









Este artículo fue publicado por primera vez en 2018, algunos aspectos técnicos pueden estar desactualizados.
Integración Continua de Software: Jenkins, mayordomo a nuestro servicio
En una entrega anterior explicamos de manera práctica y detallada lo que se define como Liberación Continua de software y hoy veremos el paso previo: la Integración Continua de software, pero desde el punto de vista de las herramientas automatizadas. Elegimos a Jenkins con propósitos didácticos, ya que está escrito bajo licencia de software libre y es muy flexible, tal como lo es Pandora FMS.
Primero expondremos unos consejos prácticos para contrastarlo con Jenkins, lo que será igualmente válido para cualquier otro software similar, tal como Buildbot o GitLab CI, o incluso herramientas más avanzadas, como Concourse o Drone (de hecho existe un complemento de Jenkins para Drone), que combinan la Integración Continua y la Liberación Continua de software.
Integración Continua (lo único constante es el cambio)
La Integración Continua es ardua de implementar, pero una vez esté enraizada y bien alimentada los programadores siempre se preguntarán : ¿Cómo hemos podido vivir sin esto? Para explicar su funcionamiento debemos detenernos brevemente en lo que es un repositorio de software y un sistema de control de versiones.
¿Cómo funciona un repositorio de software?
Un repositorio de software agrupa todos los ficheros necesarios para que un programa o sistema pueda ser compilado o instalado en un ordenador. Si, a su vez, un software de control de versiones se encarga de su administración, tendremos entonces la combinación perfecta para que un nuevo programador comience a trabajar en el desarrollo de código (esta masificación del trabajo se conoce como cadena de procesos).
Actualmente, el sistema más extendido de control de versiones escrito en software libre es Git, el cual permite una copia distribuida de todo el código empleado en una aplicación o proyecto. Así, un nuevo empleado podrá obtener una copia de todo el proyecto, hacer las modificaciones en esa copia y, una vez finalizado, realizar las pruebas de compilación (convertir lenguaje de alto nivel a lenguaje de bajo nivel o lenguaje de máquina) y las pruebas con las bases de datos o procesamiento de datos.
Una vez se haya asegurado de que todo está bien, habrá que revisar si el proyecto ha sido modificado; en este caso descargará (automáticamente) los archivos modificados y le será presentado un resumen si estas actualizaciones afectan al trabajo que acaba de realizar. De ser así -y generalmente sucede que dos programadores trabajan a la vez en un mismo código- corregirá, asimilará y combinará el nuevo código.
Luego de toda esta odisea, volverá a compilar y probar, y finalmente «subirá» al repositorio su contribución; pero allí no habrá finalizado su trabajo: ahora entra en acción Jenkins, nuestro software que se encargará de hacer las pruebas de manera automática y, de ser aprobado, su trabajo habrá finalizado (y se podrá repetir el ciclo).
Consejos a seguir en la Integración Continua
A vox populi hemos recogido los mejores consejos a seguir para obtener los mejores resultados en la Integración Continua de software. Si consideran que falta alguno les invitamos a dejar un comentario.
- Colocar todo en el repositorio principal: Exceptuando credenciales, contraseñas y claves privadas. Del resto todo debe estar en el repositorio; no hablamos solo del código fuente sino también los guiones de prueba, archivos de propiedades, estructuras de bases de datos, guiones de instalación y librerías de terceros. Se deberá advertir a los programadores que los ficheros temporales o precompilaciones que hagan los entornos de programación (fácilmente reconocibles por sus extensiones de archivo) no sean «subidos» al repositorio principal.
- Un tronco principal con muy pocas ramas: Volviendo al ejemplo del empleado nuevo como programador, es deseable crear una rama de desarrollo para asignarle un trabajo, por ejemplo, corregir un bug. Dicha rama debe ser de corta duración para luego agregarla al tronco principal, con la ventaja de que incluso se probará dos veces con Jenkins.
- Disciplina: El trabajo de los programadores debe ser realizarlo al pie de la letra y contribuir al repositorio tan frecuentemente como sea posible.
