








DRBD (Distributed Replicated Block Device) es un sistema para el almacenamiento replicado distribuido para la plataforma Linux. Permite tener un espejo remoto en tiempo real (equivalente a RAID-1 en red). DRBD se refiere tanto al software (módulo del kernel y las herramientas de gestión), y también a determinados dispositivos lógicos gestionados por el software.
El software DRBD es un software libre publicado bajo los términos de la GNU General Public License versión 2.
Para la instalación de DRBD para equipos con o sin Pandora FMS puedes apoyarte en su documentación https://www.drbd.org/docs/about/.
Si lo que necesitas es instalar Pandora FMS en un sistema de este tipo, puedes encontrar una explicación en nuestra WIKI de como hacer la instalación. https://wiki.pandorafms.com/index.php?title=Pandora:Documentation_es:DRBD
Dentro de las utilidades del DRBD podemos encontrar varios comandos que nos van a ser útiles para la monitorización de nuestro sistema DRBD (drbd-overview, drbdadm, crm status, cat /proc/drbd ).



1.- ESTADO GENERAL DEL CLUSTER
En DRBD , recurso es el término colectivo que se refiere a todos los aspectos de un conjunto de datos replicada en particular. Estos incluyen:
Nombre de recurso . Esto puede ser cualquier nombre de US- ASCII arbitraria que no contenga espacios en blanco en la que el recurso se refiere .
Volúmenes . Cualquier recurso es un grupo de replicación que consiste de uno de más volúmenes que comparten un flujo de replicación común . DRBD asegura la fidelidad de escritura a través de todos los volúmenes en el recurso. Los volúmenes se numeran empezando por 0 , y puede haber hasta 65.535 volúmenes en un solo recurso. Un volumen contiene el conjunto de datos replicados , y un conjunto de metadatos para uso interno DRBD .
A nivel drbdadm , con un volumen de un recurso puede ser abordado por el nombre del recurso y el número de volumen como <recurso> / <volumen> .
Dispositivo DRBD . Este es un dispositivo de bloque virtual gestionado por DRBD . Cuenta con un importante número de dispositivo de 147 , y sus números menores se numeran del 0 en adelante , como es habitual . Cada dispositivo de DRBD corresponde a un volumen en un recurso . El dispositivo de bloque asociado por lo general se llama /dev/drbdX , donde X es el número de dispositivo menor. DRBD también permite bloque nombres de dispositivos definidos por el usuario que debe , sin embargo , comenzar con drbd_ .
Connection. Una conexión es un enlace de comunicación entre dos hosts que comparten un conjunto de datos replicada . En el momento de escribir este artículo , cada recurso implica sólo dos hosts y exactamente una conexión entre estos servidores , por lo que en su mayor parte , los términos de los recursos y la conexión se pueden utilizar indistintamente .
A nivel drbdadm , una conexión se aborda en el nombre del recurso .
¿Cómo conocer el nombre de los recursos que hay instalados en el sistema?
El administrador del sistemas que ha instalado el drbd es el encargado de configurar el nombre de los recursos. Mediante el comando drbd-overview podemos obtener un listado de todos los recursos configurados en el sistema y de ahí obtener información de cada uno de los recursos como se muestra a continuación.
El comando drbd-overview nos sirve para sacar información general del clúster. Este comando nos muestra el estado del recurso, asi como su rol, el estado de sus discos, el filesystem montado y su porcentaje de uso del mismo.
Espacio usado en partición compartida
module_begin
module_name % Use filesystem <recurso>
module_type generic_data
module_exec drbd-overview <recurso> | gawk ‘{print $12}’ | tr -d %
module_unit %
module_end
A parte de tener la posibilidad de obtener el estado del recurso mediante el comando drbd-overview podemos hacerlo de igual forma mediante el comando drbdadm cstate.
El estado normal del recurso es Connected, en el caso de que sea otro estado se podría poner el estado del módulo en estado critico o warning dependiendo del estado que configuremos, en el ejemplo aparecerá en estado crítico siempre que no sea Connected el estado.
module_begin
module_name Status drbd <recurso>
module_type generic_data_string
module_exec drbdadm cstate <recurso>
module_str_critical Connected
module_critical_inverse 1
module_end
Podemos obtener el rol actual del recurso mediante el comando drbdadm role. El papel del nodo local se muestra en primer lugar, seguido por el papel del nodo socio que se muestra después de la barra. En este módulo es importante el cambio de estado. A la hora de crear una alerta, lo oportuno sería que en caso de cambio salte la alerta. Otro modo es configurar el estado crítico por ejemplo si la cadena no es (Primary/Secondary) para el nodo principal y (Secondary/Primary) para el nodo secundario.
