


















Secciones
- Qué es la monitorización de bases de datos
- Por qué es importante monitorizar bases de datos
- Database Performance Monitoring vs Database Activity Monitoring
- Métricas clave en la monitorización de bases de datos
- Monitorización según el tipo de base de datos
- Problemas habituales que detecta la monitorización
- Buenas prácticas para monitorizar bases de datos
- Qué debe tener una herramienta de monitorización de bases de datos
- Monitorización de bases de datos, observabilidad y CMDB
- Cómo ayuda Pandora FMS a monitorizar bases de datos
- Preguntas frecuentes
- Conclusión
Si la base de datos cae, se pone en marcha el dominó que nos arruina la semana, porque lo siguiente en desmoronarse son las aplicaciones, luego los clientes, los informes, las automatizaciones y, finalmente, la moral y cordura del equipo de guardia.
Por eso, esta guía recorre qué es la monitorización de bases de datos, qué métricas controlar, qué problemas detecta, qué buenas prácticas aplicar y cómo encaja en nuestra estrategia global de observabilidad.
Con ella, seremos dueños de un Palantir que nos permitirá saber todo y, más importante aún, actuar a tiempo antes de que las inevitables chispas se conviertan en incendio.
Qué es la monitorización de bases de datos
Comencemos con la inevitable teoría.
La monitorización de bases de datos consiste en supervisar de manera continua la disponibilidad, rendimiento, consultas, conexiones, almacenamiento, replicación, errores y capacidad de los motores que sostienen nuestros datos críticos. El objetivo es detectar problemas antes de que afecten al servicio.
O dicho de otro modo, ser El guardián entre el centeno y no esperar a que el usuario nos grite amablemente que la web va lenta. Antes de llegar a ese punto, una monitorización nos debe permitir detectar y corregir.
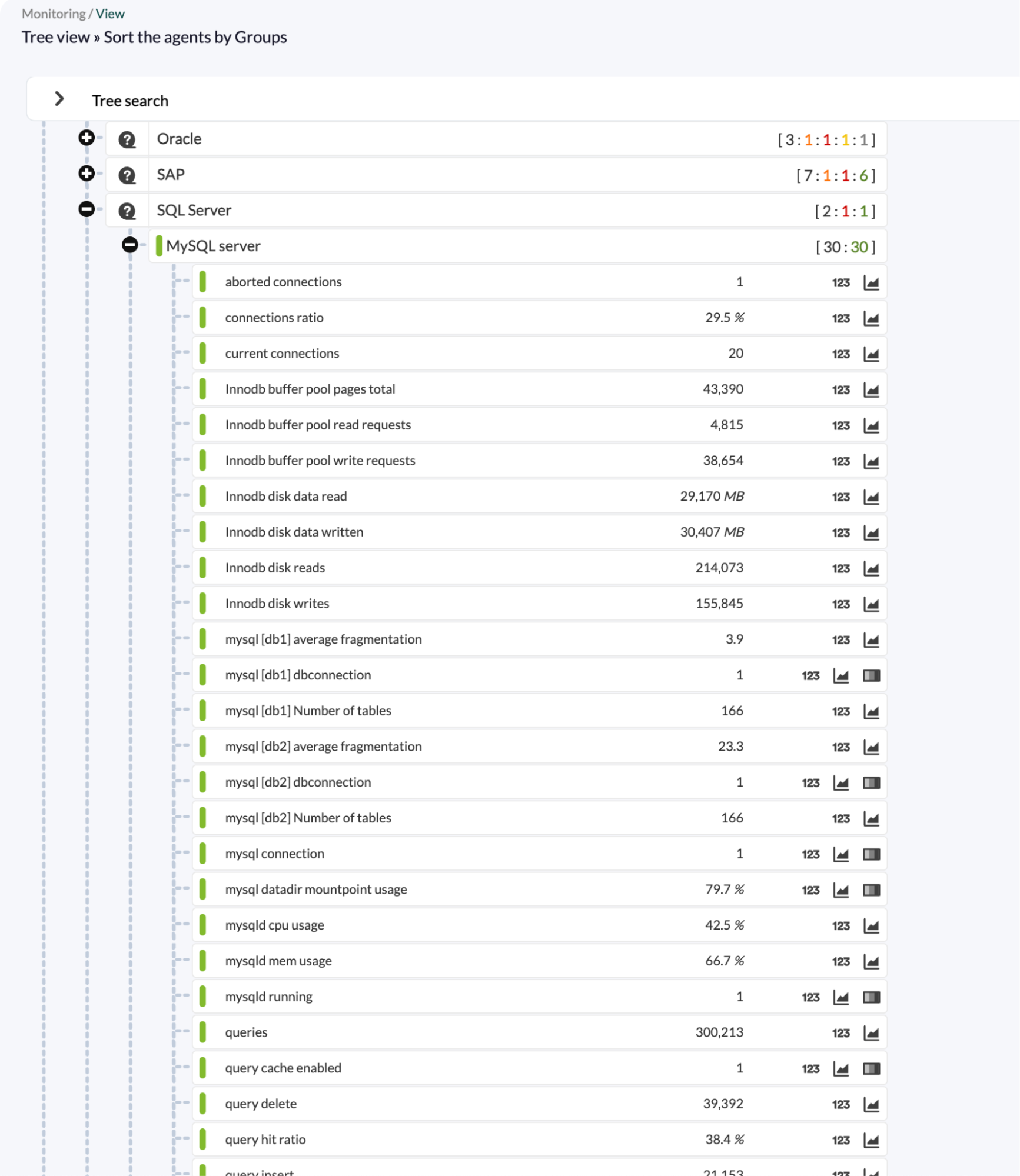
Visión general y consolidada de MySQL en Pandora FMS, que permite controlar visual y rápidamente el estado de las bases de datos
Por qué es importante monitorizar bases de datos
Las razones son tan obvias como ignoradas a menudo:
