


















GPU monitoring para infraestructuras de IA, HPC y entornos híbridos
Monitoriza GPUs NVIDIA con Pandora FMS e integra datos de utilización, memoria, temperatura, consumo y estado dentro de la misma plataforma donde ya supervisas servidores, red, almacenamiento, servicios y logs.
Clientes que confian en nosotros

GPU MONITORING SOFTWARE
Tus GPUs no pueden ser un punto ciego en tu infraestructura IT
Las infraestructuras de IA, HPC, inferencia y entrenamiento dependen de GPUs que concentran coste, rendimiento y riesgo operativo. Una GPU saturada, sobrecalentada, infrautilizada o con errores no detectados puede degradar servicios, ralentizar procesos críticos o provocar fallos en producción.
Pandora FMS integra las métricas GPU dentro de la operación IT existente, junto a servidores, red, almacenamiento, servicios y logs. Sin plataformas separadas.
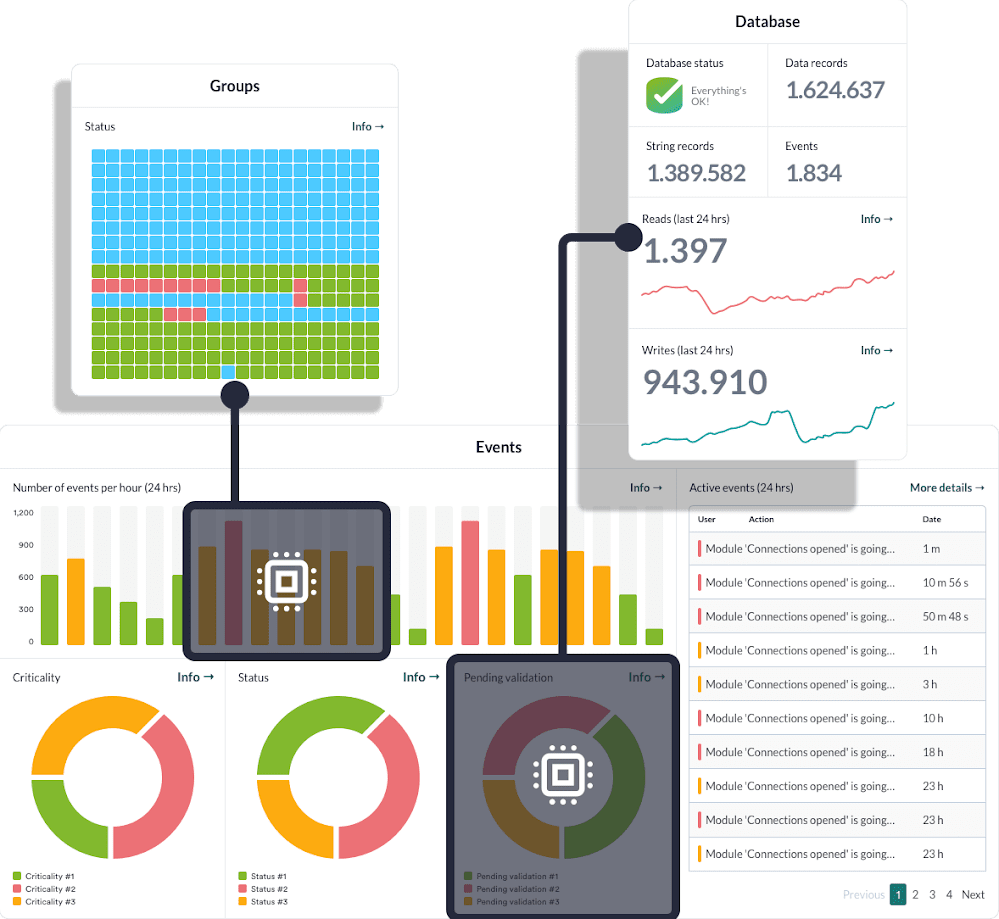
Pandora FMS Console · Estado GPU
FUNCIONAMIENTO
Cómo funciona el GPU monitoring en Pandora FMS
El plugin actúa como agente local en el host con GPU NVIDIA, utiliza nvidia-smi como fuente de datos y emite módulos que Pandora FMS incorpora a su operación.
Host con GPU NVIDIA
On-premise, híbrido o cloud
nvidia-smi
Fuente de datos local
Plugin local Pandora FMS
Agente que emite módulos XML
Dashboards, alertas e informes
Integradas con el resto de la infraestructura
CASOS DE USO
De la métrica al incidente: GPU monitoring en operación real
No basta con saber que una GPU está al 95 %. Lo que importa es el contexto operativo.
Saturación sostenida
Una GPU al 95 % durante horas, con memoria alta y errores en el servicio de inferencia, no es un pico normal. Es un incidente que requiere intervención. El histórico permite distinguir uno del otro.
Riesgo térmico
Temperatura alta sostenida combinada con anomalías de ventilación puede anticipar degradación física. Detectarlo antes del fallo permite intervención preventiva en lugar de reacción a un corte.
Infrautilización
Una GPU cara con uso bajo durante semanas puede indicar mala asignación de workloads. El histórico aporta los datos objetivos para justificar o postergar decisiones de hardware.
Capacity planning
El histórico de utilización y memoria permite identificar crecimiento de demanda, prever saturación y planificar ampliaciones con datos en lugar de estimaciones.
MÉTRICAS MONITORIZADAS
Qué puedes monitorizar con Pandora FMS
Pandora FMS recoge métricas clave de GPUs NVIDIA para detectar saturación, presión de memoria, riesgo térmico, errores y problemas de capacidad.
- Utilización de GPU (%)
- Estado operativo de la GPU
- Memoria usada, libre y total (MiB)
- Porcentaje de uso de memoria
- Temperatura (°C)
- Consumo instantáneo y límite de potencia (W)
- Velocidad de ventilación cuando aplica
- Errores ECC cuando aplican
- Modelo de GPU y versión de driver
- Versión CUDA soportada
nvidia-smi. La documentación técnica del plugin estará disponible en Marketplace.ALERTAS
Alertas para detectar saturación, temperatura y errores críticos
Pandora FMS permite generar alertas sobre métricas GPU para detectar presión de memoria, temperaturas elevadas, errores ECC o pérdida de disponibilidad. Los umbrales pueden ajustarse desde la consola según el modelo de GPU y la política de operación.
Los umbrales predefinidos sirven como referencia y pueden modificarse desde la consola de Pandora FMS.
COMPATIBILIDAD
Compatibilidad y requisitos
El plugin está diseñado para entornos on-premise, híbridos y cloud con GPUs NVIDIA expuestas al sistema operativo.
- GPUs NVIDIA
- Linux (amd64 / arm64) — validado
- Windows (amd64) — en validación final
- Entornos on-premise e híbridos
- AWS, Azure y Google Cloud si la GPU está expuesta al SO
- Requiere driver NVIDIA instalado y
nvidia-smidisponible en el host.
Limitaciones actuales
- No soporta GPUs AMD ni Intel
- No monitoriza modelos de IA, prompts ni métricas MLOps
- No incluye detección de drift ni AI observability completa
- Para clusters con muchas GPUs por nodo puede ser necesario complementar con DCGM u otras soluciones de agregación
¿Quieres validar si tus GPUs NVIDIA son compatibles con Pandora FMS?
Contáctanos →¿Por qué Pandora FMS para GPU monitoring?
Pandora FMS no es una herramienta aislada de GPU. Es la plataforma donde esas métricas cobran valor operativo real.
Una sola consola para infraestructura y GPU
Las métricas GPU se integran en la misma consola donde controlas servidores, red, almacenamiento, servicios y logs. Sin plataformas separadas.
On-premise, híbrido y cloud
Monitoriza GPUs en datacenters propios, entornos híbridos e instancias cloud con GPU NVIDIA expuesta al SO, sin depender de un proveedor concreto.
Sin dashboards aislados
Las métricas GPU se incorporan a la operación existente: histórico, eventos, alertas, informes y dashboards dentro de la misma plataforma.
Alertas, histórico e informes
Cada métrica GPU puede generar alertas, historificarse y aparecer en informes. El mismo modelo operativo de servidores y red puede aplicarse también a GPUs.
RECURSOS RELACIONADOS
Amplía tu conocimiento sobre GPU monitoring