Ej-. Primary/Secondary
module_begin
module_name Role drbd <recurso>
module_type generic_data_string
module_exec ddrbdadm role <recurso>
module_str_critical Primary/Secondary
module_critical_inverse 1
module_end
Para monitorizar el estado del filesystem asociado a cada recurso usaremos el comando drbdadm dstate. El estado normal del recurso es Connected, en el caso de que sea otro estado se podría poner el estado del módulo en estado critico o warning.
Ej.- UpToDate/UpToDate
module_begin
module_name Filesystem Status
module_type generic_data_string
module_exec drbdadm dstate <resource>
module_str_critical UpToDate/ UpToDate
module_critical_inverse 1
module_end
2.- INDICADORES DE RENDIMIENTO
Mediante el comando cat /proc/drbd obtenemos muchos indicadores de rendimiento del cluster:
$ cat /proc/drbd
version: 8.4.0 (api:1/proto:86-100) GIT-hash: 09b6d528b3b3de50462cd7831c0a3791abc665c3 build by [email protected], 2011-10-12 09:07:35 0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r—–
ns:0 nr:0 dw:0 dr:656 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
** Antes de generar los módulos es importante saber a qué volumen esta asociado el recurso en cada caso. Para el volumen y el recurso al que está asociado lo podemos conocer mediante el comando » service drbd status» siendo la salida algo así:
#service drbd status
drbd driver loaded OK; device status: version: 8.3.7 (api:88/proto:86-91) GIT-hash: ea9e28dbff98e331a62bcbcc63a6135808fe2917 build by root@drbd1, 2013-11-05 18:41:46
m:res cs ro ds p mounted fstype
0:srv Connected Primary/Secondary UpToDate/ UpToDate C
Viendo la salida anterior para configurar los siguientes módulos hay que cambiar la X de la configuración de los mismos por el orden en el que aparezcan en el comando anterior. Por ejemplo, en el caso anterior solo tenemos configurado un recurso por lo tanto cambiamos la X por un 1.
Si tuviesemos por ejemplo estos dos recursos:
0:srv Connected Primary/Secondary UpToDate/ UpToDate C
1:var Connected Primary/Secondary UpToDate/ UpToDate C
Para sacar los módulos que corresponden al recurso srv, debemos cambiar la X por un 1 que es el que esta en primer lugar, y para sacar los módulos del recurso var usaremos un 2, ya que esta en el segundo lugar, y así respectivamente.
ns ( Network Send ) . Volumen de datos netos envía al socio a través de la conexión de red ; en Kb .
module_begin
module_name Network_Send_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep ns: | gawk ‘{print $1}’ | tr -d ns: | head -X | tail -1
module_end
nr ( Network received ) . Volumen de datos netos recibidos por el socio a través de la conexión de red , en Kb.
module_begin
module_name Network_Received_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep nr: | gawk ‘{print $2}’ | tr -d nr: | head -X | tail -1
module_end
dw (Disk Write ) . Datos netos suscritas en el disco duro local , en Kb .
module_begin
module_name Disk_write_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep dw: | gawk ‘{print $3}’ | tr -d dw: | head -X | tail -1
module_end
dr ( Disk Read ) . Datos netos leen desde el disco duro local , en Kb .
module_begin
module_name Disk_read_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep dr: | gawk ‘{print $4}’ | tr -d dr: | head -X | tail -1
module_end
al ( Activity Log ) . Número de cambios del log.
module_begin
module_name Activity_log_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep al: | gawk ‘{print $5}’ | tr -d al: | head -X | tail -1
module_end
bm (Bit Map) . Número de cambios del área de mapa de bits de los metadatos.
module_begin
module_name Bit_map_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep bm: | gawk ‘{print $6}’ | tr -d bm: | head -X | tail -1
module_end
lo ( Local Count) . Número de solicitudes abiertas al subsistema de E / S local emitida por DRBD .