- Reducir caídas de servicio: al ver que se produce una saturación de conexiones antes de que esta colapse el servicio.
- Detectar cualquier degradación antes de que llegue al usuario: así, una consulta que pasa de 50 ms a 800 ms es un aviso sobre el que actuar antes de que se convierta en problema.
- Evitar saturación de almacenamiento: porque el espacio en disco se suele llenar despacio cuando nadie mira, en lugar de golpear de pronto.
- Optimizar consultas y recursos: identificando las queries que nos están gripando el motor de la BBDD.
- Anticipar problemas de capacidad: sabiendo cuánto nos queda antes de pelearnos con finanzas para conseguir más hardware o un scale-out.
- Reducir el MTTR: principalmente, consiguiendo que el equipo deje de apagar fuegos con una venda en los ojos.
- Entender dependencias entre base de datos, aplicación, servidor y red.
Ahora está de moda el concepto de «Caja Negra» en IT y, sin monitorización, la base de datos se convierte en una que solo da señales de vida cuando deja de darlas. Entonces, solo queda correr con un desfibrilador como en esas series de médicos donde todos se lían con todos.
Database Performance Monitoring vs Database Activity Monitoring
Cuando la monitorización de bases de datos sale a la palestra, estos dos enfoques la acompañan y conviene conocerlos y no mezclarlos:
- Database Performance Monitoring (DPM): es una monitorización orientada al rendimiento y las operaciones. Así, controla latencias, consultas lentas, throughput, conexiones, locks, uso de CPU, memoria, disco y red, replicación, almacenamiento y disponibilidad. Es decir, que es lo que se entiende habitualmente por «monitorizar la base de datos».
- Database Activity Monitoring (DAM): en este caso, la monitorización está orientada a actividad, seguridad y auditoría. De este modo, observa accesos a datos, usuarios y sesiones, consultas sensibles, cambios no autorizados, comportamiento anómalo y cumplimiento normativo.
Sabiendo esto, esta guía se centra en el primer enfoque DPM de rendimiento, disponibilidad y operación, aunque conviene saber que la monitorización de actividad también forma parte de una estrategia completa cuando hay requisitos regulatorios o de auditoría.
