


















GPU monitoring для инфраструктур ИИ, HPC и гибридных сред
Мониторьте GPU NVIDIA с Pandora FMS и интегрируйте данные об использовании, памяти, температуре, энергопотреблении и состоянии в ту же платформу, где уже контролируются серверы, сеть, хранилища, сервисы и логи.
Клиенты, которые нам доверяют

ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ДЛЯ GPU MONITORING
Ваши GPU не должны быть слепой зоной в ИТ-инфраструктуре
Инфраструктуры ИИ, HPC, инференса и обучения зависят от GPU, в которых сосредоточены стоимость, производительность и операционные риски. Перегруженная, перегретая, недоиспользованная GPU или GPU с необнаруженными ошибками может ухудшить работу сервисов, замедлить критические процессы или вызвать сбои в production.
Pandora FMS интегрирует GPU-метрики в существующую ИТ-эксплуатацию вместе с серверами, сетью, хранилищами, сервисами и логами. Без отдельных платформ.
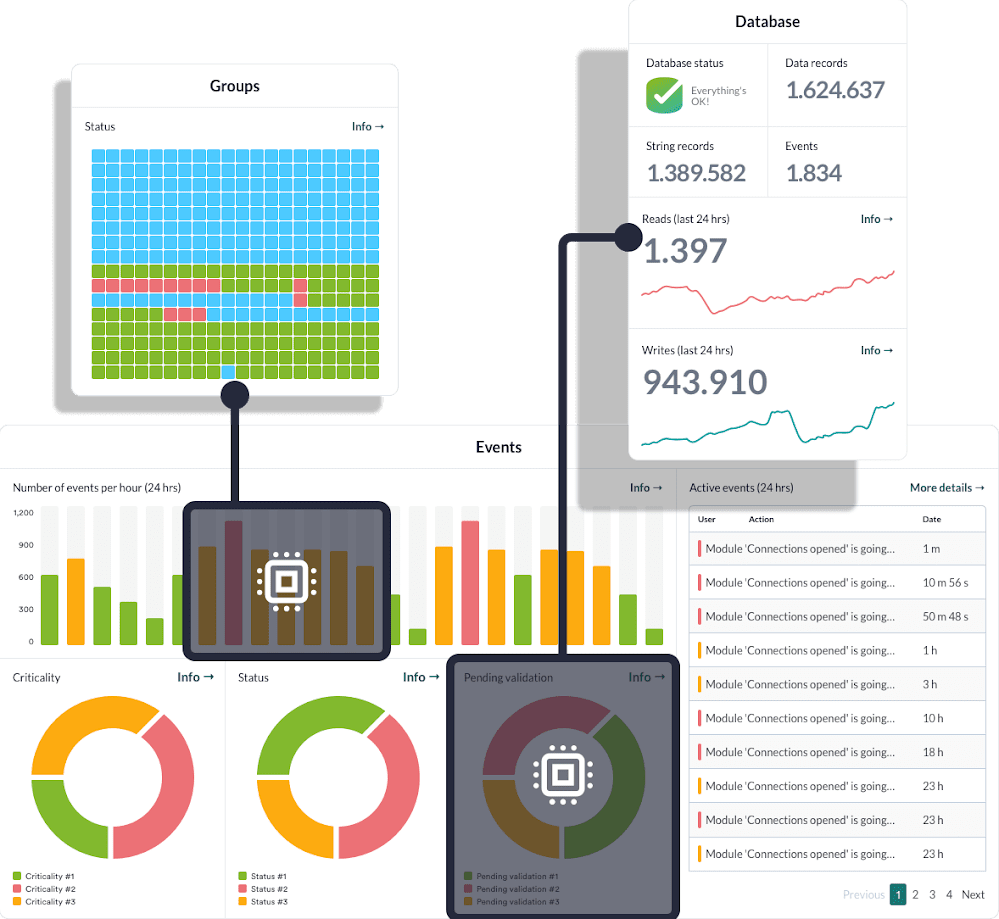
Консоль Pandora FMS · Состояние GPU
ПРИНЦИП РАБОТЫ
Как работает GPU monitoring в Pandora FMS
Плагин работает как локальный агент на хосте с GPU NVIDIA, использует nvidia-smi как источник данных и создаёт модули, которые Pandora FMS включает в свою операционную модель.