- La regla de oro: Mientras más tiempo pase sin hacer compilación, más difícil será encontrar los bugs, y en el peor escenario posible se solaparían unos con otros, dificultando sus detecciones.
- Las pruebas de compilación deben ser rápidas: Aproximadamente a los 10-20 minutos de haber subido un programador su contribución, se debe emitir una aprobación o rechazo, gráficamente en una página web o por correo electrónico. Para lograr esto se deben tener unas consideraciones especiales que revisaremos cuando conozcamos un poco mejor a Jenkins.
Automatizando los procesos con Jenkins
Nuestra Integración Continua de software, aplicada a nuestra cadena de procesos, necesita liberarnos del trabajo de probar la precompilación, compilación e incluso instalación (creación de bases de datos, configuración de valores predeterminados, etcétera). Para ello Jenkins, software cuyo logotipo muestra a un mayordomo inglés siempre presto para ayudarnos en nuestro día a día, es uno de los tantos escrito en software libre bajo la permisiva licencia MIT y que se ejecuta en GNU/Linux.

Anteriormente conocido como proyecto Hudson y hecho con lenguaje Java, fue creado por la empresa Sun Microsystems en el 2005 y posteriormente pasó a ser propiedad de la empresa Oracle al adquirir a la primera. Con la privatización de la empresa se hizo una bifurcación de código: nace así Jenkins en 2011.
Instalarlo es muy sencillo: deberemos agregar la clave pública desde su sitio web, añadirla a la lista de repositorios e instalarla por línea de comando. Jenkins ofrece una interfaz web, por lo que necesitaremos tener instalado Apache o Ngix como servidor web, además de un motor de correo electrónico para las notificaciones, y una vez activo nos ofrecerá instalar los principales complementos o plugins necesarios para trabajar.
Para Jenkins todo es un complemento, incluso la cadena de procesos. Debido a la multitud de complementos disponibles, es difícil replicar entornos de Jenkins en otros ordenadores. Podremos declarar nuestra Integración Continua mediante lenguaje Apache Groovy, el cual es derivado y simplificado de Java o simplemente crearemos por medio de la interfaz web los que necesitemos.
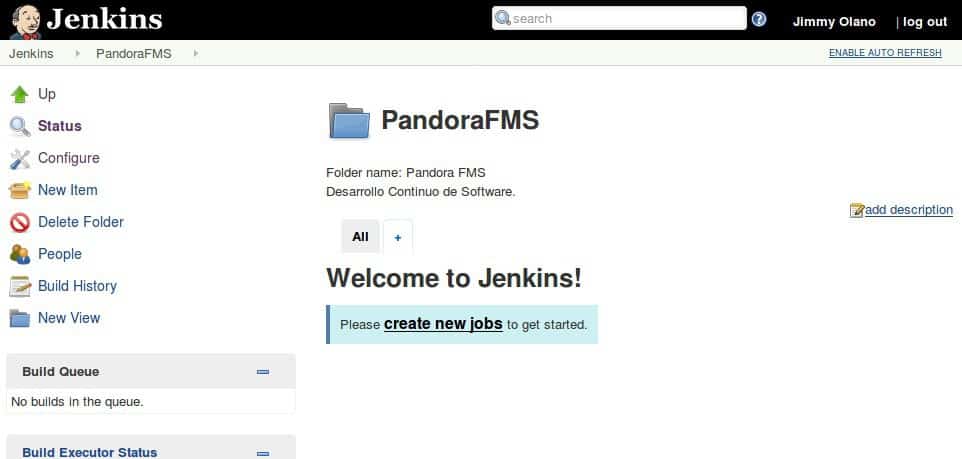
Aquí vemos la versatilidad de Jenkins: simplemente creamos, por medio de un complemento, una carpeta o directorio llamado Pandora FMS, para guardar allí los ficheros personalizados y relacionados con el proceso de Integración Continua, no del código fuente en sí mismo. Posteriormente debemos hacer un uso práctico: si tenemos nuestro proyecto alojado en GitHub, por medio de un complemento especial podremos especificarle nuestra identificación de usuario (y contraseña si el código es privado) y en un lapso de una a dos horas Jenkins se encargará de analizar nuestros repositorios por medio de la API de GitHub (de hecho esta API limita el uso por tiempo; por ello Jenkins tarda tanto tiempo en descargar, respetando las «reglas de etiqueta» en cuanto a uso de recursos se refiere).