Métricas clave en la monitorización de bases de datos
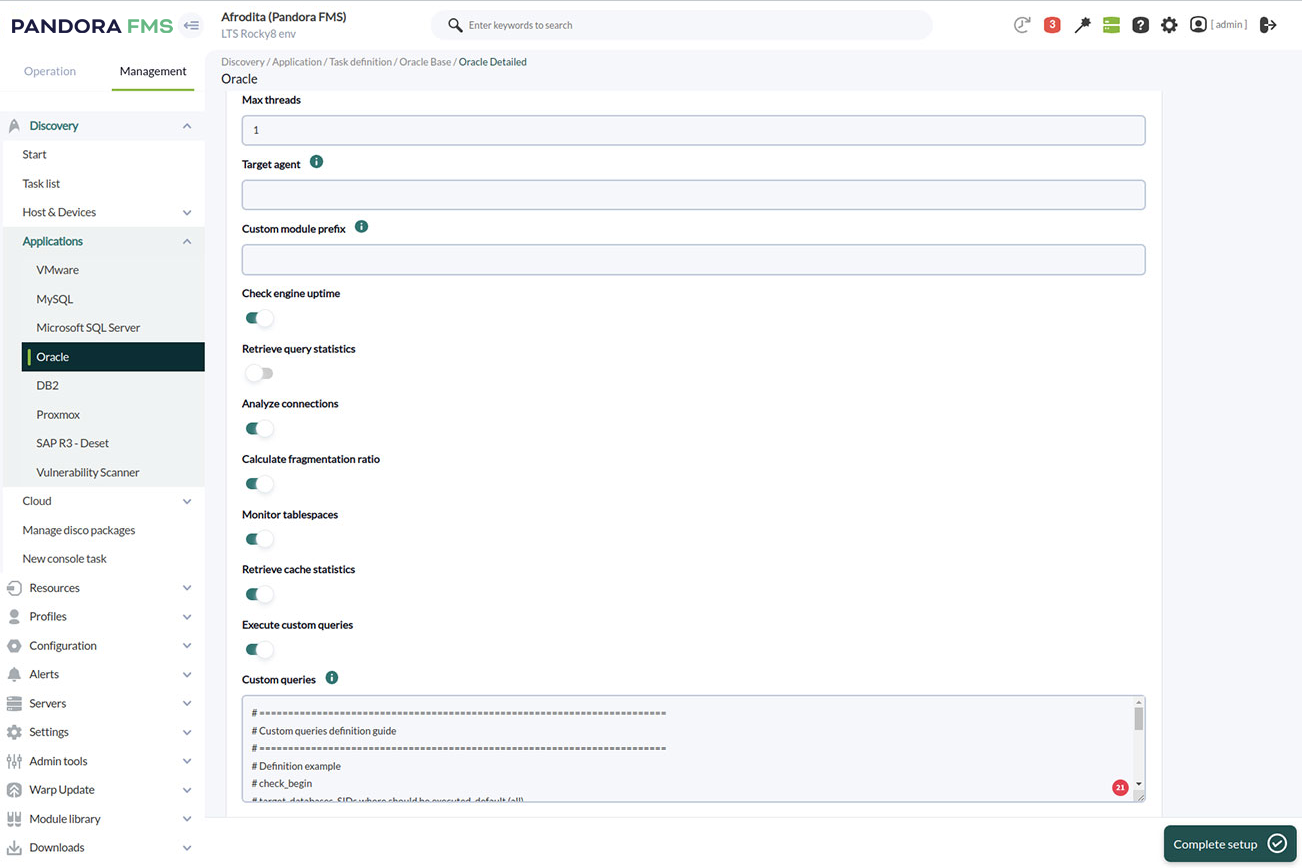
Selección de métricas en Pandora FMS para monitorizar una base de datos Oracle
En la práctica, una monitorización proporciona métricas, pero claro, en la vida siempre ha habido clases y no todas deben pesar lo mismo en nuestras decisiones.
Eso y que un dashboard lleno de gráficas que nadie mira solamente es ruido caro.
Por eso, este es el grano que debemos separar de la paja y tener siempre vigilado.
Disponibilidad y estado del servicio
Lo primero a controlar es que las BBDD funcionen, obviamente. Eso implica indicadores clave como:
- Uptime o disponibilidad del motor.
- Respuesta a chequeos de salud.
- Errores de conexión.
- Estado de nodos o instancias en clúster.
Rendimiento
Además de que funcionen, nos pagan para que lo hagan eficazmente y no arrastren los pies en las consultas. Esto implica el control de métricas como:
- Latencia de dichas consultas.
- Tiempo de respuesta medio y percentil 95/99.
- Consultas lentas (slow queries).
- Throughput en consultas por segundo.
- Locks, deadlocks y waits.
Uso de recursos
Eficacia y eficiencia no son lo mismo y queremos las dos cosas, de modo que funcionar rápidamente no implique que los procesadores se calienten más que el Sol o desperdiciar una memoria RAM que ya vale más que mis riñones.
Para eso controlamos:
- CPU consumida por el motor.
- Memoria usada y libre (buffer pool y caché).
- Disco (espacio libre, IOPS, latencia…).
