


















GPU monitoring for AI, HPC and hybrid infrastructures
Monitor NVIDIA GPUs with Pandora FMS and integrate utilization, memory, temperature, power consumption and status data into the same platform where you already monitor servers, networks, storage, services and logs.
Customers who trust us

LOGICIEL DE SUPERVISION GPU
Vos GPU ne peuvent pas être un angle mort dans votre infrastructure IT
Les infrastructures d’IA, de HPC, d’inférence et d’entraînement reposent sur des GPU qui concentrent coûts, performance et risque opérationnel. Un GPU saturé, en surchauffe, sous-utilisé ou présentant des erreurs non détectées peut dégrader les services, ralentir les processus critiques ou provoquer des défaillances en production.
Pandora FMS intègre les métriques GPU dans l’exploitation IT existante, avec les serveurs, le réseau, le stockage, les services et les logs. Sans plateformes séparées.
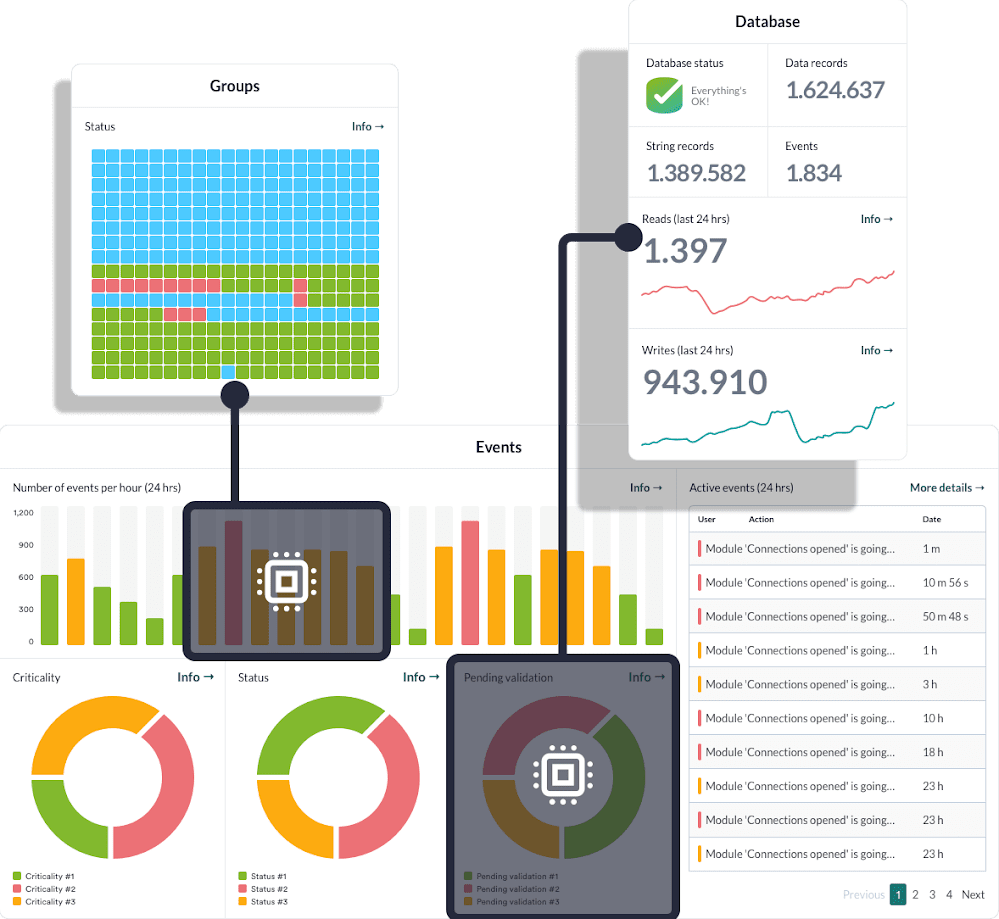
Console Pandora FMS · État GPU
FONCTIONNEMENT
Comment fonctionne la supervision GPU dans Pandora FMS
Le plugin agit comme un agent local sur l’hôte avec GPU NVIDIA, utilise nvidia-smi comme source de données et émet des modules que Pandora FMS intègre à son exploitation.
