








Sections
- What is infrastructure monitoring?
- How infrastructure monitoring works
- Infrastructure monitoring use cases
- Benefits of infrastructure monitoring
- Infrastructure monitoring best practices
- Selecting an infrastructure monitoring tool
- Pandora FMS: A comprehensive infrastructure monitoring solution
- Conclusion
Learn how infrastructure monitoring allows you to stay on top of the health and performance of infrastructure components across cloud, on-premises, and hybrid environments. Explore how infrastructure monitoring works, its use cases, challenges, and recommended tools to get started.
What is infrastructure monitoring?
The digital economy makes it imperative to have end-to-end visibility of the whole IT technology infrastructure, its component records and performance metrics, not only to ensure that resources are available, but also to improve response times and have decision elements on the root cause of an existing problem or prevent possible risks.
Infrastructure monitoring evolution
Infrastructure monitoring was traditionally carried out on static and tangible components, in a reactive process, when IT teams had to take actions when a problem took place in the equipment (servers, CPU or networks, basically). Of course, this approach was inefficient, resulting in infrastructure failures, which in turn led to some unproductivity and even economic losses for organizations. Now that we are experiencing the adoption of cloud (public, private and hybrid), legacy systems, virtualization and containerization (simulation of an operating system), infrastructure monitoring has become very dynamic and much more complex to identify, solve and anticipate possible problems in real time. IT teams have shifted focus, so they are looking to be more proactive in monitoring infrastructure on an ongoing basis, in order to identify potential issues and take action before they even take place.
Some infrastructure monitoring metrics are related to:
- CPU: Usage, average load, CPU idle/standby time.
- Memory: Total memory, used or free, memory page swaps. Disk: Disk Input/Output, Usage, Capacity, Disk Read/Write Rates.
- Infrastructure health: Uptime/downtime, system availability, hardware errors, service/process status.

How infrastructure monitoring Works
For infrastructure monitoring, there are two methods for collecting system data:
- Agent-based.
Agents (instrumentation) are installed on systems (server or device) to detect data and metrics that reflect the infrastructure state and performance, such as memory and CPU usage of a computer, as well as bandwidth, disk space, connection error rates, among others. Alerts can be set and recommendations and actions proactively automated. The disadvantage is that agent usage consumes system resources such as CPU cycles, memory, and bandwidth to collect and transmit data.

- Agentless.
As noted, this method does not require the installation of a separate software agent on the host, as it uses protocols such as Windows Management Instrumentation, Secure Shell and NetFlow, to collect and deliver system data to the infrastructure monitoring solution. This allows it to operate in different heterogeneous environments, with operating systems and platforms that support protocols or application programming interfaces (APIs). There is also less impact on performance as there is no need to run on individual systems or additional resources. The disadvantage of this is that the available data can be limited, as not all metrics can be accessible and it depends heavily on the network. If the network fails, monitoring will also fail.
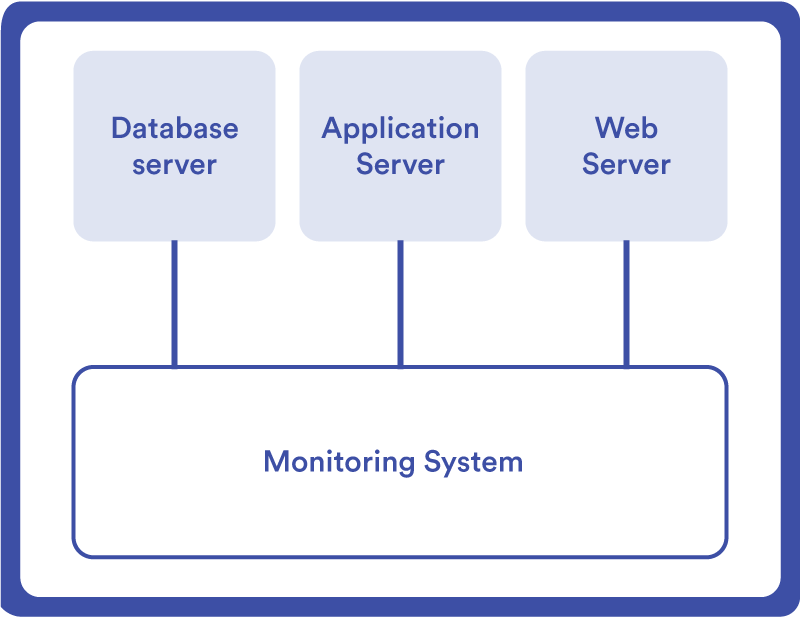
The advantages and disadvantages of these methods have made IT teams choose to combine both, so it is recommended to rely on a strong monitoring system, capable of managing them.
Infrastructure monitoring use cases
Through the correct data analysis and the appropriate tool for infrastructure monitoring, the following can be implemented:
- Performance optimization. Beyond monitoring performance, you may understand how and what resources can improve your performance.
- Proactive problem detection. Perform the proper reading with alerts and warnings that contribute to preventing situations that put system operation at risk.
