


















Sections
- Qu’est-ce que la supervision des bases de données ?
- Pourquoi il est important de superviser les bases de données
- Database Performance Monitoring vs Database Activity Monitoring
- Métriques clés dans la supervision des bases de données
- Supervision selon le type de base de données
- Incidents courants détectés par la supervision
- Bonnes pratiques pour superviser les bases de données
- Ce qu’un outil de supervision des bases de données doit inclure
- Supervision des bases de données, observabilité et CMDB
- Comment Pandora FMS aide à superviser les bases de données
- Questions fréquentes
- Conclusion
Si la base de données tombe, l’effet domino qui ruine notre semaine se met en marche, car les éléments suivants à s’effondrer sont les applications, puis les clients, les rapports, les automatisations et, enfin, le moral et la santé mentale de l’équipe d’astreinte.
C’est pourquoi ce guide aborde ce qu’est la supervision des bases de données, quelles métriques contrôler, quels incidents elle détecte, quelles bonnes pratiques appliquer et comment elle s’intègre dans notre stratégie globale d’observabilité.
Grâce à elle, nous disposerons d’un Palantír qui nous permettra de tout savoir et, plus important encore, d’agir à temps avant que les inévitables étincelles ne se transforment en incendie.
Qu’est-ce que la supervision des bases de données ?
Commençons par l’inévitable théorie.
La supervision des bases de données consiste à surveiller en continu la disponibilité, les performances, les requêtes, les connexions, le stockage, la réplication, les erreurs et la capacité des moteurs qui prennent en charge nos données critiques. L’objectif est de détecter les incidents avant qu’ils n’affectent le service.
Autrement dit, être L’Attrape-cœurs et ne pas attendre que l’utilisateur nous crie gentiment que le site web est lent. Avant d’en arriver là, une supervision doit nous permettre de détecter et de corriger.
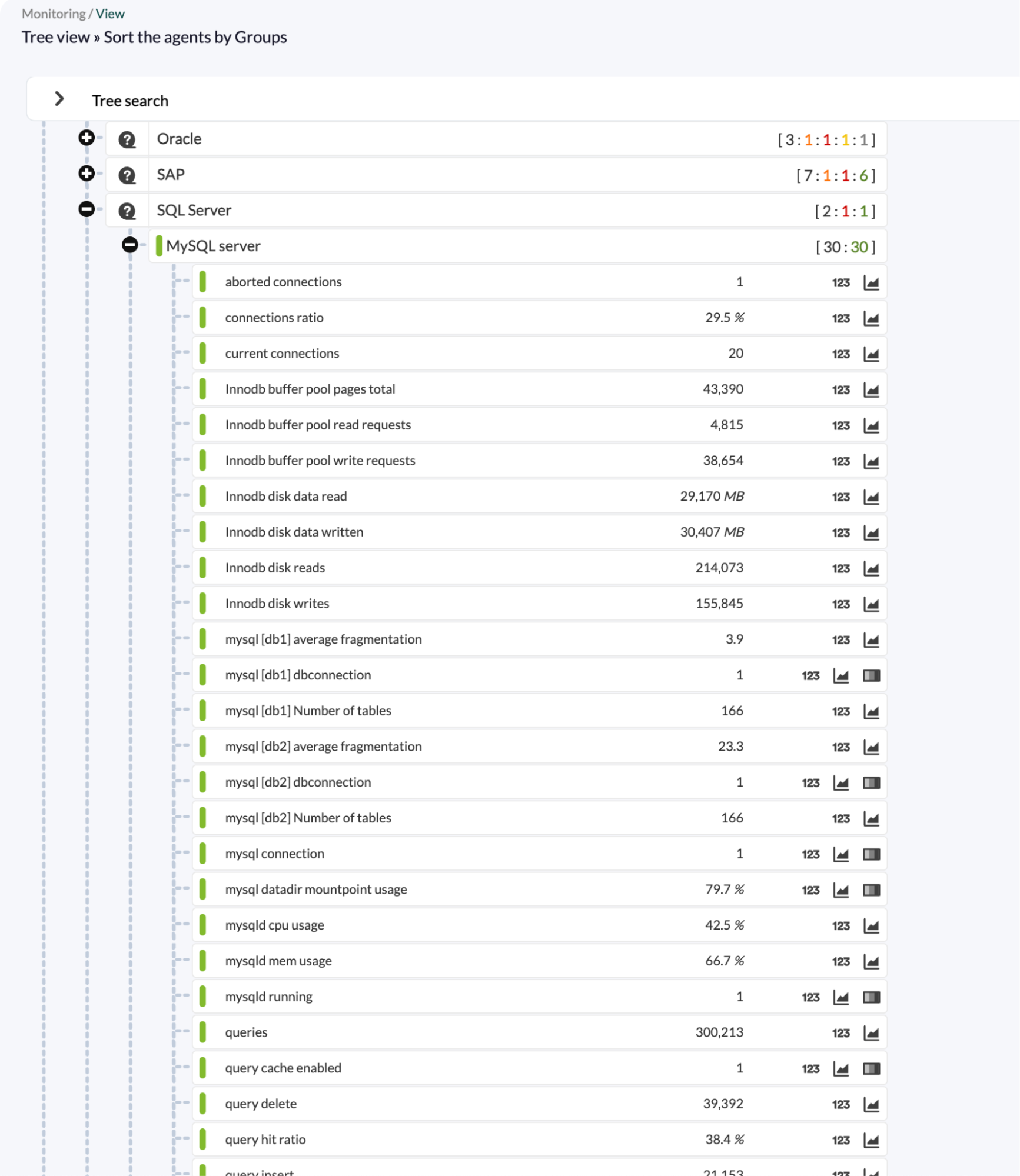
Vue générale et consolidée de MySQL dans Pandora FMS, permettant de contrôler visuellement et rapidement l’état des bases de données
Pourquoi il est important de superviser les bases de données
Les raisons sont aussi évidentes que souvent ignorées :
- Réduire les interruptions de service : en détectant une saturation des connexions avant qu’elle ne fasse tomber le service.