- Red (tráfico y errores).
Conexiones y sesiones
Aquí nos interesa el quién, cómo y cuánto del uso, lo que implica conocer:
- Conexiones activas y máximas configuradas.
- Saturación del pool de conexiones.
- Sesiones bloqueadas o en espera.
Almacenamiento y crecimiento
Las bases de datos tienden a lo mismo que yo, engordar misteriosamente, sobre todo, cuando nadie mira lo que hago.
Para evitar que nuestras BBDD lo ocupen todo como los tribbles de Star Trek, debemos vigilar:
- Tamaño de bases de datos y tablas.
- Crecimiento por unidad de tiempo.
- Espacio libre en tablespaces o volúmenes.
- Estado de índices (uso, fragmentación).
- Volumen de logs (transaccionales y de aplicación).
Replicación, clustering y alta disponibilidad
Estos indicadores son esenciales en la monitorización de una gestión moderna de BBDD:
- Lag de replicación para evitar que los usuarios accedan a datos desactualizados.
- Estado de réplicas y si están en línea, retrasadas o caídas.
- Failover y conmutaciones para los casos de fallos, emergencias o mantenimientos.
- Sincronización de nodos para verificar la coherencia de los datos entre ellos y asegurar que el quorum esté activo para mantener la integridad del sistema.
Backups y recuperación
No importa que seamos los mejores y más rápidos, el desastre nos alcanzará eventualmente, así que también tenemos que ser humildes y trabajar con red (de seguridad, no de Internet, aunque esa también).
Para ello, debemos controlar:
- El estado del último backup.
- Antigüedad de la última copia correcta, lo que de verdad alimenta nuestro Objetivo de Punto de Recuperación (RPO por sus siglas en inglés).
- Errores en procesos de copia.
- Duración de la última restauración de prueba. Esta es la forma honesta de validar el RTO (Objetivo de Tiempo de Recuperación), porque un backup que no se restaura es una falsa ilusión de seguridad.
Monitorización según el tipo de base de datos
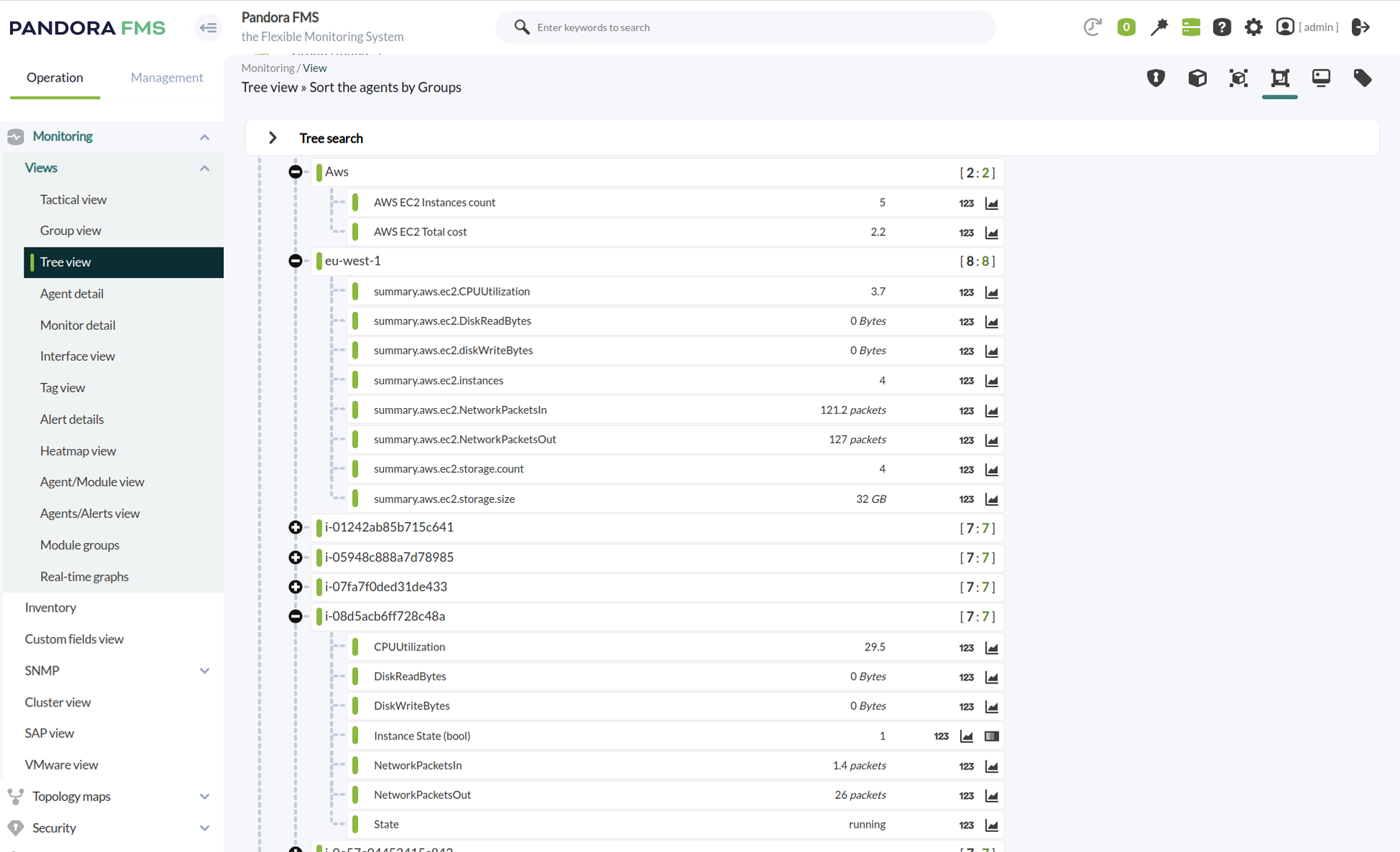
Pandora FMS monitorizando un clásico intemporal corporativo, una base de datos IBM DB2
Igual que las métricas no son iguales entre sí, las bases de datos tampoco. Así, cada modelo de dichos datos pide su propio enfoque de monitorización.
Si bien aquí no puedo entrar a fondo en la explicación de cada uno (a ver, poder puedo, pero convertiría esto en La historia interminable), tienes una guía completa de los tipos de bases de datos. Allí cubrimos la taxonomía y aquí nos centramos en qué vigilar en cada caso.