- Capacity planning and scalability. Having an analysis of history data makes it possible to predict when the infrastructure could reach its limits and make decisions about the necessary scaling.
- Fault identification and root cause analysis. Having data that makes inefficiency detection easier, as well as understanding the root cause of the problem.
- Compliance with Service Level Agreements (SLAs). Having hard data with which the service levels that were negotiated in a Service Level Agreement can be complied with.
- Capacity optimization and cost management. Analyzing monitoring provides information on the capacity at the time of deployment, and can also implement the cost management of infrastructure (overused or underused), preventing unnecessary expenses.
- Security Monitoring. Compliance has become essential for organizations, so infrastructure monitoring allows you to have elements about preventive actions taken (if they are corrective actions) on events in systems, network traffic or security threats.
Benefits of infrastructure monitoring
- Improved mean time to repair (MTTR). By having a comprehensive and consolidated view of the state of the infrastructure, correlations and problem causes can be identified, risks and times to detect (time to detect, MTTD) and remediate (mean time to remediate, MTTR) incidents are reduced.
- Observability. The right monitoring tools can collect real-time data to get a detailed picture of everything going on within each of your IT resources, allowing you to spot problems before they become serious situations.
- Full visibility of the technology stack. A comprehensive view of the state of the infrastructure allows for a better context that leads to a more accurate and fast resolution of risk situations.
Another very important benefit is that IT teams can invest less time in solving problems to allocate it to the analysis and optimization of the infrastructure that will be of greater value to users and, therefore, to the business.
Infrastructure monitoring best practices
- Automation. It uses automation tools to monitor systems and applications continuously, reducing the need for manual intervention.
- Setting up detailed alerts. With the right, detailed alerts, you need to move from a reactive approach (which can be costly in time, effort, and expense) to a proactive approach. You should strategically choose what you would like to be alert about, to avoid Alert Fatigue.
- Alert prioritization. Determine what type of alerts should be prioritized. For example, the crash of a mission-critical server can have a critical impact for users in the organization (and even for the end customer itself), so it will need to be dealt with urgently.
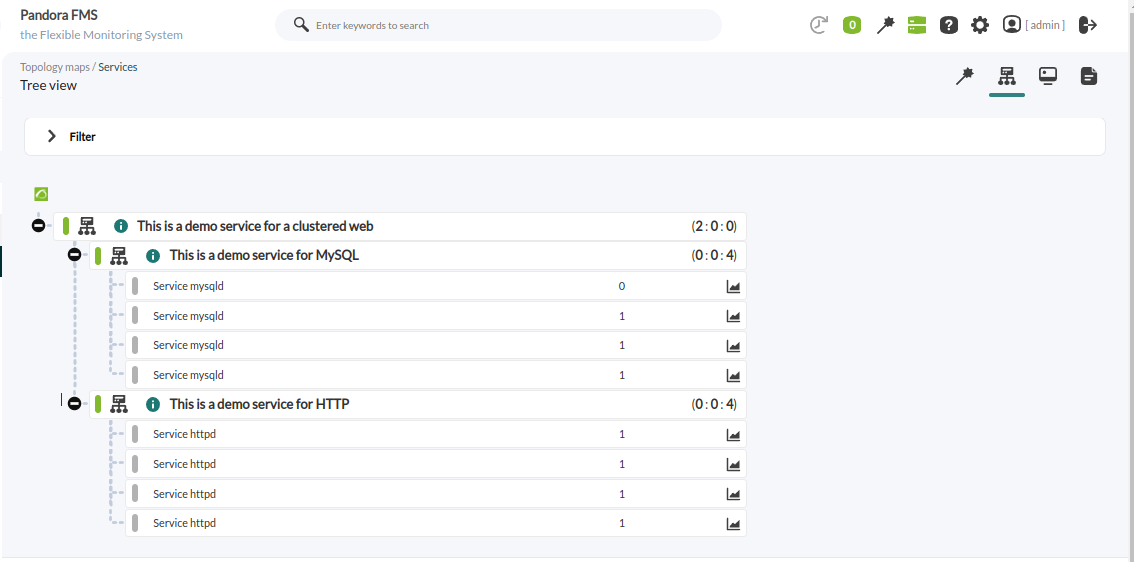
- Create role-specific dashboards.
Leading solutions for infrastructure monitoring allow you to create custom dashboards, according to the role of each user. For example, alerts that are interesting to a SecOps team (security operations: detect, respond, and recover) are different than those that are relevant to a CFO. The monitoring panel also lends itself to discussing, analyzing and collaborating on infrastructure performance.
- Function tests. Test your infrastructure under high load conditions to reveal potential weaknesses and avoid a real disaster. Let’s say you do the highest stress test possible. Strong monitoring tools have the resources to be able to do simulations.
- Regular metric review. Make sure that monitoring parameters and the tools that measure them are updated and evolve with your infrastructure.
Another recommendation experts make is to take a holistic approach – seeing components as part of a whole ecosystem that includes servers, databases, networks, and applications.