- Détecter toute dégradation avant qu’elle n’atteigne l’utilisateur : ainsi, une requête qui passe de 50 ms à 800 ms est un signal d’alerte sur lequel agir avant qu’il ne devienne un incident.
- Éviter la saturation du stockage : car l’espace disque se remplit généralement lentement lorsque personne ne regarde, au lieu de frapper soudainement.
- Optimiser les requêtes et les ressources : en identifiant les queries qui grippent le moteur de la BDD.
- Anticiper les incidents de capacité : en sachant combien de marge il nous reste avant de devoir nous battre avec la finance pour obtenir plus de matériel ou un scale-out.
- Réduire le MTTR : principalement en permettant à l’équipe d’arrêter d’éteindre des incendies les yeux bandés.
- Comprendre les dépendances entre base de données, application, serveur et réseau.
Le concept de « boîte noire » est actuellement à la mode dans l’IT et, sans supervision, la base de données en devient une, qui ne donne des signes de vie que lorsqu’elle cesse d’en donner. Il ne reste alors plus qu’à courir avec un défibrillateur, comme dans ces séries médicales où tout le monde finit par sortir avec tout le monde.
Database Performance Monitoring vs Database Activity Monitoring
Lorsque la supervision des bases de données entre en scène, ces deux approches l’accompagnent généralement, et il convient de les connaître sans les confondre :
- Database Performance Monitoring (DPM) : supervision orientée performances et opérations. Elle contrôle les latences, les requêtes lentes, le throughput, les connexions, les verrous, l’utilisation du CPU, de la mémoire, du disque et du réseau, la réplication, le stockage et la disponibilité. Autrement dit, c’est ce que l’on entend généralement par « superviser la base de données ».
- Database Activity Monitoring (DAM) : dans ce cas, la supervision est orientée activité, sécurité et audit. Elle observe les accès aux données, les utilisateurs et les sessions, les requêtes sensibles, les changements non autorisés, les comportements anormaux et la conformité réglementaire.
Sachant cela, ce guide se concentre sur la première approche, le DPM, axée sur les performances, la disponibilité et les opérations, même s’il convient de rappeler que la supervision de l’activité fait également partie d’une stratégie complète lorsqu’il existe des exigences réglementaires ou d’audit.