module_begin
module_name Local_count_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep lo: | gawk ‘{print $7}’ | tr -d lo: | head -X | tail -1
module_end
pe (Pending) . Número de solicitudes enviadas a la pareja, pero que aún no han sido respondidas por este último .
module_begin
module_name Pending_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep pe: | gawk ‘{print $8}’ | tr -d pe: | head -X | tail -1
module_end
ua ( Unacknowledged ) . Número de solicitudes recibidas por el socio a través de la conexión de red , pero que aún no han sido contestadas.
module_begin
module_name Unacknowledged_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep ua: | gawk ‘{print $9}’ | tr -d ua: | head -X | tail -1
module_end
ap ( Application Pending ) . Número de solicitudes de bloque de E / S remitidos a DRBD , pero aún no respondida por DRBD .
module_begin
module_name Aplication_pending_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep ap: | gawk ‘{print $10}’ | tr -d ap: | head -X | tail -1
module_end
ep ( epochs ) . Número de objetos de época . Por lo general, 1 . Podría aumentar con carga de E / S cuando se utiliza la barrera o el método de ordenación de escritura ninguno.
module_begin
module_name Epoch_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep ep: | gawk ‘{print $11}’ | tr -d ep: | head -X | tail -1
module_end
wo ( Write Order ) . Método de ordenación usado actualmente : b ( barrera) , f ( flush ) , d ( de drenaje ) o n ( no ) .
module_begin
module_name Write_Order_<Recurso>_DRBD
module_type generic_data_string
module_exec cat /proc/drbd | grep wo: | gawk ‘{print $12}’ | tr -d ua: | head -X | tail -1
module_end
oos ( Out of Sync ) . Cantidad de almacenamiento actualmente fuera de sincronía , en kb .
module_begin
module_name Out_of_sync_<Recurso>_DRBD
module_type generic_data
module_exec cat /proc/drbd | grep oos: | gawk ‘{print $13}’ | tr -d oos: | head -X | tail -1
module_end
3.- ESTADO DE LAS INSTANCIAS
Además de estos comandos indicados, si tenemos configurado el clúster mediante crm, podemos monitorizar otros aspectos mediante el uso del comando crm_mon -1 o crm status.
Con la salida de este comando podemos ver el estado de los nodos configurados, el estado de los diferentes recursos y las instancias que están corriendo dentro de ese recurso.
Podemos observar una posible salida de este comando:
============
Last updated: Wed Nov 6 02:46:33 2013
Stack: openais
Current DC: drbd1 – partition with quorum
Version: 1.0.8-042548a451fce8400660f6031f4da6f0223dd5dd
2 Nodes configured, 2 expected votes
2 Resources configured.
============Online: [ drbd1 drbd2 ]
Resource Group: srv
fs_mysql (ocf::heartbeat:Filesystem): Started drbd1
ip_mysql (ocf::heartbeat:IPaddr2): Started drbd1
mysqld (lsb:mysql): Started drbd1
apache2 (lsb:apache2): Started drbd1
pandora_server (lsb:apache2): Started drbd1
Master/Slave Set: ms_drbd_mysql
Masters: [ drbd1 ]
Slaves: [ drbd2 ]
Como podemos observar, tenemos en el recurso “srv” el mysql, apache2, pandora_server, una dirección de IP (Heartbeat) y el filesystem compartido.
A continuación se indica la configuración a seguir para cada uno de los casos:
module_begin
module_name Mysql_drbd_status
module_type generic_data_string
module_exec crm status | grep <nombre_equipo>* | grep mysqld | gawk ‘{print $3}’
module_str_critical Started
module_critical_inverse 1
module_endmodule_begin
module_name Apache_drbd_status
module_type generic_data_string
module_exec crm status | grep <nombre_equipo>* | grep apache | gawk ‘{print $3}’
module_str_critical Started
module_critical_inverse 1
module_endmodule_begin
module_name Pandora_server_drbd_status
module_type generic_data_string
module_exec crm status | grep <nombre_equipo>* | grep pandora_server | gawk ‘{print $3}’
module_str_critical Started
module_critical_inverse 1
module_endmodule_begin
module_name fs_mysql_status
module_type generic_data_string
module_exec crm status | grep <nombre_equipo>* | grep fs_mysql | gawk ‘{print $3}’
module_str_critical Started
module_critical_inverse 1
module_end
* El nombre del equipo es aquel que podemos obtener mediante el comando hostname en cada uno de los equipos del drbd y que a su vez será el nombre con el que se ha llamado a cada uno de los equipos en el fichero /etc/drbd.conf.
