







Hablar de demasiadas alertas en ciberseguridad no es hablar del cuento de Pedro y el Lobo y de cómo las personas acaban por ignorar advertencias falsas, sino de su gran impacto en las estrategias de seguridad y, sobre todo, en el estrés que causa al equipo de TI, que bien sabemos son cada vez más reducidos y deben cumplir diversas tareas en su día a día.
La Fatiga de Alertas o fatiga de alarma es un fenómeno en el que el exceso de alertas insensibiliza a las personas encargadas de responder a ellas, lo que lleva a alertas perdidas o ignoradas o, lo que es peor, respuestas tardías. Los profesionales de operaciones de seguridad de TI son propensos a esta fatiga debido a que los sistemas están sobrecargados con datos y pueden no clasificar las alertas con exactitud.
Definición de Fatiga de Alertas y su impacto en la seguridad de la organización
La fatiga de alertas, además de abrumar con datos por interpretar, desvía la atención de lo que es realmente importante. Para ponerlo en perspectiva, el engaño es una de las tácticas de guerra más antiguas desde los antiguos griegos: mediante el engaño, se desviaba la atención del enemigo dando la impresión de que se estaba produciendo un ataque en un lugar, haciendo que el enemigo concentrara sus recursos en dicho lugar para poder atacar por otro frente diferente. Trasladando esto a una organización, el cibercrimen bien puede causar y aprovechar la Fatiga del staff de TI para hallar brechas de seguridad. El costo de esto puede ser alto en la continuidad del negocio y consumo de recursos (tecnología, tiempo y recursos humanos), tal y como lo indica un artículo de Security Magazine sobre una encuesta a 800 profesionales de TI:
- 85% por ciento de los profesionales de tecnología de la información (TI) dicen que más del 20% de sus alertas de seguridad en la nube son falsos positivos. Cuantas más alertas, más difícil se hace identificar qué cosas son importantes y qué cosas no lo son.
- 59% de los encuestados recibe más de 500 alertas de seguridad de la nube pública por día. Al tener que filtrar las alertas, se pierde tiempo valioso que podría usarse para solucionar o incluso prevenir los problemas.
- Más del 50% de los encuestados dedica más de 20% de su tiempo a decidir qué alertas deben abordarse primero. La sobrecarga de alertas y las tasas de falsos positivos no solo contribuyen a la rotación, sino también a la pérdida de alertas críticas. 55% dicen que su equipo pasó por alto alertas críticas en el pasado debido a una priorización ineficaz de las alertas, a menudo semanalmente e incluso diariamente.
Lo que sucede es que el equipo que se encarga de revisar las alertas se va insensibilizando. Por naturaleza humana, cuando nos llega un aviso de cada pequeña cosa, nos acostumbramos a que las alertas sean poco importantes, así que se le da cada vez menos importancia. Esto significa que hay que encontrar el equilibrio: necesitamos estar enterados del estado de nuestro entorno, pero demasiadas alertas pueden causar más daño que la ayuda que prestan, porque dificultan la priorización de los problemas.
Causas de la Fatiga de Alertas
La Fatiga de Alertas se debe a una o varias de estas causas:
Falsos positivos
Son situaciones en las que un sistema de seguridad identifica erróneamente una acción o evento benigno como una amenaza o riesgo. Pueden deberse a varios factores, como firmas de amenazas desactualizadas, malas configuraciones de seguridad (o demasiado entusiastas), o limitaciones en los algoritmos de detección.
Falta de contexto
Las alertas deben ser interpretadas, por lo que, si las notificaciones de alerta no tienen el contexto adecuado, puede resultar confuso y difícil determinar la severidad de una alerta. Esto lleva a respuestas tardías.
Varios sistemas de seguridad
La consolidación y la correlación de las alertas se dificultan si existen diversos sistemas de seguridad que trabajan al mismo tiempo… y esto empeora cuando crece el volumen de alertas con distintos niveles de complejidad.
Falta de filtros y personalización de alertas de ciberseguridad
Si no se definen y filtran puede provocar un sinfín de notificaciones no amenazadoras o irrelevantes.
Políticas y procedimientos de seguridad no claros
Los procedimientos mal definidos llegan a ser muy problemáticos porque contribuyen a agravar el problema.
Escasez de recursos
No es fácil contar con profesionales de la seguridad que sepan interpretar y además gestionar un alto volumen de alertas lo que conduce a respuestas tardías.
Lo anterior nos dice que se requiere de una correcta gestión y políticas de alertas, junto con las herramientas adecuadas de monitorización que apoyen al staff de TI.