Métriques clés dans la supervision des bases de données
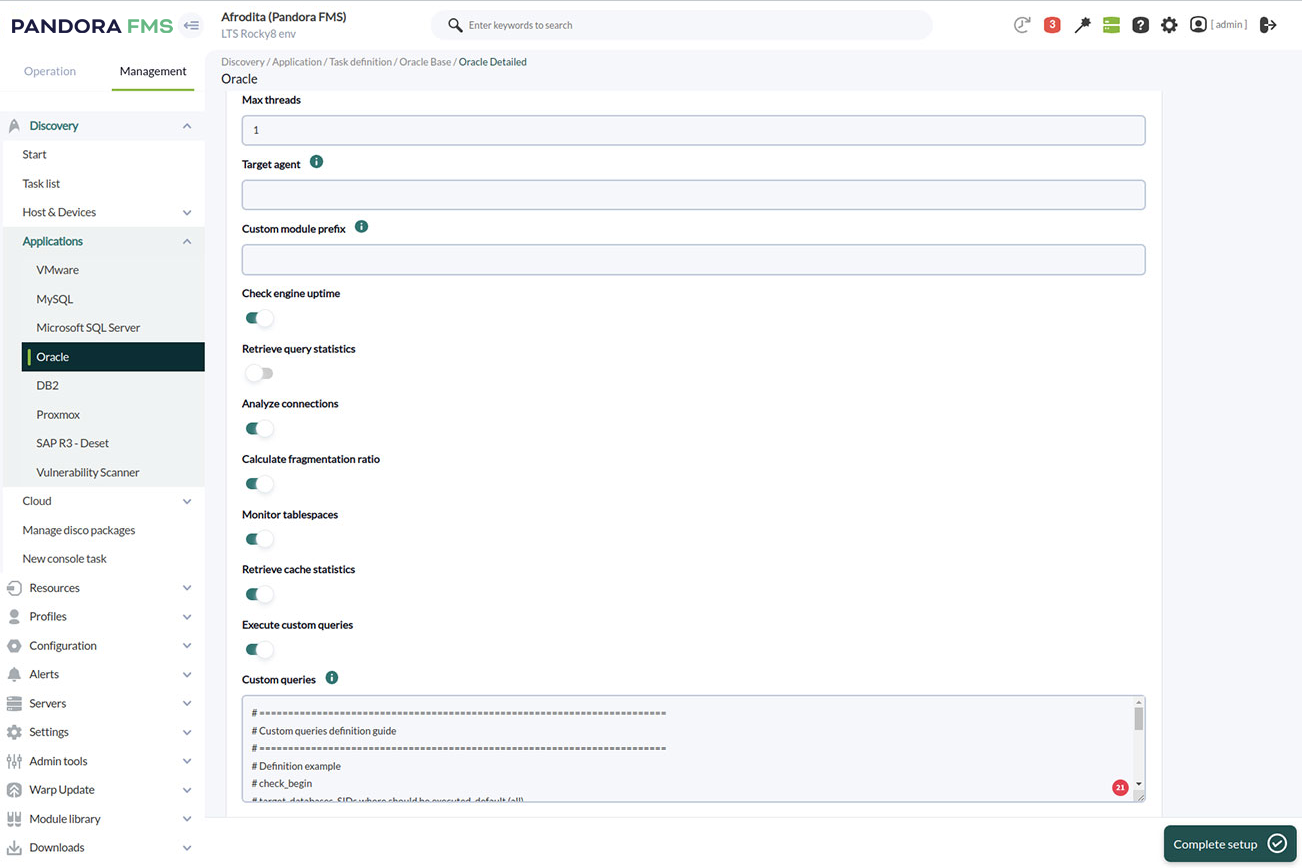
Sélection de métriques dans Pandora FMS pour superviser une base de données Oracle
En pratique, une supervision fournit des métriques, mais bien sûr, la vie a toujours eu ses hiérarchies et toutes ne doivent pas peser de la même manière dans nos décisions.
Sans oublier qu’un tableau de bord rempli de graphiques que personne ne regarde n’est rien d’autre qu’un bruit coûteux.
C’est pourquoi voici le bon grain qu’il faut séparer de l’ivraie et toujours garder sous surveillance.
Disponibilité et état du service
La première chose à contrôler est que les BDD fonctionnent, évidemment. Cela implique des indicateurs clés tels que :
- Uptime ou disponibilité du moteur.
- Réponse aux contrôles de santé.
- Erreurs de connexion.
- État des nœuds ou instances dans un cluster.
Performances
En plus de fonctionner, elles doivent le faire efficacement et ne pas traîner les pieds lors des requêtes. Cela implique le contrôle de métriques telles que :
- Latence de ces requêtes.
- Temps de réponse moyen et percentile 95/99.
- Requêtes lentes (slow queries).
- Throughput en requêtes par seconde.
- Locks, deadlocks et waits.
Utilisation des ressources
Efficacité et efficience ne sont pas la même chose, et nous voulons les deux, de sorte que fonctionner rapidement ne signifie pas que les processeurs doivent chauffer plus que le Soleil ni gaspiller une RAM qui vaut déjà plus que mes reins.