Otro de los puntos claves a monitorizar en un sistema DRBD es el Heartbeat. Como vimos anteriormente mediante el comando crm_mon -1 podemos monitorizar si esta iniciado. También lo podremos realizar mediante un chequeo tcp o un chequeo web apuntando directamente a la IP configurada en el heartbeat.
Si se trata de la propia consola de PandoraFMS es útil para monitorizarla si la IP virtual no nos deja acceder, sin embargo a través de la IP del nodo que este iniciado si funcione, nos avisaría de que algo esta pasando con la IP virtual.
Podemos saber los procesos que están corriendo del heartbeat a través del siguiente módulo y si no hay ninguno corriendo nos reporte el módulo en estado crítico:
module_begin
module_name Heartbeat Processes
module_type generic_data
module_exec ps aux | grep heartbeat | grep -v grep | wc -l
module_max_critical 0,5
module_min_critical -1
module_end
module_begin
module_name IP_mysql_status
module_type generic_data_string
module_exec crm status | grep <nombre_equipo> | grep fs_mysql | gawk ‘{print $3}’
module_str_critical Started
module_critical_inverse 1
module_end
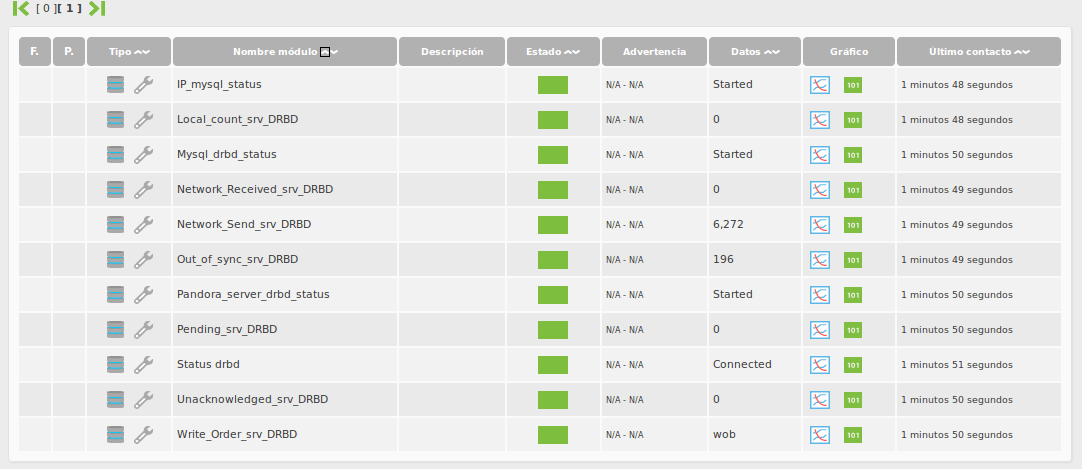
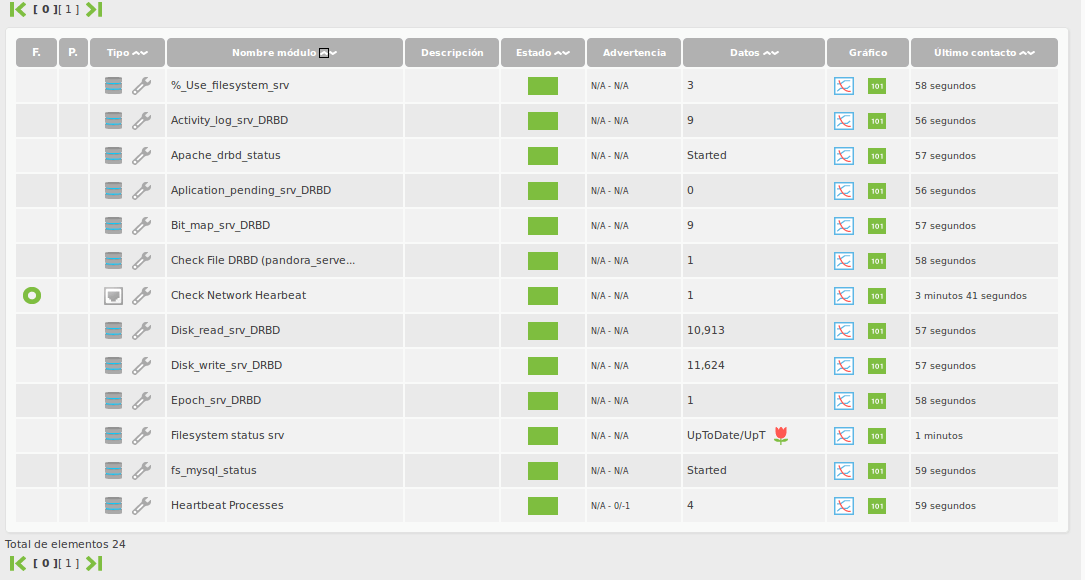
4.- RESUMEN DE LOS MÓDULOS DE MONITORIZACIÓN OBTENIDOS EN PANDORA FMS.