Selecting an infrastructure monitoring tool
- All-in-one platform. We will refer to a centralized platform that allows you to simultaneously monitor all infrastructure components (networks, physical and virtual servers, storage, on-premises and cloud applications) in real time. It must also allow you to keep a record of multiple licenses.
- Artificial Intelligence Assistance. Leading infrastructure monitoring providers have adopted advanced analytics and artificial intelligence not only to obtain health and availability metrics, but also for network bandwidth analysis for physical and virtual networks.
- Contextual information. Tools with the ability to perform diagnostics and information crossings to obtain accuracy in anomaly detection and alert.
- Root Cause Analysis. Solutions that allow the Root Cause to be identified, remembering that a root cause is a factor that caused a non-conformity and must be eliminated through process improvement.
- Automation for large-scale dynamic environments. Given the complexity that continues to take place every day, automation not only reduces time spent on repetitive tasks, but also ensures consistency in operation and avoids human error.
- Comprehensive Coverage fo Hybrid Cloud Environments. We know that the trend continues to be the coexistence of public and private cloud with on-premise environments. An infrastructure monitoring solution must be able to provide comprehensive reading and analysis.
- Support for Cloud-native Architectures. Many organizations are adopting a cloud-first strategy, in which organizations choose the cloud as the first choice for any new technology or business initiative. This makes it necessary for your system monitoring solution provider to have the right proposition for IaaS, SaaS, PaaS, including local hosts, orchestrated containers, and even virtual machines.
In addition, it is recommended to take an approach with a supplier who is able to give a clear explanation about the pricing model in the monitoring tools, to ensure that it aligns with your budget and the scale of operations of your company. Also consider upfront costs and ongoing expenses.
Pandora FMS: A comprehensive infrastructure monitoring solution
Pandora FMS Special Capabilities
Pandora FMS is the only manufacturer that integrates an all-in-one solution and offers professional services to help companies throughout the implementation process.
- Other products don’t cover all current needs (log, network, application, server, SAP, as400, database or cloud management).
- Some manufacturers integrate different products into a single suite, like a technological frankenstein.
- Other manufacturers say they cover all areas but have a time-consuming “do-it-yourself” proposition that takes a lot of time and investment in development and integration resources.
In addition, Pandora FMS is ready to use components on Android, ARM and other embedded systems that can be completely customized.
Pandora FMS offers these special features:
- Agentless Monitoring. Although we recommend installing a local agent, you may also discover your servers and get information remotely from them without installing agents.
- Low-level Monitoring. Pandora FMS agents, like the rest of our technology, are a development of our own, not derived from third parties. They can get the information directly from the source, using native calls to the operating system, without third-party connectors or heavy artifacts. Their footprint on the system is minimal.
- Full Customization. Pandora FMS will allow you to customize your server monitoring, allowing you to monitor any process, service or application, reusing your own scripts or allowing you to deploy new ones.
Technical Pandora FMS Features
- Scalability. The federated structure of Pandora FMS allows to distribute the whole load between different nodes, so that the processing load is shared and processed in parallel. Our Command Center allows to display and manage all the information together. We have licenses for several hundred thousand operating agents.
- Integration with Modern Technologies. Pandora FMS supports integrations of emerging technologies, (and even with legacy systems). An example is artificial intelligence that allows you to automate repetitive work, in addition to monitoring the temperature or status of equipment, safety, risks of all kinds, among others. In addition, predictive and resource optimization analytics can be performed to improve processing and reduce common risk factors.
- Centralized Management. Pandora FMS is a comprehensive and centralized monitoring solution for full observability of each of the IT components and the relationship between them and their users and owners that allows reducing risks and costs with better scale economies, boosting collaboration between IT teams, improving times in analysis, diagnosis and resolution of incidents and, above all, helping your IT teams to optimize their work.
Conclusion
It is no longer a question of resources being available, but of ensuring performance and analyzing the infrastructure to optimize, prevent costs and risks that impact productivity and user experience. It is clear that the complexity of monitoring different environments (on-premise, in private, public or hybrid cloud) and multiple devices make it necessary to adopt monitoring capable of integrating technologies (Artificial Intelligence, Automation) that streamline the task of IT employees and rely on experts to make decisions on how to combine monitoring data collection methods and how to apply best practices according to the needs of the organization.
It is also recommended to select a strong monitoring system, capable of managing resources with a holistic and contextualized view, such as Pandora FMS, which offers:
- All-in-one platform.
- Artificial Intelligence Assistance.
- Contextual information.
- Root Cause Analysis.
- Automation for large-scale dynamic environments.
- Comprehensive Coverage for Hybrid Cloud Environments.
- Support for Cloud-native Architectures.
As well as its specific features:
- Agentless monitoring, to obtain remote information, without the need to install agents.
- Low-level monitoring to get information directly from the source, using native operating system calls, without third-party connectors.
- Total customization of server monitoring and any process, service or application.
In addition, it is recommended to take an approach with a supplier who is able to give a clear explanation about the pricing model in the monitoring tools, to ensure that it aligns with your budget and the scale of operations of your company.
Beyond limits, beyond expectations