Pour cela, nous contrôlons :
- CPU consommé par le moteur.
- Mémoire utilisée et libre (buffer pool et cache).
- Disque (espace libre, IOPS, latence, etc.).
- Réseau (trafic et erreurs).
Connexions et sessions
Ici, ce qui nous intéresse, c’est le qui, comment et combien dans l’utilisation, ce qui implique de connaître :
- Connexions actives et maximums configurés.
- Saturation du pool de connexions.
- Sessions bloquées ou en attente.
Stockage et croissance
Les bases de données ont tendance à faire comme moi, grossir mystérieusement, surtout lorsque personne ne regarde ce que je fais.
Pour éviter que nos BDD n’occupent tout comme les tribbles de Star Trek, nous devons surveiller :
- Taille des bases de données et des tables.
- Croissance par unité de temps.
- Espace libre dans les tablespaces ou volumes.
- État des index (utilisation, fragmentation).
- Volume de logs (transactionnels et applicatifs).
Réplication, clustering et haute disponibilité
Ces indicateurs sont essentiels dans la supervision d’une gestion moderne des BDD :
- Lag de réplication afin d’éviter que les utilisateurs n’accèdent à des données obsolètes.
- État des réplicas et s’ils sont en ligne, en retard ou hors service.
- Failover et basculements pour les cas de défaillances, d’urgences ou de maintenances.
- Synchronisation des nœuds pour vérifier la cohérence des données entre eux et garantir que le quorum est actif afin de maintenir l’intégrité du système.
Backups et récupération
Peu importe que nous soyons les meilleurs et les plus rapides, le désastre finira par nous rattraper, donc nous devons aussi faire preuve d’humilité et travailler avec un filet de sécurité, pas seulement avec un réseau, même si celui-là aussi compte.
Pour cela, nous devons contrôler :
- L’état du dernier backup.
- Ancienneté de la dernière copie correcte, ce qui alimente réellement notre objectif de point de récupération (RPO, pour Recovery Point Objective).
- Erreurs dans les processus de copie.
- Durée de la dernière restauration de test. C’est la manière honnête de valider le RTO (objectif de temps de récupération), car un backup qui ne se restaure pas est une fausse illusion de sécurité.
Supervision selon le type de base de données
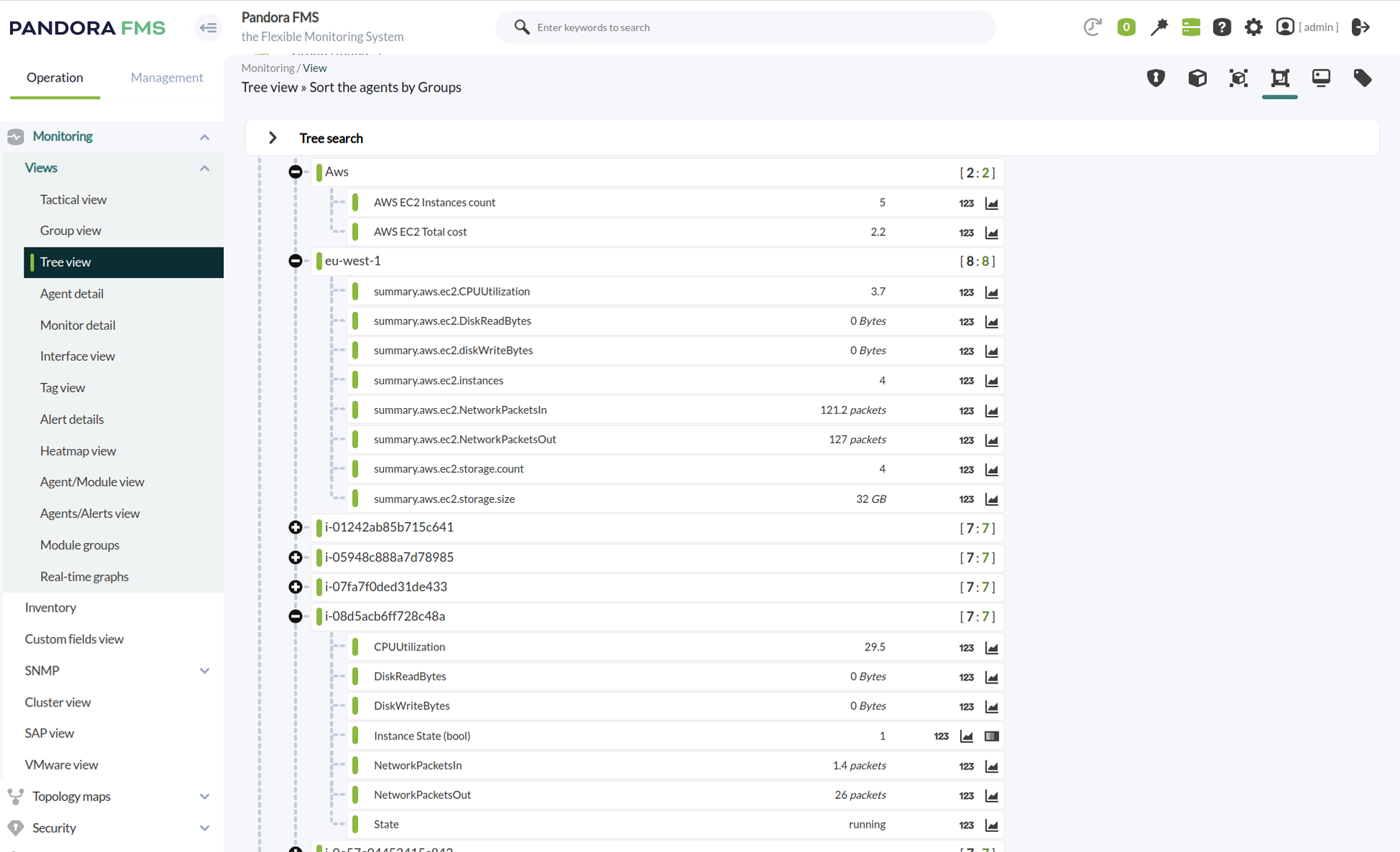
Pandora FMS supervisant un grand classique intemporel de l’entreprise, une base de données IBM DB2
De la même manière que les métriques ne sont pas toutes identiques, les bases de données ne le sont pas non plus. Ainsi, chaque modèle de données nécessite sa propre approche de supervision.