Todos los módulos que hemos sacado de los diferentes comandos de administración de los que dispone el drbd, se tratan de módulos locales y deberán configurarse en el fichero de configuración del agente ( /etc/pandora/pandora_agent.conf ) tal y como se muestran anteriormente.
- % Use filesystem <recurso>. Porcentaje de uso del filesystem asociado al recurso
- Status drbd <recurso>.– Estado del recurso dentro del drbd
- Role drbd <recurso>. Rol del recurso dentro del drbd
- Filesystem Status . Estado del filesystem asociado al recurso.
- Network_Send_<Recurso>_DRBD.– KBytes enviados a el socio a través de la conexión de red.
- Network_Received_<Recurso>_DRBD.- KBytes recibidos desde el socio.
- Disk_write_<Recurso>_DRBD.– KBytes escritos por el recurso en el equipo local
- Disk_read_<Recurso>_DRBD.– KBytes leidos por el recurso en el equipo local
- Activity_log_<Recurso>_DRBD.- Número de cambios del log
- Bit_map_<Recurso>_DRBD.- Cambios del área de mapa de bits
- Pending_<Recurso>_DRBD.– Número de solicitudes enviadas a la pareja, pero que aún no han sido respondidas por este último
- Local_count_<Recurso>_DRBD.-Número de peticiones abiertas al subsistema de E / S local emitida por DRBD
- Unacknowledged_<Recurso>_DRBD.- Número de solicitudes recibidas por el socio a través de la conexión de red , pero que aún no han sido contestadas.
- Epoch_<Recurso>_DRBD.– Número de objetos de época
- Aplication_pending_<Recurso>_DRBD.-Número de bloque de E / S de las solicitudes remitidas a DRBD, pero aún no respondida por DRBD.
- Write_Order_<Recurso>_DRBD.– Método de escritura
- Out_of_sync_<Recurso>_DRBD.– Cantidad de almacenamiento actualmente fuera de sincronía, en kibibytes.
- Mysql_drbd_status.– Estado de la instancia Mysql
- Apache_drbd_status.– Estado de la instancia Apache
- Pandora_server_drbd_status .- Estado de la instancia Pandora_server
- fs_mysql_status .– Estado del filesystem de la instancia Mysql
- Heartbeat Processes.– Número de procesos corriendo del Hearbeat
- IP_mysql_status .- Estado del heartbeat.
Monitorización DRBD con Nagios
Nagios, para monitorizar el estado de un DRBD utiliza un plugin llamado check_drbd que lo podemos encontrar en la librería de plugins de la web de Nagios.
Mediante el plugin check_drbd conseguimos obtener el estado del drbd con una salida como esta:
DRBD OK: Device 0 Primary Connected Consistent
Estos datos son los que conseguiremos ver con la salida del plugin, aunque dependerá de los parámetros que le pasemos para que sea una salida u otra.
Parametrización del Plugin check_drbd
-d STRING [Por defecto: 0. Se indicará mediante este string el recurso a monitorizar (0,1,2,3,…) ]
-p STRING [Por defecto: /proc/drbd. Indicaremos la ruta donde se encuentra este archivo en el caso que sea otra]
Los siguientes parámetros configurarán el estado final de la salida del plugin.