Falsos positivos más comunes
De acuerdo con el Institute of Data, los falsos positivos con los que se enfrentan los equipos de TI y seguridad son:
Falsos positivos sobre anomalías en la red
Estos ocurren cuando las herramientas de monitorización de red identifican actividades de red normales o inofensivas como sospechosas o maliciosas, tales como alertas falsas para escaneos de red, intercambio legítimo de archivos o actividades del sistema en segundo plano.
Falsos positivos de malware
El software antivirus a menudo marca archivos o aplicaciones benignas como potencialmente maliciosas. Esto puede suceder cuando un archivo comparte similitudes con firmas de malware conocidas o muestra un comportamiento sospechoso. Un falso positivo en ciberseguridad en este contexto puede resultar en el bloqueo o cuarentena de software legítimo, provocando interrupciones en las operaciones normales.
Falsos positivos sobre el comportamiento del usuario
Los sistemas de seguridad que monitorizan las actividades de los usuarios pueden generar un falso positivo en ciberseguridad cuando las acciones de un individuo se marcan como anormales o potencialmente maliciosas. Ejemplo: un empleado que accede a documentos confidenciales después del horario laboral, generando un falso positivo en ciberseguridad, aunque pueda ser legítimo.
También se pueden encontrar falsos positivos en los sistemas de seguridad del correo electrónico. Por ejemplo, los filtros de Spam pueden clasificar erróneamente los correos electrónicos legítimos como spam, lo que hace que los mensajes importantes terminen en la carpeta de correo no deseado. ¿Puedes imaginarte el impacto de que un correo de vital importancia acabe en la carpeta de Spam?
Consecuencias de la Fatiga de Alertas
La Fatiga de Alertas tiene consecuencias no sólo en el propio staff de TI sino también en la organización:
Falsa sensación de seguridad
Demasiadas alertas pueden llevar al equipo de TI a pensar que son falsos positivos, dejando de lado las acciones que se podrían tomar.
Respuesta tardía
El exceso de alertas saturan al equipo de TI, impidiendo reaccionar a tiempo ante riesgos reales y críticos. Esto, a su vez, provoca remediaciones costosas e incluso la necesidad de asignar más personal para resolver el problema que pudo evitarse.
Incumplimiento regulatorio
Las filtraciones de seguridad pueden conducir a multas y sanciones para la organización.
Daños reputacionales para la organización
Una violación a la seguridad de la empresa llega a divulgarse (y hemos visto titulares en las noticias) e impacta a su reputación. Esto puede llevar a la pérdida de confianza de lo clientes… y, por consiguiente, generar menos ingresos.
Sobrecarga de trabajo para el staff de TI
Si el personal a cargo de la monitorización de las alertas se siente abrumado de notificaciones, pueden experimentar mayor estrés laboral. Ésta ha sido una de las causas de menor productividad y una alta rotación de personal en el área de TI.
Deterioro de la moral
La desmotivación del equipo puede hacer que dejen de involucrarse y volverse menos productivos.
¿Cómo evitar estos problemas de Fatiga de Alertas?
Si se diseñan las alertas antes de implementarlas, se convierten en alertas útiles y eficientes, además de ahorrar mucho tiempo y, en consecuencia, se reduce la fatiga de alertas.
Priorizar
La mejor forma de conseguir un alertado efectivo es usar la estrategia “menos es más”. Hay que pensar primero en las cosas absolutamente imprescindibles.
- ¿Qué equipos son absolutamente imprescindibles? Casi nadie necesita alertas en equipos de pruebas.
- ¿Cuál es la gravedad si cierto servicio no funciona adecuadamente? Los servicios de alto impacto deben tener el alertado más agresivo (nivel 1, por ejemplo).
- ¿Qué es lo mínimo que se necesita para determinar que un equipo, proceso o servicio NO está funcionando correctamente? A veces es suficiente monitorizar la conectividad del dispositivo, en otras ocasiones se necesita algo más específico, como el estado de un servicio.
Responder estas preguntas ayudará a saber cuáles son las alertas más importantes sobre las que necesitamos actuar inmediatamente.
Evitar falsos positivos
A veces puede ser complicado conseguir que las alertas sólo se disparen cuando realmente existe un problema. Configurar los umbrales correctamente es gran parte del trabajo, pero hay más opciones disponibles. Pandora FMS tiene varias herramientas para ayudar a evitar falsos positivos:
Umbrales dinámicos
Son muy útiles para ajustar los umbrales a los datos reales. Al activar esta función en un módulo, Pandora FMS hace un análisis de su histórico de datos, y modifica automáticamente los umbrales para que capturen los datos que se salen de lo normal.