Como veremos, habrá cosas comunes a todas las BBDD (como la disponibilidad o latencia, por ejemplo) y otras más concretas del tipo de base de datos, como el traversal o tiempo de recorrido si hablamos de bases de datos de grafos.
Bases de datos relacionales
Aquí incluimos MySQL, PostgreSQL, Oracle, SQL Server o MariaDB y es raro que en nuestra infraestructura IT no tengamos una (o varias más bien) de estas.
Aquí hay que enfatizar:
- Consultas lentas.
- Locks.
- Conexiones.
- Índices.
- Replicación.
- Almacenamiento.
- Transacciones.
Por supuesto, el primer paso para arrancar son sus documentaciones oficiales: PostgreSQL, MySQL, SQL Server y Oracle.
Bases de datos NoSQL documentales
En este caso suenan nombres como MongoDB, Couchbase o RavenDB. Aquí es prioritario controlar:
- Operaciones por segundo.
- Uso de memoria.
- Replicación.
- Índices.
- Tiempos de consulta.
- Errores.
- Crecimiento de colecciones.
Para ello, MongoDB tiene documentación específica y en esta guía sobre cómo monitorizar RavenDB entramos al detalle para echarte una mano.
Por otra parte, si quieres una visión más amplia del lado no relacional de las BBDD, esta guía de bases de datos NoSQL traza un buen dibujo del panorama.
Bases de datos clave-valor y caché
Redis o Riak salen a jugar al campo en este caso y debemos vigilar bien:
- Memoria consumida.
- Expiración de claves por TTL (expired keys).
- Expulsiones por presión de memoria (las llamadas evictions que, ojo, no son lo mismo que las expiraciones).
- Fallos y aciertos del cache.
- Persistencia.
- Conexiones.
- Latencia.
Si la usamos, la documentación de Redis sobre benchmarks y optimización es referencia obligada.
Bases de datos orientadas a columnas
Cassandra o HBase son nombres habituales en este territorio y debemos tener bien claro:
- Estado del clúster.
- El proceso de compaction o compactación (la «limpieza y organización» que realizan estas bases de datos debido a su modo de funcionamiento).
- Latencia de lectura y escritura.
- Distribución y tamaño de particiones.
- Replicación.
Aquí, al menos, Cassandra documenta sus métricas con detalle.
Bases de datos de grafos
Aquí encontramos candidatos como Neo4j en los que hay que controlar bien:
- Tiempos de traversal (el recorrido a través del grafo, para ver si es eficiente).