-e STRING [Debe ser el estado conectado. Ejemplo: Connected]
-r STRING [Debe ser el estado del nodo. Ejemplo: Primary]
-o STRING [Cambie el valor a OK. Ejemplo: StandAlone]
-w STRING [Cambie el valor a WARNING. Ejemplo: SyncingAll]
-c STRING [Cambie el valor a CRITICAL. Ejemplo: Inconsistent,WFConnection]
Este plugin se puede usar ejecutandolo directamente en un agente nagios o bien de forma remota desde el servidor nagios. Si optamos por ejecurarlo desde el agente, deberemos copiar el plugin en la carpeta /usr/lib/nagios/plugins
Para instalarlo en el agente nrpe que usa nagios para ejecutar comandos de forma remota debemos añadir esta linea en su archivo de configuración (/etc/nagios/nrpe.cfg)
command[check_drbd]=/usr/lib/nagios/plugins/check_drbd -d $ARG1$
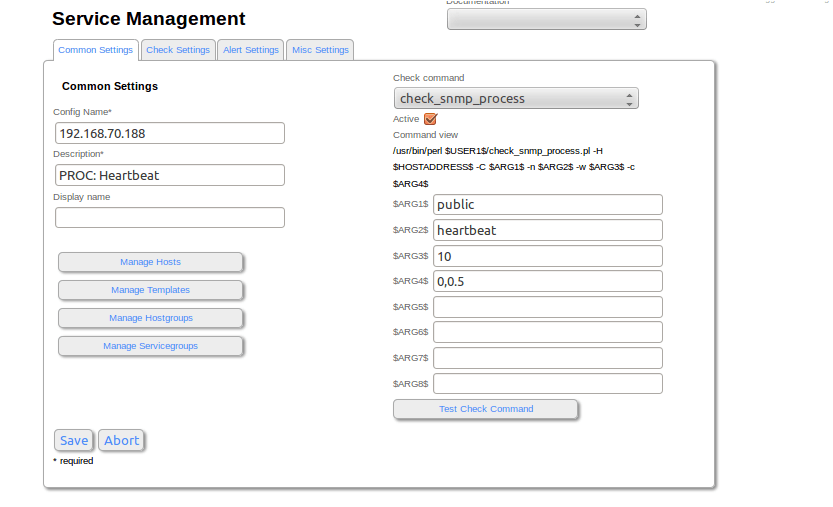
El último paso para crear este plugin es crear el servicio en la Consola de Nagios, para ello lo tendremos que realizar desde el CCM > Servicios, creando un nuevo servicio que use el comando check_nrpe para que de forma remota se ejecute en el servidor del drbd. El comando a configurar quedaría de la siguiente forma:
$USER1$/check_nrpe -H $HOSTADDRESS$ -t 30 -c check_drbd -d 0

El otro aspecto que se puede monitorizar a través de Nagios es el del número de procesos del Heartbeat. Esto lo podemos realizar mediante un chequeo snmp.
Primero hay que añadir el comando si no esta añadido en el command.cfg del servidor Nagios:
define command{
command_name check_process_snmp
command_line /usr/bin/perl $USER1$/check_snmp_process.pl -H $HOSTADDRESS$ -C $ARG1$ -n $ARG2$ -w $ARG3$ -c $ARG4$
}
Siendo los argumentos:
-C $ARG1$ : Comunidad snmp
-n $ARG2$ : Nombre proceso
-w $ARG3$ : <min_proc>[,<max_proc>] Umbral estado warning
-c $ARG3$ : <min_proc>[,<max_proc>] Umbral estado critical
Tras añadir el comando con estos argumentos, el siguiente paso es crear el servicio dentro del Host tal y como realizamos anteriormente con el servicio del Drbd Status, pero en este caso usando el comando check_process_snmp. Ejemplo de Configuración:
El resultado de los dos servicios es el que se muestra a continuación:
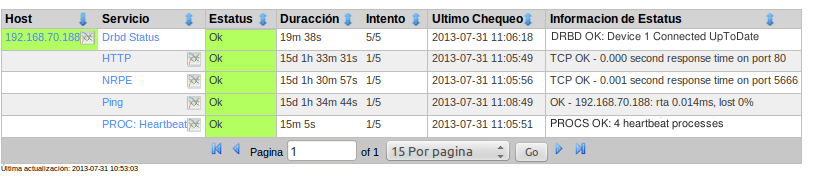
Con el otro servidor del drbd se debe realizar el mismo proceso.