- Umbrales FF: En ocasiones el problema no es que no hayamos definido correctamente las alertas o los umbrales, sino que las métricas que utilizamos no son del todo fiables. Pongamos que estamos monitorizando la disponibilidad de un dispositivo, pero la conexión a la red en la que se encuentra es inestable (por ejemplo, una red inalámbrica muy saturada). Esto puede hacer que se pierdan paquetes de datos o, incluso, que haya momentos en los que un ping no consiga conectar con el dispositivo a pesar de estar activo y llevando a cabo su función correctamente. Para estos casos, Pandora FMS cuenta con el Umbral FF (FF Threshold). Usando esta opción podemos configurar cierta “tolerancia” al módulo antes de cambiar de estado. De este modo, por ejemplo, el agente reportará dos datos críticos consecutivos para que el módulo cambie a estado crítico.
- Utilizar ventanas de mantenimiento: Pandora FMS permite deshabilitar temporalmente el alertado e incluso la generación de eventos de un módulo o agente concretos con el modo silencioso (Quiet). Con las ventanas de mantenimiento (Scheduled downtimes), esto se puede programar para que, por ejemplo, no salten alertas durante las actualizaciones del servicio X en la madrugada de los sábados.
Mejorar los procesos de alerta
Una vez que se hayan asegurado de que las alertas que se disparen son las necesarias, y que sólo saltarán cuando realmente ocurra algo, podemos mejorar mucho más el proceso como sigue:
- Automatización: El alertado no sólo sirve para enviar notificaciones; también se puede usar para automatizar acciones. Imaginemos que estamos monitorizando un antiguo servicio que a veces se satura, y cuando eso ocurre, la manera de recuperarlo es simplemente reiniciarlo. Con Pandora FMS podemos configurar la alerta que monitoriza ese servicio para que trate de reiniciarlo automáticamente. Para ello, sólo debemos configurar un comando de alerta que, por ejemplo, haga una llamada API al gestor de dicho servicio para que lo reinicie.
- Escalado de alertas: Siguiendo con el ejemplo anterior, con el escalado de alertas podemos hacer que la primera acción que realice Pandora FMS, cuando se dispara la alerta, sea un reinicio del servicio. Si en la siguiente ejecución del agente, el módulo sigue en estado crítico, podemos configurar la alerta para que, por ejemplo, se cree un ticket en Pandora ITSM.
- Umbrales de alerta (alert threshold): Las alertas tienen un contador interno que indica cuándo se deben disparar las acciones configuradas. Simplemente modificando el umbral de una alerta podemos pasar de tener varios correos al día avisándonos del mismo problema a recibir uno cada dos o tres días.

Esta alerta (de ejecución diaria) tiene tres acciones: en un primer momento, se trata de reiniciar el servicio. Si a la siguiente ejecución de alerta el módulo no se ha recuperado, se manda un correo al administrador, y si aún no se ha solucionado, se crea un ticket en Pandora ITSM. Si la alerta se mantiene disparada a la cuarta ejecución, se mandará un mensaje diario por Slack al grupo de operadores.
Otras formas de reducir el número de alertas
- La protección en cascada (Cascade Protection) es una herramienta inestimable en la configuración de un alertado eficiente, al omitir el disparo de alertas de dispositivos dependientes de un dispositivo principal. Con un alertado básico, si estamos monitorizando una red a la que accedemos por medio de un switch específico y este dispositivo tiene un problema, comenzaremos a recibir alertas por cada equipo de esa red a la que ya no podemos acceder. En cambio, si activamos la protección en cascada en los agentes de esa red (indicando que dependen del switch), Pandora FMS detectará que el equipo principal está caído, y omitirá el alertado de todos los equipos dependientes hasta que el switch vuelva a estar operativo.
- El uso de servicios puede ayudarnos no sólo a reducir el número de alertas disparadas, sino también el número de alertas configuradas. Si tenemos un clúster de 10 máquinas, quizá no sea muy eficiente tener una alerta para cada una de ellas. Pandora FMS permite agrupar agentes y módulos en Servicios, junto con estructuras jerárquicas en las que podemos decidir el peso de cada elemento y alertar en base al estado general.