Hôte avec GPU NVIDIA
On-premise, hybride ou cloud
nvidia-smi
Source de données locale
Plugin local Pandora FMS
Agent qui émet des modules XML
Dashboards, alertes et rapports
Intégrés au reste de l’infrastructure
CAS D’UTILISATION
De la métrique à l’incident : la supervision GPU en conditions réelles
Il ne suffit pas de savoir qu’un GPU est à 95 %. Ce qui compte, c’est le contexte opérationnel.
Saturation prolongée
Un GPU à 95 % pendant des heures, avec une mémoire élevée et des erreurs dans le service d’inférence, n’est pas un pic normal. C’est un incident qui nécessite une intervention. L’historique permet de distinguer l’un de l’autre.
Risque thermique
Une température élevée prolongée combinée à des anomalies de ventilation peut anticiper une dégradation physique. La détecter avant la panne permet une intervention préventive plutôt qu’une réaction à une interruption.
Sous-utilisation
Un GPU coûteux avec une faible utilisation pendant plusieurs semaines peut indiquer une mauvaise allocation des workloads. L’historique fournit les données objectives pour justifier ou reporter les décisions matérielles.
Capacity planning
L’historique d’utilisation et de mémoire permet d’identifier la croissance de la demande, d’anticiper la saturation et de planifier les extensions avec des données plutôt qu’avec des estimations.
MÉTRIQUES SUPERVISÉES
Ce que vous pouvez superviser avec Pandora FMS
Pandora FMS collecte les métriques clés des GPU NVIDIA afin de détecter la saturation, la pression mémoire, le risque thermique, les erreurs et les défis de capacité.
- Utilisation du GPU (%)
- État opérationnel du GPU
- Mémoire utilisée, libre et totale (MiB)
- Pourcentage d’utilisation de la mémoire
- Température (°C)
- Consommation instantanée et limite de puissance (W)
- Vitesse de ventilation lorsque disponible
- Erreurs ECC lorsque disponibles
- Modèle de GPU et version du pilote
- Version CUDA prise en charge
nvidia-smi. La documentation technique du plugin sera disponible sur Marketplace.ALERTES
Alertes pour détecter la saturation, la température et les erreurs critiques
Pandora FMS permet de générer des alertes sur les métriques GPU afin de détecter la pression mémoire, les températures élevées, les erreurs ECC ou la perte de disponibilité. Les seuils peuvent être ajustés depuis la console selon le modèle de GPU et la politique d’exploitation.
Les seuils prédéfinis servent de référence et peuvent être modifiés depuis la console Pandora FMS.
COMPATIBILITÉ
Compatibilité et prérequis
Le plugin est conçu pour les environnements on-premise, hybrides et cloud avec des GPU NVIDIA exposés au système d’exploitation.
- GPU NVIDIA
- Linux (amd64 / arm64) — validé
- Windows (amd64) — en validation finale
- Environnements on-premise et hybrides
- AWS, Azure et Google Cloud si le GPU est exposé à l’OS
- Nécessite le pilote NVIDIA installé et
nvidia-smidisponible sur l’hôte.
Limitations actuelles
- Ne prend pas en charge les GPU AMD ni Intel
- Ne supervise pas les modèles d’IA, les prompts ni les métriques MLOps
- N’inclut pas la détection de drift ni une observabilité IA complète
- Pour les clusters avec de nombreux GPU par nœud, il peut être nécessaire de compléter avec DCGM ou d’autres solutions d’agrégation
Vous souhaitez vérifier si vos GPU NVIDIA sont compatibles avec Pandora FMS ?
Contactez-nous →Pourquoi choisir Pandora FMS pour la supervision GPU ?
Pandora FMS n’est pas un outil GPU isolé. C’est la plateforme où ces métriques prennent une réelle valeur opérationnelle.