Declarando nuestros identificadores en nuestro código fuente
Una vez hayamos conectado a Jenkins a nuestro repositorio y finalizado su análisis veremos la siguiente figura:
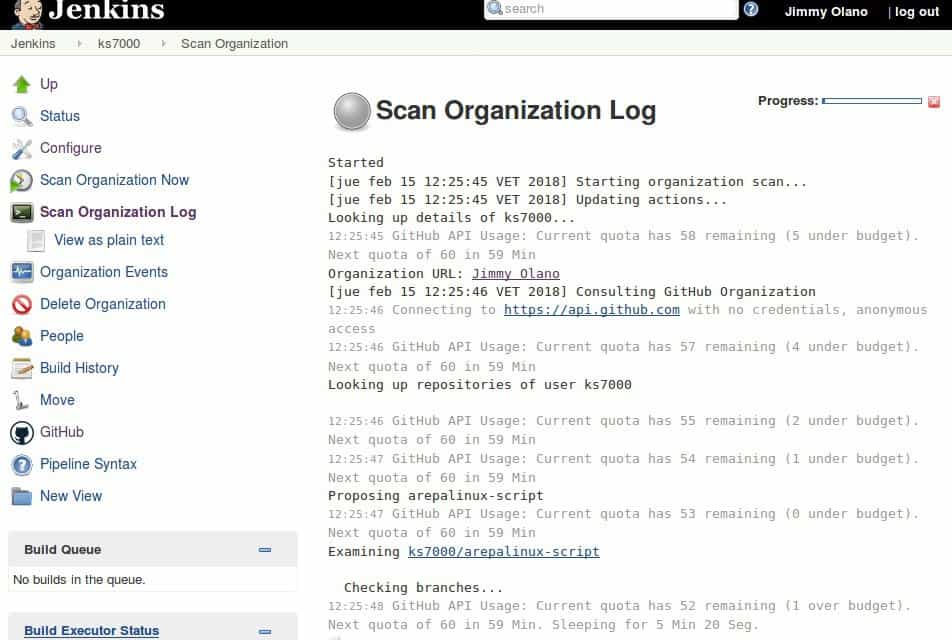
Por ejemplo, si usamos lenguaje Python deberemos incluir el siguiente fichero con extensión «.jenkins»:
/* Requires the Docker Pipeline plugin */
node('docker') {
checkout scm stage('Build') {
docker.image('python:3.5.1').inside {
sh 'python --version' }
}
}
Esto es lo que necesita Jenkins para crear un entorno contenido en Docker, un software que consume menos recursos que una máquina virtual y ofrece las mismas ventajas; así Jenkins puede proceder a crear un escenario de prueba para el lenguaje especificado y ejecutar python –version.
Especificando nuestras pruebas para la integración Continua
Ahora procederemos a agregar nuestros guiones y, aunque tardaremos un tiempo en crearlos, nos ahorrarán mucho tiempo ya que automatiza las tareas de compilación y pruebas. Un ejemplo de cómo instruir a Jenkins en GNU/Linux con sh:
pipeline {
agent any stages {
stage('Build') {
steps {
sh 'echo "Hola Mundo"'
sh ''' echo "Múltiples líneas permiten escalonar el trabajo"
ls –lah
'''
}
}
}
}
Los ambientes privativos también tiene soporte, para Microsoft Windows usaremos el proceso por lotes o bat:
pipeline {
agent any
stages {
stage('Build') {
steps {
bat 'set'
}
}
}
}
De igual manera haremos los respectivos guiones que permitan a cada lenguaje de programación ejecutar los respectivos compiladores, por nombrar unos pocos (libres y privativos):
- Apache Ant para lenguaje Java.