Хост с GPU NVIDIA
On-premise, гибридная среда или cloud
nvidia-smi
Локальный источник данных
Локальный плагин Pandora FMS
Агент, который создаёт XML-модули
Дашборды, оповещения и отчёты
Интегрированы с остальной инфраструктурой
СЦЕНАРИИ ИСПОЛЬЗОВАНИЯ
От метрики к инциденту: GPU monitoring в реальной эксплуатации
Недостаточно знать, что GPU загружена на 95 %. Важен операционный контекст.
Устойчивая перегрузка
GPU с загрузкой 95 % в течение нескольких часов, высоким потреблением памяти и ошибками в сервисе инференса — это не обычный пик. Это инцидент, требующий вмешательства. История помогает отличить одно от другого.
Тепловой риск
Стабильно высокая температура в сочетании с аномалиями вентиляции может заранее указывать на физическую деградацию. Раннее обнаружение позволяет выполнить профилактическое вмешательство вместо реакции на простой.
Недоиспользование
Дорогая GPU с низкой загрузкой на протяжении недель может указывать на некорректное распределение workloads. История предоставляет объективные данные для обоснования или отсрочки решений по оборудованию.
Capacity planning
История использования и памяти помогает выявлять рост спроса, прогнозировать насыщение ресурсов и планировать расширение на основе данных, а не оценок.
МОНИТОРИРУЕМЫЕ МЕТРИКИ
Что можно мониторить с Pandora FMS
Pandora FMS собирает ключевые метрики GPU NVIDIA для обнаружения перегрузки, давления на память, теплового риска, ошибок и проблем ёмкости.
- Использование GPU (%)
- Операционное состояние GPU
- Используемая, свободная и общая память (MiB)
- Процент использования памяти
- Температура (°C)
- Текущее энергопотребление и лимит мощности (W)
- Скорость вентилятора, если применимо
- Ошибки ECC, если применимо
- Модель GPU и версия драйвера
- Поддерживаемая версия CUDA
nvidia-smi. Техническая документация плагина будет доступна в Marketplace.ОПОВЕЩЕНИЯ
Оповещения для обнаружения перегрузки, температуры и критических ошибок
Pandora FMS позволяет создавать оповещения по GPU-метрикам для выявления давления на память, повышенных температур, ошибок ECC или потери доступности. Пороговые значения можно настраивать из консоли с учётом модели GPU и операционной политики.
Предустановленные пороги служат ориентиром и могут изменяться из консоли Pandora FMS.
СОВМЕСТИМОСТЬ
Совместимость и требования
Плагин разработан для on-premise, гибридных и cloud-сред с GPU NVIDIA, доступными операционной системе.
- GPU NVIDIA
- Linux (amd64 / arm64) — проверено
- Windows (amd64) — на финальной проверке
- On-premise и гибридные среды
- AWS, Azure и Google Cloud, если GPU доступна ОС
- Требуется установленный драйвер NVIDIA и доступный
nvidia-smiна хосте.
Текущие ограничения
- Не поддерживает GPU AMD или Intel
- Не мониторит модели ИИ, prompts или MLOps-метрики
- Не включает detection drift и полноценную AI observability
- Для кластеров с большим количеством GPU на узел может потребоваться дополнение DCGM или другими решениями агрегации
Хотите проверить, совместимы ли ваши GPU NVIDIA с Pandora FMS?
Связаться с нами →Почему Pandora FMS для GPU monitoring?
