage de requête Mongo
Comme mentionné ci-dessus, MongoDB utilise une API RESTful. Pour récupérer certains documents d’une collection de base de données, un document de requête contenant les domaines qui doivent correspondre aux documents souhaités est créé.
Actions
Dans MongoDB, il existe un groupe de serveurs appelés routeurs. Chacun joue le rôle de serveur pour un ou plusieurs clients. De la même manière, le grappe contient un groupe de serveurs appelés serveurs de configuration. Chacun contient une copie des métadonnées indiquant quel fragment contient quelles données. Les actions de lecture ou d’écriture sont envoyées dès clients à l’un des serveurs de routeur du grappe et sont automatiquement acheminées par ce serveur vers les fragments appropriés contenant les données à l’aide des serveurs de configuration.
Un aspect dans MongoDB similaire à Cassandra est que les deux ont un schéma de réplication de données, ce qui crée un ensemble de répliques de chaque fragment qui contient exactement les mêmes données.
Il existe deux types de schémas de réplication sur MongoDB : Réplication maître-esclave et replica-Set. Replica-set fournit plus d’automatisation et une meilleure gestion des défaillances, tandis que maître-esclave a besoin de l’intervention d’un administrateur généralement. Indépendamment du schéma de réplication, à n’importe quel point de l’ensemble de répliques, un seul fragment joue le rôle de fragment primaire. Tous les fragments de réplique sont des fragments secondaires. Toutes les opérations d’écriture et de lecture passent au fragment primaire et sont ensuite distribuées uniformément (si nécessaire) aux autres fragments secondaires de l’ensemble.
Dans le graphique ci-dessous, vous voyez l’architecture MongoDB expliquée ci-dessus, montrant les serveurs du routeur en vert, les serveurs de configuration en jaune et les fragments contenant les nœuds MongoDB en bleu.
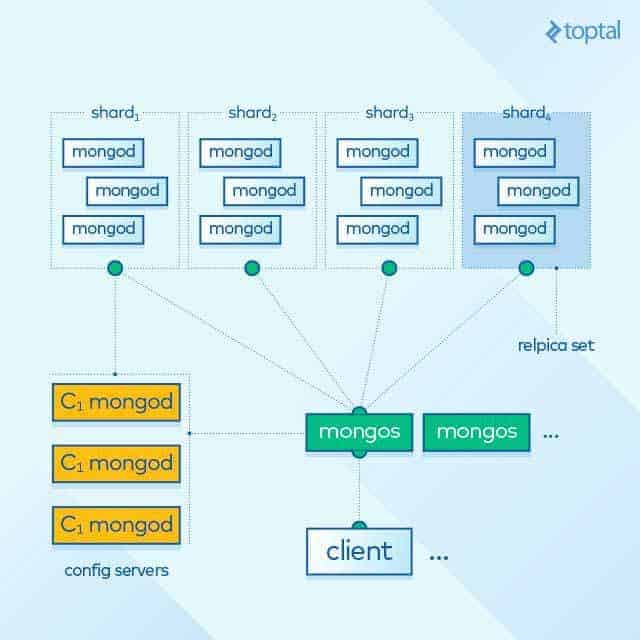
Il convient de noter que le sharding (ou le partage de données entre fragments) dans MongoDB est complètement automatique, ce qui réduit le taux de défaillance et fait de MongoDB un système de gestion de base de données hautement extensible.
Structures d’indexation pour bases de données NoSQL
L’indexation est le processus consistant à associer une clé à l’emplacement d’un enregistrement de données correspondant dans un SGBD. Des nombreuses structures de données d’indexation sont utilisées dans les bases de données NoSQL. Les sections suivantes présenteront brièvement certaines des méthodes les plus courantes.
L’indexation des arbres B, l’indexation des arbres T et l’indexation des arbres O2.
Indexation des arbres B
L’arbre B est l’une des structures d’index les plus courantes dans les SGBD.
Dans les arbres B, les nœuds internes peuvent avoir un nombre variable de nœuds secondaires dans une plage prédéfinie.
Une différence importante par rapport aux autres structures d’arbre, telles que AVL, est que l’arbre B permet aux nœuds d’avoir un nombre variable de nœuds secondaires. Ce qui signifie moins d’équilibre d’arbre et plus d’espace perdu.
L’arbre B + est l’une des variantes les plus populaires des arbres B. L’arbre B + est une amélioration par rapport à l’arbre B qui exige toutes les clés pour résider dans les feuilles.
Indexation des arbres T
La structure de données d’un arbre T a été conçue en combinant des fonctionnalités des arbres AVL et des arbres B. (arbre AVL et arbre B).
Une arbre AVL est un type d’auto-équilibrage binaire d’arbres de recherche, tandis qu’un arbre B est plus déséquilibrée et que chaque nœud peut avoir un nombre différent d’enfants.
La structure d’un arbre T est très similaire à celle des arbres B et AVL.
Chaque nœud stocke plus d’un nuplet {valeur clé, pointeur}. De plus, la recherche binaire est utilisée en combinaison avec les nœuds de plusieurs nuplets pour améliorer le stockage et la performance.