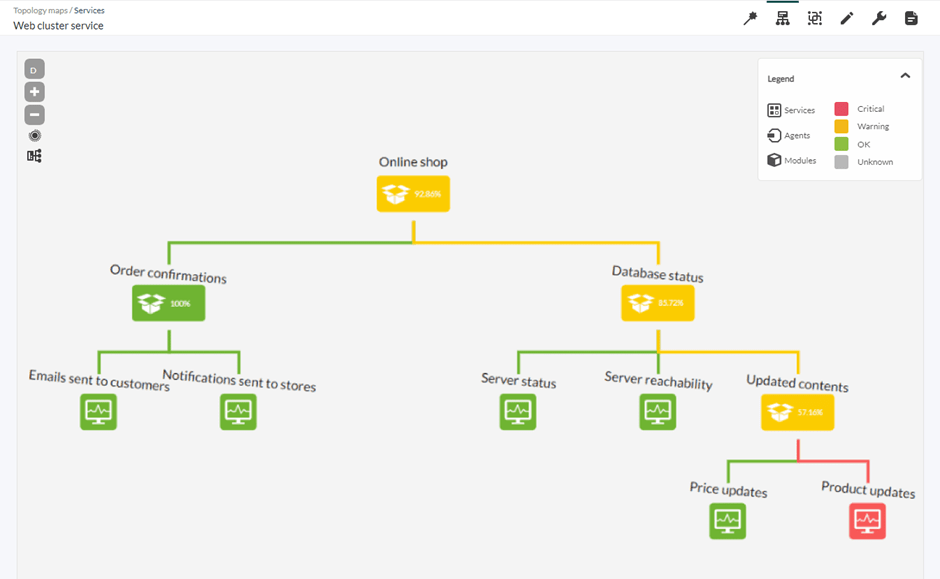
Implementar un plan de respuesta a incidentes
La respuesta a incidentes es el proceso de prepararse para las amenazas a la ciberseguridad, detectarlas a medida que surgen, responder para sofocarlas o mitigarlas. Las organizaciones pueden gestionar la inteligencia y mitigación de amenazas a través de la planificación de respuesta a incidentes. Hay que recordar que cualquier organización corre el riesgo de perder dinero, datos y reputación debido a las amenazas a la ciberseguridad.
La respuesta a incidentes requiere reunir un equipo de personas de diferentes departamentos dentro de una organización, incluyendo líderes de la organización, parte del staff de TI y otras áreas involucradas en el control y cumplimiento de datos. Se recomienda:
- Planificar cómo analizar datos y redes en busca de posibles amenazas y actividades sospechosas.
- Decidir qué incidentes deben recibir una respuesta primero.
- Tener un plan para la pérdida de datos y finanzas.
- Cumplir con todas las leyes pertinentes.
- Estar preparado para presentar datos y documentación a las autoridades después de una infracción.
Por último, un recordatorio oportuno: la respuesta a incidentes se volvió muy importante a partir del RPDG con normas extremadamente estrictas sobre informes de incumplimiento. Si hay que denunciar un incumplimiento concreto, la empresa debe tener conocimiento de ello en 72 horas y comunicar lo sucedido a las autoridades correspondientes. También se debe proporcionar un informe de lo sucedido y presentar un plan activo para mitigar el daño. Si una empresa no tiene un plan de respuesta a incidentes predefinido, no estará lista para presentar dicho informe.
LA RPDG también requiere saber si la organización cuenta con las medidas de seguridad adecuadas. Las empresas pueden ser fuertemente penalizadas si son examinadas después de la infracción y los funcionarios descubren que no contaban con la seguridad adecuada.
Conclusión
Está claro el alto costo tanto para el personal de TI (constante rotación, agotamiento, estrés, decisiones tardías, etc.) como para la organización (interrupción de las operaciones, filtraciones y violaciones de seguridad, sanciones bastante onerosas). Aunque no existe una solución única para evitar el exceso de alertas, sí se recomienda priorizar alertas, evitar falsos positivos (umbrales dinámicos y FF, ventanas de mantenimiento), mejoras en procesos de alertas y un plan de respuesta a incidentes, junto con políticas y procedimientos claros para responder a incidentes, con el fin de asegurarte de encontrar el equilibrio adecuado para tu organización.
Contáctanos para acompañarte con las mejores prácticas de Monitorización y alertas.
Si te interesó este artículo, puedes leer también: ¿Sabes para qué sirven los umbrales dinámicos en la monitorización?

Market analyst and writer with +30 years in the IT market for demand generation, ranking and relationships with end customers, as well as corporate communication and industry analysis.
Analista de mercado y escritora con más de 30 años en el mercado TIC en áreas de generación de demanda, posicionamiento y relaciones con usuarios finales, así como comunicación corporativa y análisis de la industria.
Analyste du marché et écrivaine avec plus de 30 ans d’expérience dans le domaine informatique, particulièrement la demande, positionnement et relations avec les utilisateurs finaux, la communication corporative et l’anayse de l’indutrie.