- MSBuild para la suite Visual Studio (MsBuild no necesita el Entorno de Desarrollo Integrado -IDE- para realizar esta tarea).
- Nant orientado a .NET framework.
- Rake para Ruby.
Hardware para nuestra batería de pruebas
Hoy en día el hardware ha quedado rezagado en comparación de las máquinas virtuales; con un solo equipo podremos correr varias de ellas. Jenkins necesita de una infraestructura para realizar su trabajo en pocos minutos y nos atrevemos a recomendaros lo siguiente:
- Una red de área local: bien administrada y planeada (automatizada) con PHIpam.
- Un repositorio de Sistemas Operativos (S.O.): con imágenes ISO de los S.O. que necesitemos, así como un repositorio y/o servidor proxy con las actualizaciones para ellos.
- Deberemos tener una máquina de integración manual: un ser humano debe corroborar el trabajo diario de Jenkins.
- Deberemos tener una o varias máquinas con compilaciones acumuladas: especialmente si nuestro proyecto funciona en varias plataformas o sistemas operativos, haremos los guiones necesarios para compilar parcialmente las diferencias integradas a lo largo del día; eso nos garantiza, en un primer nivel, aprobaciones rápidas de Jenkins.
- Varias máquinas para ejecuciones nocturnas: sobre S.O. «limpios» y también «actualizados» pero que no hayan recibido nuestro proyecto (haremos guiones para estos casos también), obteniendo aprobaciones en un segundo nivel.
- Máquinas con software pesado ya instalado y estables o que muy poco cambian: tales como base de datos, un entorno Java o incluso servidores web, para que sean utilizados por el resto de los ordenadores que hacen pruebas.
- Máquinas de integración modelos: configuradas con el mínimo, el recomendado y el máximo de hardware que recomendamos oficialmente para nuestro proyecto.
- Máquinas idénticas (en la medida de lo posible) a los servidores en producción: misma cantidad de RAM, núcleos, memoria de vídeo, dirección IP, etc.
En todos estos escenarios podremos echar mano de los ordenadores virtuales, para probar en máquinas reales por medio de la Implementación Continua de software.
En este punto recomendamos a Pandora FMS en el tema de la monitorización de la Integración Continua de software, como una manera de medir el estrés causado en dichos equipos con nuestro proyecto nuevo e instalado. El hecho de que esté correctamente compilado e instalado no quiere decir que haga lo que debe hacer; de hecho, en Pandora FMS ofrecemos el Pandora Web Robot (PWR) para aplicaciones web y Pandora Desktop Robot (PDR) para aplicaciones de escritorio y probar dichos escenarios con informes detallados y precisos.
Conclusión
Evidentemente que el desarrollo de software en el siglo XXI está en la pre-etapa del software creando software, pero eso ya entra en el campo de la inteligencia artificial.
Mientras tanto, en el presente, en Pandora FMS desde la versión 7.0 (Next Generation) utilizamos la Liberación Continua (rolling release) y nos adaptamos a las nuevas tecnologías gracias a nuestra flexibilidad. ¿Quieres saber más? Seguid este enlace https://pandorafms.com/es/
¿Dudas? ¿Comentarios acerca de Pandora FMS?
No dudes en contactarnos: https://pandorafms.com/es/empresa/contacto/

Programador desde 1993 en KS7000.net.ve (desde 2014 soluciones en software libre para farmacias comerciales en Venezuela). Escribe regularmente para Pandora FMS y ofrece consejos en el foro. También colaborador entusiasta en Wikipedia y Wikidata. Machacador de hierros en gimnasios y cuando puede se ejercita en ciclismo también. Fanático de la ciencia ficción. Programmer since 1993 in KS7000.net.ve (since 2014 free software solutions for commercial pharmacies in Venezuela). He writes regularly for Pandora FMS and offers advice in the forum. Also an enthusiastic contributor to Wikipedia and Wikidata. Crusher of irons in gyms and when he can he exercises in cycling as well. Science fiction fan.