GPU monitoring: monitorización de GPUs para IA y entornos híbridos
Qué métricas controlar, diferencia entre nvidia-smi y plataformas de monitorización, y cómo integrar GPU monitoring en una estrategia de AI infrastructure monitoring.
Leer el artículo →
Monitorización de servidores e infraestructura
Pandora FMS permite supervisar servidores físicos, virtuales y cloud en una única plataforma. Las GPUs se integran dentro de este contexto global.
Ver solución →
IA aplicada a gestión IT y monitorización inteligente
Detección de anomalías, predicción y automatización en tu infraestructura IT. El GPU monitoring es una pieza de una estrategia más amplia de AI infrastructure monitoring.
Ver solución →Preguntas frecuentes sobre GPU monitoring
Concepto
¿Qué es GPU monitoring?
GPU monitoring es la supervisión continua del estado, utilización, memoria, temperatura, consumo y errores de las GPUs en entornos profesionales. Se aplica a infraestructuras de IA, HPC, inferencia y entrenamiento de modelos. No debe confundirse con herramientas de gaming, overclocking o tuning gráfico.
¿Qué GPUs soporta el plugin de Pandora FMS?
El plugin soporta GPUs NVIDIA. Utiliza nvidia-smi como fuente de datos y requiere que el driver NVIDIA esté instalado en el host. No soporta AMD ni Intel en la versión actual.
Compatibilidad
¿Funciona en entornos on-premise y cloud?
Sí. El plugin funciona como agente local en el host con la GPU. Linux está validado (amd64 / arm64). Windows está en validación final. Puede usarse en servidores on-premise, entornos híbridos e instancias cloud con GPU expuesta al sistema operativo. No requiere acceso remoto ni configuración adicional de red.
¿Qué métricas monitoriza?
El plugin cubre utilización y estado de GPU, memoria usada y libre, temperatura, consumo y límite de potencia, errores ECC cuando aplican, y datos técnicos como modelo de GPU, versión de driver y versión CUDA. La documentación técnica del plugin estará disponible en Marketplace.
Diferencias
¿Qué diferencia hay entre nvidia-smi y Pandora FMS para GPU monitoring?
nvidia-smi es una utilidad de línea de comandos útil para consultas puntuales. Pandora FMS usa nvidia-smi como fuente de datos e integra esas métricas en una plataforma con histórico, alertas, dashboards, informes y correlación con el resto de la infraestructura.
¿El plugin monitoriza modelos de IA o métricas MLOps?
No. El plugin monitoriza la infraestructura GPU: hardware, rendimiento, memoria, temperatura y consumo. No monitoriza modelos de IA, prompts, detección de drift ni métricas de MLOps.
Empieza a monitorizar tus GPUs NVIDIA con Pandora FMS
Integra la monitorización de GPUs NVIDIA dentro de tu operación IT y convierte métricas aisladas en alertas, histórico, dashboards e informes operativos.