Même si je ne peux pas entrer ici dans le détail de chacun d’eux (enfin, je pourrais, mais cela transformerait cet article en L’Histoire sans fin), vous disposez d’un guide complet sur les types de bases de données. Nous y couvrons la taxonomie, tandis qu’ici nous nous concentrons sur ce qu’il faut surveiller dans chaque cas.
Comme nous le verrons, certains éléments sont communs à toutes les BDD, comme la disponibilité ou la latence, par exemple, tandis que d’autres sont plus spécifiques au type de base de données, comme le traversal ou temps de parcours lorsqu’il s’agit de bases de données orientées graphe.
Bases de données relationnelles
Nous incluons ici MySQL, PostgreSQL, Oracle, SQL Server ou MariaDB, et il est rare que notre infrastructure IT n’en comporte pas une (ou plutôt plusieurs).
Ici, il faut mettre l’accent sur :
- Requêtes lentes.
- Locks.
- Connexions.
- Index.
- Réplication.
- Stockage.
- Transactions.
Bien entendu, la première étape pour démarrer reste leur documentation officielle : PostgreSQL, MySQL, SQL Server et Oracle.
Bases de données NoSQL documentaires
Dans ce cas, des noms comme MongoDB, Couchbase ou RavenDB viennent à l’esprit. Ici, il est prioritaire de contrôler :
- Opérations par seconde.
- Utilisation de la mémoire.
- Réplication.
- Index.
- Temps de requête.
- Erreurs.
- Croissance des collections.
Pour cela, MongoDB dispose d’une documentation spécifique, et dans ce guide sur la manière de superviser RavenDB, nous entrons dans le détail pour vous donner un coup de main.
Par ailleurs, si vous souhaitez une vision plus large du côté non relationnel des BDD, ce guide sur les bases de données NoSQL offre une bonne vue d’ensemble du paysage.
Bases de données clé-valeur et cache
Redis ou Riak entrent en jeu dans ce cas, et nous devons surveiller de près :
- Mémoire consommée.
- Expiration des clés par TTL (expired keys).
- Évictions dues à la pression mémoire, qui, attention, ne sont pas la même chose que les expirations.
- Échecs et succès du cache.
- Persistance.
- Connexions.
- Latence.
Si nous l’utilisons, la documentation de Redis sur les benchmarks et l’optimisation est une référence incontournable.
Bases de données orientées colonnes
Cassandra ou HBase sont des noms courants sur ce terrain, et nous devons bien maîtriser :
- État du cluster.
- Le processus de compaction, c’est-à-dire le « nettoyage et l’organisation » réalisés par ces bases de données en raison de leur mode de fonctionnement.