Pandora FMS — это не изолированный инструмент для GPU. Это платформа, где такие метрики получают реальную операционную ценность.
Единая консоль для инфраструктуры и GPU
GPU-метрики интегрируются в ту же консоль, где контролируются серверы, сеть, хранилища, сервисы и логи. Без отдельных платформ.
On-premise, гибридные и cloud-среды
Мониторьте GPU в собственных дата-центрах, гибридных средах и cloud-инстансах с GPU NVIDIA, доступной ОС, без зависимости от конкретного провайдера.
Без изолированных дашбордов
GPU-метрики включаются в существующую эксплуатацию: история, события, оповещения, отчёты и дашборды внутри одной платформы.
Оповещения, история и отчёты
Каждая GPU-метрика может генерировать оповещения, сохраняться в истории и отображаться в отчётах. Та же операционная модель серверов и сети может применяться и к GPU.
СВЯЗАННЫЕ РЕСУРСЫ
Расширьте знания о GPU monitoring

GPU monitoring: мониторинг GPU для ИИ и гибридных сред
Какие метрики контролировать, чем отличаются nvidia-smi и платформы мониторинга, и как интегрировать GPU monitoring в стратегию AI infrastructure monitoring.
Читать статью →
Мониторинг серверов и инфраструктуры
Pandora FMS позволяет контролировать физические, виртуальные и cloud-серверы в единой платформе. GPU интегрируются в этот общий контекст.
Смотреть решение →
ИИ для IT management и интеллектуального мониторинга
Обнаружение аномалий, прогнозирование и автоматизация в вашей ИТ-инфраструктуре. GPU monitoring — часть более широкой стратегии AI infrastructure monitoring.
Смотреть решение →Часто задаваемые вопросы о GPU monitoring
Концепция
Что такое GPU monitoring?
GPU monitoring — это непрерывный контроль состояния, использования, памяти, температуры, энергопотребления и ошибок GPU в профессиональных средах. Он применяется к инфраструктурам ИИ, HPC, инференса и обучения моделей. Его не следует путать с инструментами для gaming, overclocking или графического tuning.
Какие GPU поддерживает плагин Pandora FMS?
Плагин поддерживает GPU NVIDIA. Он использует nvidia-smi как источник данных и требует установленного драйвера NVIDIA на хосте. В текущей версии AMD и Intel не поддерживаются.
Совместимость
Работает ли он в on-premise и cloud-средах?
Да. Плагин работает как локальный агент на хосте с GPU. Linux проверен (amd64 / arm64). Windows находится на финальной проверке. Его можно использовать на on-premise-серверах, в гибридных средах и cloud-инстансах с GPU, доступной операционной системе. Удалённый доступ или дополнительная настройка сети не требуются.
Какие метрики он мониторит?
Плагин охватывает использование и состояние GPU, используемую и свободную память, температуру, энергопотребление и лимит мощности, ошибки ECC, если применимо, а также технические данные, такие как модель GPU, версия драйвера и версия CUDA. Техническая документация плагина будет доступна в Marketplace.
Отличия
Чем отличаются nvidia-smi и Pandora FMS для GPU monitoring?
nvidia-smi — полезная командная утилита для точечных запросов. Pandora FMS использует nvidia-smi как источник данных и интегрирует эти метрики в платформу с историей, оповещениями, дашбордами, отчётами и корреляцией с остальной инфраструктурой.
Мониторит ли плагин модели ИИ или MLOps-метрики?
Нет. Плагин мониторит GPU-инфраструктуру: оборудование, производительность, память, температуру и энергопотребление. Он не мониторит модели ИИ, prompts, detection drift или MLOps-метрики.
Начните мониторить ваши GPU NVIDIA с Pandora FMS
Интегрируйте мониторинг GPU NVIDIA в вашу ИТ-эксплуатацию и превращайте изолированные метрики в оповещения, историю, дашборды и операционные отчёты.