- Memoria usada en consultas complejas.
- Tamaño del grafo en número de nodos y relaciones almacenadas.
- Latencia de las consultas.
- Disponibilidad.
Bases de datos de series temporales
InfluxDB, TimescaleDB, Prometheus u OpenTSDB son los nombres que escucharemos en este caso y lo que debemos controlar aquí pasa por:
- Ingesta por segundo (puntos de datos recibidos por unidad de tiempo) para localizar cuellos de botella.
- Cardinalidad de series, o el número de combinaciones únicas de etiquetas (la métrica que más disgustos da cuando se dispara, porque puede agotar la RAM y/o bloquear la base de datos).
- Retención efectiva. Esencial para el control de costes y que el espacio ocupado no se dispare.
- Uso de disco y ratio de compresión (si es bajo, el almacenamiento no es eficiente).
- Latencia de consultas.
Problemas habituales que detecta la monitorización
Pandora FMS ofreciendo una visión general del estado de una BBDD de acuerdo a las métricas definidas.
En las series de médicos que comentaba antes se esfuerzan por encontrar enfermedades cada vez más raras, por aquello del drama, la novedad y el desafío. Sin embargo, la realidad en monitorización de bases de datos suele ser bastante más prosaica y, por experiencia de muchos años, casi siempre aparecen los mismos cuadros clínicos.
Estos sospechosos habituales son:
- Consultas leeeeeentas que se acumulan.
- Saturación de conexiones intentando entrar todas a la vez por la puerta como en las películas de los hermanos Marx.
- Crecimiento anómalo de almacenamiento.
- Falta de espacio en disco por lo anterior.
- Degradación del rendimiento por índices mal mantenidos.
- Errores de replicación o lag creciente en ese proceso clave para que todos trabajemos con los mismos datos.
- Backups fallidos sin que nadie se entere hasta el momento del infarto cuando los necesites.
- Caídas intermitentes y el efecto flapping como esas bombillas inestables e irritantes que no dejan de parpadear.
- Consumo anómalo de CPU o memoria.
- Nodos desincronizados en el clúster.
- Degradación causada por la red o la infraestructura subyacente.
Una buena monitorización convierte las caídas de varias horas por cualquiera de estos problemas en un ajuste preventivo de unos minutos.
Buenas prácticas para monitorizar bases de datos
En Juego de Tronos, Joffrey Baratheon, ese pequeño miserable, empuña la espada Lamento de viuda, una majestuosa obra de arte de acero valyrio… Totalmente inútil en manos de un inepto cobarde. Lo mismo pasa con la monitorización. Esta es una herramienta y eso la hace tan buena como las decisiones y habilidad de quien hay detrás.
Por eso, aunque implantemos aplicaciones de monitorización de punta de lanza como Pandora FMS, la realidad es que las buenas prácticas son el cimiento de la casa que estamos construyendo.
Y las mejores entre ellas son:
- Definir umbrales según criticidad y comportamiento real, no copiando los valores por defecto o los que hayamos visto en el último «contenido viral» de LinkedIn.
- Separar alertas informativas, de advertencia y críticas, para no abrumar las delicadas mentes de los técnicos llenas de anime con avisos triviales.
- Evitar la fatiga de alertas: porque estas son muy tentadoras y en IT tendemos a ser unos freaks del control, pero si todo es urgente, nada lo es.
- Correlacionar métricas de base de datos con servidor, aplicación y red porque nada es una isla y menos en IT.
- Monitorizar tendencias y no solo estados puntuales, porque el crecimiento lento, por ejemplo, es un aviso.
- Revisar capacidad y crecimiento periódicamente y no solo cuando duele. En esto solemos ser como con el dentista, y el dolor por desatender revisiones y limpieza suele ser similar.
- Documentar dependencias entre bases de datos, servicios y aplicaciones. Debemos conocer cada rincón como una araña conoce su tela, incluyendo esas relaciones.
- Validar backups y restauración, en lugar de asumir que funcionan solamente porque el job terminó en verde en la consola.
- Revisar permisos y actividad si hay requisitos de auditoría.
- Ajustar alertas por entorno. Porque en muchas ocasiones, lo que en desarrollo puede ser ruido, en producción puede ser crítico.