Une seule console pour l’infrastructure et les GPU
Les métriques GPU s’intègrent dans la même console que celle où vous contrôlez serveurs, réseau, stockage, services et logs. Sans plateformes séparées.
On-premise, hybride et cloud
Supervisez les GPU dans vos propres datacenters, environnements hybrides et instances cloud avec GPU NVIDIA exposé à l’OS, sans dépendre d’un fournisseur spécifique.
Sans dashboards isolés
Les métriques GPU sont intégrées à l’exploitation existante : historique, événements, alertes, rapports et dashboards au sein de la même plateforme.
Alertes, historique et rapports
Chaque métrique GPU peut générer des alertes, être historisée et apparaître dans des rapports. Le même modèle opérationnel appliqué aux serveurs et au réseau peut également s’appliquer aux GPU.
RESSOURCES ASSOCIÉES
Approfondissez vos connaissances sur la supervision GPU

Supervision GPU : monitoring des GPU pour l’IA et les environnements hybrides
Quelles métriques contrôler, différence entre nvidia-smi et les plateformes de supervision, et comment intégrer la supervision GPU dans une stratégie d’AI infrastructure monitoring.
Lire l’article →
Supervision des serveurs et de l’infrastructure
Pandora FMS permet de superviser les serveurs physiques, virtuels et cloud sur une plateforme unique. Les GPU s’intègrent dans ce contexte global.
Voir la solution →
IA appliquée à la gestion IT et à la supervision intelligente
Détection d’anomalies, prédiction et automatisation dans votre infrastructure IT. La supervision GPU est une composante d’une stratégie plus large d’AI infrastructure monitoring.
Voir la solution →Questions fréquentes sur la supervision GPU
Concept
Qu’est-ce que la supervision GPU ?
La supervision GPU consiste à surveiller en continu l’état, l’utilisation, la mémoire, la température, la consommation et les erreurs des GPU dans des environnements professionnels. Elle s’applique aux infrastructures d’IA, de HPC, d’inférence et d’entraînement de modèles. Elle ne doit pas être confondue avec les outils de gaming, d’overclocking ou de tuning graphique.
Quels GPU le plugin Pandora FMS prend-il en charge ?
Le plugin prend en charge les GPU NVIDIA. Il utilise nvidia-smi comme source de données et nécessite que le pilote NVIDIA soit installé sur l’hôte. Il ne prend pas en charge AMD ni Intel dans la version actuelle.
Compatibilité
Fonctionne-t-il dans les environnements on-premise et cloud ?
Oui. Le plugin fonctionne comme agent local sur l’hôte avec le GPU. Linux est validé (amd64 / arm64). Windows est en validation finale. Il peut être utilisé sur des serveurs on-premise, des environnements hybrides et des instances cloud avec GPU exposé au système d’exploitation. Il ne nécessite pas d’accès distant ni de configuration réseau supplémentaire.
Quelles métriques supervise-t-il ?
Le plugin couvre l’utilisation et l’état du GPU, la mémoire utilisée et libre, la température, la consommation et la limite de puissance, les erreurs ECC lorsque disponibles, ainsi que des données techniques comme le modèle de GPU, la version du pilote et la version CUDA. La documentation technique du plugin sera disponible sur Marketplace.
Différences
Quelle est la différence entre nvidia-smi et Pandora FMS pour la supervision GPU ?
nvidia-smi est un utilitaire en ligne de commande utile pour des consultations ponctuelles. Pandora FMS utilise nvidia-smi comme source de données et intègre ces métriques dans une plateforme avec historique, alertes, dashboards, rapports et corrélation avec le reste de l’infrastructure.
Le plugin supervise-t-il les modèles d’IA ou les métriques MLOps ?
Non. Le plugin supervise l’infrastructure GPU : matériel, performance, mémoire, température et consommation. Il ne supervise pas les modèles d’IA, les prompts, la détection de drift ni les métriques MLOps.
Commencez à superviser vos GPU NVIDIA avec Pandora FMS
Intégrez la supervision des GPU NVIDIA dans votre exploitation IT et transformez des métriques isolées en alertes, historique, dashboards et rapports opérationnels.