Un arbre T a trois types de nœuds : Un nœud T qui a un enfant droit et gauche, un nœud feuille sans enfants et un nœud demi-feuille avec un seul enfant.
Nous pensons que les arbres T ont des meilleures performances globales que les arbres AVL.
Indexation des arbres O2
L’arbre O2 est fondamentalement une amélioration par rapport aux arbres rouge et noir, une forme d’arbre binaire de recherche, dans lequel les nœuds feuille contiennent la valeur {valeur clé, pointeur}
L’arbre O2 a été proposée pour améliorer les performances des méthodes d’indexation actuelles. Un arbre O2 d’ordre m (m ≥ 2), où « m » est le degré minimal de l’arbre, satisfait aux propriétés suivantes :
● Chaque nœud est rouge ou noir. Mais la racine est toujours noire.
● Si un nœud est rouge, ses deux enfants sont noirs.
● Pour chaque nœud interne, tous les chemins simples allant du nœud aux nœuds feuilles descendants contiennent le
même nombre de nœuds noirs. Chaque nœud interne a une seule valeur de clé.
● Les nœuds feuilles sont des blocs qui ont entre ⌈m / 2⌉ et m paires « clé-valeur, record-pointeur. »
● Si un arbre a un seul nœud, il doit alors s’agir d’une feuille, qui est la racine de l’arbre et peut contenir des éléments de données clés entre 1 et m.
● Les nœuds feuilles peuvent aller en avant et en arrière.
Nous voyons ici une comparaison directe des performances entre des arbres :

L’ordre des arbres T, B + et O2 utilisé était m = 512.Le temps est enregistré pour les opérations de recherche, d’insertion et de suppression avec des taux de mise à jour allant de 0% à 100% pour un index de 50 millions d’enregistrements, avec les opérations entraînant l’ajout de 50 millions d’enregistrements supplémentaires à l’index.
Il est clair qu’avec un taux de rafraîchissement de 0-10%, l’arbre B et l’arbre T ont de meilleurs résultats que l’arbre O2. Cependant, avec l’augmentation du taux de mise à jour, l’index de l’arbre O2 fonctionne nettement mieux que les autres structures de données.
Quel est le cas pour NoSQL?
« Bien que les bases de données relationnelles offrent une cohérence, elles ne sont pas optimisées pour des performances élevées dans les applications où des données volumineuses sont souvent stockées et traitées. »
Les bases de données NoSQL ont acquis une grande popularité en raison de leurs hautes performances, de leur grande extensibilité et de leur facilité d’accès. Cependant, ils ne disposent toujours pas des fonctionnalités assurant cohérence et fiabilité. Heureusement, une série de SGBD NoSQL répond à ces défis en proposant des nouvelles fonctionnalités pour améliorer l’évolutivité et la fiabilité.
Pas tous les systèmes de base de données NoSQL fonctionnent mieux que les bases de données relationnelles. MongoDB et Cassandra ont des performances similaires, et dans de nombreux cas meilleures que les bases de données relationnelles en écriture et en suppression.
Il n’y a pas de corrélation directe entre le type de stockage et les performances d’un SGBD NoSQL.
Les implémentations NoSQL subissent des modifications, donc les performances peuvent varier. Par conséquent, les mesures de performance effectuées à l’aide de types de bases de données dans différentes études doivent toujours être mises à jour avec les versions les plus récentes du logiciel de base de données afin que ces chiffres soient exacts.
Bien que nous ne puissions pas donner un verdict définitif sur sa performance, voici quelques points à garder à l’esprit :
● L’indexation traditionnelle d’arbre B et d’arbre T est couramment utilisée dans les bases de données traditionnelles.
● Une étude a offert des améliorations en combinant les caractéristiques de plusieurs structures d’indexation pour atteindre l’arbre O2.
● L’arbre O2 a dépassé les autres structures dans la plupart des tests, notamment avec des énormes ensembles de données et des taux de mise à jour élevés.
● La structure arbre B présentait la pire performance de toutes les structures d’indexation traitées dans cet article.
Davantage de travail peut et devrait être fait pour améliorer la cohérence des SGBD NoSQL. L’intégration des deux systèmes, NoSQL et les bases de données relationnelles, est un domaine à explorer.
NoSQL commercialise des fonctions de fiabilité et de cohérence pour un processus de performance et d’extensibilité extrême. Cela en fait une solution spécialisée, car le nombre d’applications pouvant dépendre des bases de données NoSQL est encore limité. Ainsi, bien que la spécialisation puisse être peu flexible, si vous voulez un travail spécialisé, rapide et efficace, le plus indiqué sera NoSQL.
Source: Toptal. https://www.toptal.com/database/the-definitive-guide-to-nosql-databases
Auteur original: Mohamad Altarade

Traductora a francés e inglés. Me encantan las lenguas. Amante de la ropa oversize, la tarta de queso y el chocolate caliente en invierno. Me gusta leer, escuchar música, viajar y explorar cosas nuevas. Mi frase más temida por aquellos que me conocen es « he estado pensando… »
Translator into French and English. I love languages. Lover of oversized clothes, cheesecake and hot chocolate in winter. I like reading, listening to music, travelling and exploring new things. My most feared phrase by those who know me is « I’ve been thinking… »