Qué debe tener una herramienta de monitorización de bases de datos

Pandora FMS, herramienta de monitorización de última generación
Uno podría imaginar lo que viene ahora, una especie de folleto de marketing cantando las alabanzas de nuestra herramienta, Pandora FMS. Sin embargo, en Pandora creemos en que compruebes tú si lo deseas, no en que nadie tenga que realizar actos de fe.
Además, cuando vayamos a elegir herramienta, no debemos dejarnos llevar por marcas, fama o palabras de vendedores, sino por prestaciones que encajen en el hueco de nuestras necesidades.
Así, lo que deberíamos mirar, valorando el peso que tienen en nuestra operativa concreta, debería ser:
- Soporte para múltiples motores, como relacionales, NoSQL, time-series…
- Obtener una cobertura de monitorización SQL y NoSQL sin tener que saltar de herramienta y fragmentar aún más nuestra atención y tiempo de respuesta.
- Que tenga métricas de rendimiento accesibles y configurables.
- Alertas con umbrales personalizables y canales múltiples.
- Dashboards adaptables a cada audiencia, ya sea técnica o ejecutiva.
- Histórico de métricas con retención útil y no solo de última hora.
- Correlación con nuestra infraestructura concreta (servidores, red, cloud…) para no estar intentando meter la figura cuadrada en el hueco circular.
- Informes para clientes, auditorías y SLA.
- Integración con entornos cloud como AWS, GCP o Azure, algo indispensable hoy.
- Capacidad de detectar tendencias y desviaciones.
- Facilidad operativa para equipos IT y MSP.
Monitorización de bases de datos, observabilidad y CMDB
Las bases de datos son las que hacen funcionar los servicios de nuestra organización, su cerebro y memoria. Por eso, la monitorización gana valor cuando se entiende cuáles de dichos servicios dependen de cada base de datos.
Esa cartografía es el trabajo de la CMDB para mapear activos y dependencias y permite saber, al ver una alerta, qué procesos de negocio quedan en riesgo.
Es la diferencia entre: «Se ha degradado la BD-23», cosa que no suena especialmente a infarto y: «El motor de facturación de Francia se degradará en quince minutos como no actuemos».
Eso ya abre bien los ojos del responsable que dormita la siesta.
Por encima, la observabilidad cierra el círculo conectando métricas con logs, eventos y experiencia de usuario para no mirar solamente, sino comprender.
Resumido en su esencia, monitorización responde a: «¿Está sano?», mientras que observabilidad responde a: «¿Por qué se está comportando así?».
Las dos preguntas son distintas e incompletas la una sin la otra.
Cómo ayuda Pandora FMS a monitorizar bases de datos
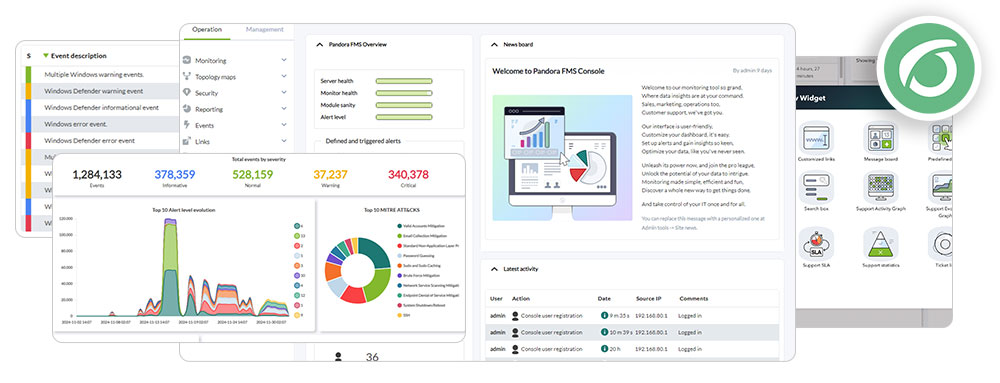
Pandora FMS monitorizando cada rincón e informando de todo como los cuervos de Odín
Ahora sí, toca «hablar de nuestro libro» porque, modestia aparte, Pandora FMS ofrece monitorización avanzada de bases de datos con ese enfoque unificado imprescindible para no volvernos locos.
Eso permite una visión global de la infraestructura y cómo encajan todas sus piezas, porque las BBDD no viven solas, son el cerebro de procesos fundamentales y que de pronto suene el pitido de un encefalograma plano tiene consecuencias en cada rincón de nuestro mundo tecnológico.