- Latence de lecture et d’écriture.
- Distribution et taille des partitions.
- Réplication.
Ici, au moins, Cassandra documente ses métriques en détail.
Bases de données orientées graphe
Nous trouvons ici des candidats comme Neo4j, pour lesquels il faut bien contrôler :
- Temps de traversal, c’est-à-dire le parcours à travers le graphe, afin de vérifier son efficacité.
- Mémoire utilisée dans les requêtes complexes.
- Taille du graphe en nombre de nœuds et de relations stockés.
- Latence des requêtes.
- Disponibilité.
Bases de données de séries temporelles
InfluxDB, TimescaleDB, Prometheus ou OpenTSDB sont les noms que nous entendrons dans ce cas, et ce que nous devons contrôler ici passe par :
- Ingestion par seconde, soit les points de données reçus par unité de temps, afin de localiser les goulots d’étranglement.
- Cardinalité des séries, ou le nombre de combinaisons uniques d’étiquettes, la métrique qui cause le plus de désagréments lorsqu’elle explose, car elle peut épuiser la RAM et/ou bloquer la base de données.
- Rétention effective. Essentielle pour le contrôle des coûts et pour éviter que l’espace occupé ne s’emballe.
- Utilisation du disque et taux de compression. S’il est faible, le stockage n’est pas efficace.
- Latence des requêtes.
Incidents courants détectés par la supervision
Pandora FMS offrant une vue générale de l’état d’une BDD selon les métriques définies.
Dans les séries médicales que j’évoquais plus tôt, les personnages s’efforcent de trouver des maladies toujours plus rares, pour le drame, la nouveauté et le défi. Cependant, la réalité de la supervision des bases de données est généralement bien plus prosaïque et, après de nombreuses années d’expérience, les mêmes tableaux cliniques apparaissent presque toujours.
Ces suspects habituels sont :
- Requêtes très leeeeentes qui s’accumulent.
- Saturation des connexions, toutes essayant d’entrer en même temps par la porte, comme dans les films des Marx Brothers.
- Croissance anormale du stockage.
- Manque d’espace disque dû à ce qui précède.
- Dégradation des performances due à des index mal maintenus.
- Erreurs de réplication ou lag croissant dans ce processus clé qui permet à tout le monde de travailler avec les mêmes données.
- Backups échoués dont personne ne s’aperçoit jusqu’au moment de l’infarctus où vous en avez besoin.
- Interruptions intermittentes et effet de flapping, comme ces ampoules instables et irritantes qui n’arrêtent pas de clignoter.
- Consommation anormale de CPU ou de mémoire.
- Nœuds désynchronisés dans le cluster.
- Dégradation causée par le réseau ou l’infrastructure sous-jacente.
Une bonne supervision transforme les interruptions de plusieurs heures causées par l’un de ces incidents en un ajustement préventif de quelques minutes.
Bonnes pratiques pour superviser les bases de données
Dans Game of Thrones, Joffrey Baratheon, ce petit misérable, brandit l’épée Pleurs-de-Veuve, une majestueuse œuvre d’art en acier valyrien… Totalement inutile entre les mains d’un lâche incompétent. Il en va de même avec la supervision. C’est un outil, et cela la rend aussi bonne que les décisions et les compétences de la personne qui se trouve derrière.
C’est pourquoi, même si nous déployons des applications de supervision de pointe comme Pandora FMS, la réalité est que les bonnes pratiques sont les fondations de la maison que nous sommes en train de construire.
Et les meilleures d’entre elles sont :
- Définir les seuils selon la criticité et le comportement réel, et non en copiant les valeurs par défaut ou celles vues dans le dernier « contenu viral » sur LinkedIn.
- Séparer les alertes informatives, d’avertissement et critiques, afin de ne pas submerger les esprits délicats des techniciens remplis d’anime avec des notifications triviales.
- Éviter la fatigue liée aux alertes : car elles sont très tentantes et, en IT, nous avons tendance à être des maniaques du contrôle, mais si tout est urgent, rien ne l’est.
- Corréler les métriques de base de données avec celles du serveur, de l’application et du réseau, car rien n’est une île, encore moins dans l’IT.
- Superviser les tendances et pas seulement les états ponctuels, car une croissance lente, par exemple, est un signal d’alerte.
- Réviser la capacité et la croissance périodiquement, et pas seulement lorsque cela fait mal. Sur ce point, nous sommes souvent comme avec le dentiste, et la douleur due au manque de contrôles et de nettoyage est généralement similaire.
- Documenter les dépendances entre bases de données, services et applications. Nous devons connaître chaque recoin comme une araignée connaît sa toile, y compris ces relations.
- Valider les backups et la restauration, au lieu de supposer qu’ils fonctionnent simplement parce que le job s’est terminé en vert dans la console.
- Réviser les permissions et l’activité s’il existe des exigences d’audit.
- Ajuster les alertes par environnement. Car, dans de nombreux cas, ce qui peut être du bruit en développement peut être critique en production.
Ce qu’un outil de supervision des bases de données doit inclure

Pandora FMS, un outil de supervision de nouvelle génération
On pourrait imaginer ce qui vient ensuite : une sorte de brochure marketing vantant les mérites de notre outil, Pandora FMS. Pourtant, chez Pandora, nous pensons qu’il vaut mieux vous laisser le vérifier par vous-même si vous le souhaitez, plutôt que de demander à qui que ce soit un acte de foi.
De plus, au moment de choisir un outil, nous ne devons pas nous laisser guider par les marques, la réputation ou les discours commerciaux, mais par des fonctionnalités réellement adaptées à nos besoins.
Ainsi, les éléments que nous devrions examiner, en évaluant leur poids selon notre contexte opérationnel, seraient :
- Support de plusieurs moteurs, comme les bases relationnelles, NoSQL, time-series, etc.
- Obtenir une couverture de supervision SQL et NoSQL sans devoir passer d’un outil à l’autre et fragmenter encore davantage notre attention et notre temps de réponse.
- Disposer de métriques de performance accessibles et configurables.
- Alertes avec seuils personnalisables et multiples canaux.
- Tableaux de bord adaptables à chaque audience, qu’elle soit technique ou exécutive.
- Historique des métriques avec une rétention utile, et pas seulement des données de la dernière heure.
- Corrélation avec notre infrastructure spécifique (serveurs, réseau, cloud, etc.) afin de ne pas essayer de faire entrer une pièce carrée dans un trou rond.
- Rapports pour les clients, les audits et les SLA.
- Intégration avec les environnements cloud comme AWS, GCP ou Azure, ce qui est aujourd’hui indispensable.
- Capacité à détecter les tendances et les écarts.
- Simplicité opérationnelle pour les équipes IT et les MSP.
Supervision des bases de données, observabilité et CMDB
Les bases de données sont ce qui fait fonctionner les services de notre organisation, leur cerveau et leur mémoire. C’est pourquoi la supervision gagne en valeur lorsque l’on comprend quels services dépendent de chaque base de données.
Cette cartographie est le travail de la CMDB pour cartographier les actifs et les dépendances, et elle permet de savoir, lorsqu’une alerte apparaît, quels processus métier sont à risque.
C’est la différence entre : « La BD-23 s’est dégradée », ce qui ne provoque pas spécialement d’infarctus, et : « Le moteur de facturation de la France se dégradera dans quinze minutes si nous n’agissons pas ».
Voilà qui réveille bien le responsable qui somnole pendant la sieste.
Par-dessus, l’observabilité boucle la boucle en connectant les métriques avec les logs, les événements et l’expérience utilisateur, afin de ne pas seulement regarder, mais comprendre.
Résumée à son essence, la supervision répond à : « Est-ce sain ? », tandis que l’observabilité répond à : « Pourquoi cela se comporte-t-il ainsi ? ».
Les deux questions sont différentes et incomplètes l’une sans l’autre.
Comment Pandora FMS aide à superviser les bases de données
Pandora FMS supervisant chaque recoin et rapportant tout comme les corbeaux d’Odin
Maintenant, oui, il est temps de « parler de notre livre », car, modestie à part, Pandora FMS offre une supervision avancée des bases de données avec cette approche unifiée indispensable pour ne pas perdre la tête.
Cela permet une vision globale de l’infrastructure et de la manière dont toutes ses pièces s’imbriquent, car les BDD ne vivent pas seules : elles sont le cerveau de processus fondamentaux, et si le bip d’un encéphalogramme plat retentit soudainement, les conséquences se font sentir dans chaque recoin de notre monde technologique.
Ainsi, Pandora FMS fournit une supervision de base de données de pointe grâce à :
- Modules et plugins pour les moteurs les plus répandus (MySQL, PostgreSQL, Oracle, SQL Server, MongoDB…).
- Alertes configurables par seuil, fenêtre temporelle et criticité, avec escalade et canaux multiples.