Así, Pandora FMS proporciona una monitorización puntera de base de datos gracias a:
- Módulos y plugins para los motores más extendidos (MySQL, PostgreSQL, Oracle, SQL Server, MongoDB…).
- Alertas configurables por umbral, ventana temporal y criticidad, con escalado y canales múltiples.
- Dashboards adaptados a cada audiencia: técnico, jefe de área, dirección.
- Histórico de métricas con retención suficiente para análisis de tendencias y capacity planning.
- Correlación nativa con servidores, aplicaciones, red, cloud y otros componentes de la infraestructura, no como silos aislados.
- Visión centralizada desde la misma consola que se usa para monitorizar el resto de IT (nuestra metaconsola), lo que reduce el coste cognitivo y saltos entre herramientas para los equipos.
- Utilidad probada en equipos IT, NOC, DevOps y MSPs, especialmente cuando hay que separar datos por cliente o entorno.
Pandora FMS monitoriza, pero no se queda ahí, también alerta, correlaciona y ayuda a diagnosticar, convirtiéndose en el ojo del Gran Hermano que todo lo ve.
Preguntas frecuentes
A fin de remachar lo importante, destilemos las dudas más habituales junto a sus respuestas.
¿Qué es la monitorización de bases de datos?
La supervisión continua de disponibilidad, rendimiento, consultas, conexiones, almacenamiento, replicación, errores y capacidad de los motores de bases de datos.
¿El objetivo? Detectar problemas antes de que afecten al servicio.
¿Qué métricas debe monitorizar una base de datos?
Esta es una labor que cada organización debe realizar según su funcionamiento y prioridades, pero como mínimo: disponibilidad, latencia de consultas, throughput, conexiones activas vs máximas, uso de CPU/memoria/disco, locks y deadlocks, espacio libre, lag de replicación, estado de backups y errores.
Casi nada, y más teniendo en cuenta que luego cada tipo de motor añade las suyas, como hemos visto más arriba.
¿Cuál es la diferencia entre database monitoring y database activity monitoring?
El primero (DPM) se centra en rendimiento, disponibilidad y operación. El segundo (DAM) se centra en accesos, usuarios, consultas sensibles, cambios no autorizados y cumplimiento.
Son complementarios, no excluyentes.
¿Qué es database performance monitoring?
Es la disciplina centrada en medir y mejorar el rendimiento de una base de datos.
Eso implica observación de latencia, velocidad de consultas, locks, uso de recursos, replicación, almacenamiento y disponibilidad.
¿Qué herramientas se usan para monitorizar bases de datos?
Por un lado, podemos optar por plataformas generalistas como Pandora FMS, lo que nos aportará una integración completa y una perspectiva amplia de monitorización global.
Por otro, podemos elegir herramientas específicas del motor (pg_stat_statements, Performance Schema, Oracle Enterprise Manager…), soluciones APM y stacks de observabilidad.
Al final, lo importante no es la marca, sino la cobertura y la correlación con el resto de nuestra infraestructura.
¿Cómo detectar consultas lentas?
Activando slow query log en el motor, instrumentando trazas o usando vistas de rendimiento (pg_stat_statements, Performance Schema, DMVs).
Una buena herramienta de monitorización las extrae, las agrega y las pone en gráficas comparables en el tiempo.
¿Por qué es importante monitorizar la replicación?
Porque una réplica retrasada o caída hace vulnerable la alta disponibilidad. Igualmente, una promoción a primario con datos no sincronizados por problemas en la replicación puede provocar pérdida de información.
¿Cómo ayuda la monitorización a reducir el MTTR?
Detectando problemas antes y aportando contexto que acelere el diagnóstico. Así, reducir el MTTR deja de ser un brindis al sol y se convierte en consecuencia natural de operar con visibilidad.
Conclusión
Como ocurre en otros aspectos de la disciplina, la monitorización de base de datos es mucho más que comprobar si el servicio responde.
También debe medir rendimiento, capacidad, replicación, errores, backups, actividad relevante y dependencias con aplicaciones e infraestructura.
En entornos críticos, una estrategia de monitorización adecuada permite anticipar incidencias, reducir tiempos de resolución y operar con control real.
Como en el puente de mando del Enterprise, no se trata de mirar una pantalla, sino de disponer de conocimiento sobre cada aspecto clave, alguien que lo comprenda y la disciplina operativa para actuar antes de que la nave empiece a experimentar sacudidas.
Habla con el equipo de ventas, pide presupuesto,
o resuelve tus dudas sobre nuestras licencias