- Tableaux de bord adaptés à chaque audience : technique, responsable de domaine, direction.
- Historique des métriques avec une rétention suffisante pour l’analyse des tendances et le capacity planning.
- Corrélation native avec les serveurs, les applications, le réseau, le cloud et les autres composants de l’infrastructure, et non comme des silos isolés.
- Vue centralisée depuis la même console utilisée pour superviser le reste de l’IT (notre métaconsole), ce qui réduit la charge cognitive et les changements d’outils pour les équipes.
- Utilité éprouvée pour les équipes IT, NOC, DevOps et MSP, en particulier lorsqu’il faut séparer les données par client ou par environnement.
Pandora FMS supervise, mais ne s’arrête pas là : elle alerte, corrèle et aide aussi au diagnostic, devenant l’œil du Big Brother qui voit tout.
Questions fréquentes
Afin de bien fixer les points importants, distillons les questions les plus fréquentes avec leurs réponses.
Qu’est-ce que la supervision des bases de données ?
La supervision continue de la disponibilité, des performances, des requêtes, des connexions, du stockage, de la réplication, des erreurs et de la capacité des moteurs de bases de données.
L’objectif ? Détecter les incidents avant qu’ils n’affectent le service.
Quelles métriques une base de données doit-elle superviser ?
Il s’agit d’un travail que chaque organisation doit réaliser selon son fonctionnement et ses priorités, mais au minimum : disponibilité, latence des requêtes, throughput, connexions actives vs maximales, utilisation CPU/mémoire/disque, locks et deadlocks, espace libre, lag de réplication, état des backups et erreurs.
Presque rien, surtout si l’on tient compte du fait que chaque type de moteur ajoute ensuite les siennes, comme nous l’avons vu plus haut.
Quelle est la différence entre database monitoring et database activity monitoring ?
Le premier (DPM) se concentre sur les performances, la disponibilité et les opérations. Le second (DAM) se concentre sur les accès, les utilisateurs, les requêtes sensibles, les changements non autorisés et la conformité.
Ils sont complémentaires, pas exclusifs.
Qu’est-ce que le database performance monitoring ?
Il s’agit de la discipline centrée sur la mesure et l’amélioration des performances d’une base de données.
Cela implique l’observation de la latence, de la vitesse des requêtes, des locks, de l’utilisation des ressources, de la réplication, du stockage et de la disponibilité.
Quels outils utilise-t-on pour superviser les bases de données ?
D’un côté, nous pouvons opter pour des plateformes généralistes comme Pandora FMS, ce qui apportera une intégration complète et une perspective large de supervision globale.
De l’autre, nous pouvons choisir des outils spécifiques au moteur (pg_stat_statements, Performance Schema, Oracle Enterprise Manager…), des solutions APM et des stacks d’observabilité.
Au final, l’important n’est pas la marque, mais la couverture et la corrélation avec le reste de notre infrastructure.
Comment détecter les requêtes lentes ?
En activant le slow query log dans le moteur, en instrumentant des traces ou en utilisant des vues de performance (pg_stat_statements, Performance Schema, DMVs).
Un bon outil de supervision les extrait, les agrège et les affiche dans des graphiques comparables dans le temps.
Pourquoi est-il important de superviser la réplication ?
Parce qu’un réplica en retard ou hors service fragilise la haute disponibilité. De même, une promotion en primaire avec des données non synchronisées à cause de problèmes de réplication peut entraîner une perte d’informations.
Comment la supervision aide-t-elle à réduire le MTTR ?
En détectant les incidents plus tôt et en fournissant le contexte qui accélère le diagnostic. Ainsi, réduire le MTTR cesse d’être un vœu pieux et devient la conséquence naturelle d’une exploitation avec visibilité.
Conclusion
Comme dans d’autres aspects de la discipline, la supervision des bases de données va bien au-delà du fait de vérifier si le service répond.
Elle doit également mesurer les performances, la capacité, la réplication, les erreurs, les backups, l’activité pertinente et les dépendances avec les applications et l’infrastructure.
Dans les environnements critiques, une stratégie de supervision adaptée permet d’anticiper les incidents, de réduire les temps de résolution et d’opérer avec un contrôle réel.
Comme sur la passerelle de l’Enterprise, il ne s’agit pas de regarder un écran, mais de disposer d’une connaissance de chaque aspect clé, d’une personne capable de la comprendre et de la discipline opérationnelle nécessaire pour agir avant que le vaisseau ne commence à subir des secousses.
Contactez notre service commercial, posez vos questions sur nos licences ou demandez un devis
