
 Home
Home
Ingénierie de Pandora FMS
Conception de la base de données de Pandora FMS
Les premières versions de Pandora FMS, de la 0.83 à la 1.1, étaient basées sur une idée très simple : une donnée, une insertion dans la base de données. Cela permettait au logiciel d'effectuer des recherches faciles, des insertions et d'autres opérations rapidement.
Outre tous les avantages que comportait ce développement, il y avait un inconvénient : La évolutivité (croissance rapide sans affecter ou en affectant peu les opérations et les routines de travail). Ce système avait une limite définie par le nombre maximum de modules qu'il pouvait supporter, et avec une certaine quantité de données (plus de 5 millions d'éléments), les performances étaient affectées.
Les solutions basées sur le cluster MySQL, en revanche, sont difficiles : bien qu'elles permettent de gérer une charge plus importante, elles ajoutent des problèmes et des difficultés supplémentaires, et n'offrent pas non plus de solution à long terme au problème de performance avec une grande quantité de données.
Actuellement, Pandora FMS implémente un compactage des données en temps réel pour chaque insertion, en plus de réaliser une compression des données basée sur l'interpolation. D'autre part, la tâche de maintenance permet de supprimer automatiquement les données dépassant une certaine ancienneté.
Le système de traitement de Pandora FMS ne stocke que les « nouvelles » données : si une valeur dupliquée entre dans le système, elle ne sera pas stockée dans la base de données. Ceci est très utile pour maintenir la base de données réduite et fonctionne pour tous les types de modules de Pandora FMS (numérique, incrémentiel, booléen et chaîne de caractères).
Ces modifications entraînent des changements majeurs lors de la lecture et de l'interprétation des données. Dans les dernières versions de Pandora FMS, le moteur graphique a été redessiné de zéro afin de pouvoir représenter les données rapidement avec le nouveau modèle de stockage des données.
Les mécanismes de compactage ont, de plus, certaines implications lors de la lecture et de l'interprétation graphique des données : il existe actuellement un menu de configuration graphique qui permet d'ajouter des centiles, des données en temps réel, le moment où les événements et/ou alertes se sont produits, ainsi que d'autres options.
De plus, Pandora FMS permet la désagrégation totale des composants, ce qui permet d'équilibrer la charge de traitement des fichiers de données et l'exécution des modules réseau sur différents serveurs.
Autres aspects techniques de la BDD
Au fil des mises à jour du logiciel, des améliorations ont été apportées au modèle relationnel de la base de données de Pandora FMS. L'un des changements introduits a été l'indexation des informations sur la base de différents types de modules. De cette façon, Pandora FMS peut accéder aux informations beaucoup plus rapidement, car elles sont réparties dans différentes tables.
Il est possible d'effectuer un partitionnement des tables (par horodatages) pour améliorer encore les performances d'accès aux historiques de données.
De plus, des facteurs tels que la représentation numérique des horodatages (_timestamp_ format UNIX), accélèrent les recherches de plages de dates, les comparaisons de celles-ci, etc. Ce travail a permis une amélioration considérable des temps de recherche et des insertions.
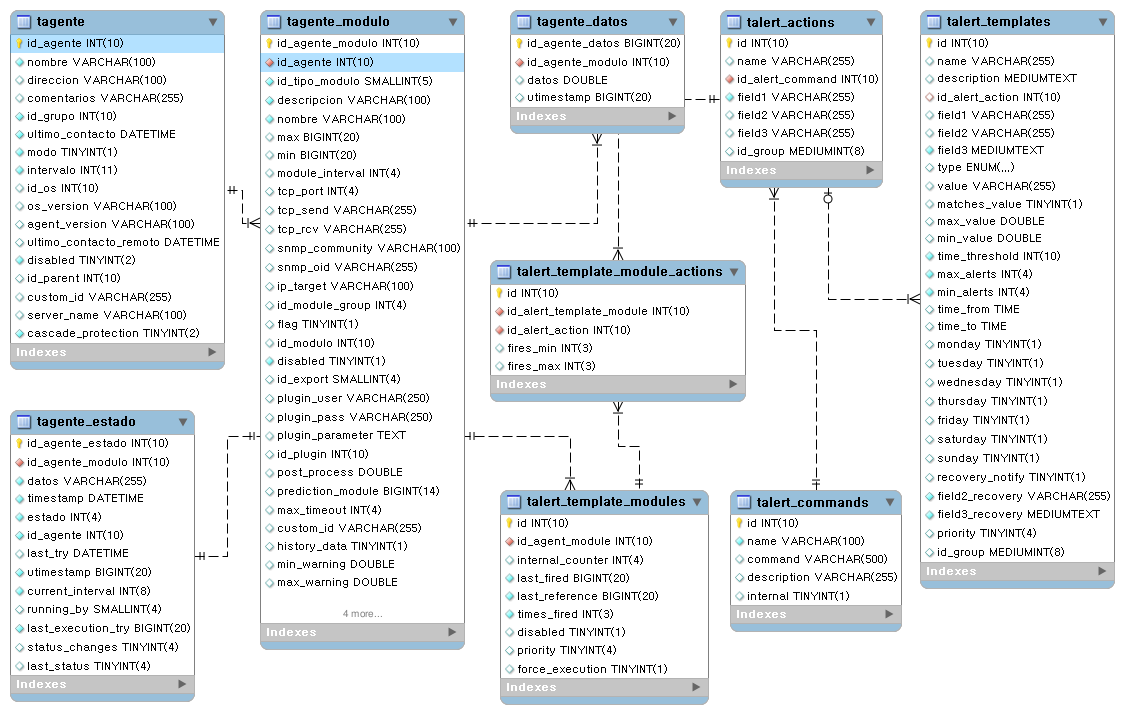
Tables principales de la base de données
Compression des données en temps réel
Pour éviter de surcharger la base de données, le PFMS Server effectue une compression simple au moment de l'insertion. Une donnée n'est pas enregistrée dans la base de données à moins qu'elle ne soit différente de la précédente ou qu'il y ait une différence de plus de 24 heures entre les deux.
Par exemple, en supposant un intervalle approximatif de 1 heure, la séquence 0,1,0,0,0,0,0,0,1,1,0,0 est stockée dans la base de données sous la forme 0,1,0,1,0. Aucun autre 0 consécutif ne sera enregistré à moins que vingt-quatre heures ne se soient écoulées.
La compression affecte grandement les algorithmes de traitement des données, tant pour les métriques que pour les graphiques, et il est important de noter qu'il faut combler les « vides » causés par la compression.
Compte tenu de tout ce qui précède, pour effectuer des calculs avec les données d'un module pour un intervalle et une date initiale donnés, il faut suivre les étapes suivantes :
- Rechercher la donnée précédente, en dehors de l'intervalle et de la date donnés. Si elle existe, il faut la ramener au début de l'intervalle. Si elle n'existait pas auparavant, il n'y aurait pas de données.
- Rechercher la donnée suivante, en dehors de l'intervalle et de la date donnés jusqu'à un maximum égal à l'intervalle du module. Si elle existe, il faut la ramener à la fin de l'intervalle. Si elle n'existe pas, il faudrait prolonger la dernière valeur disponible jusqu'à la fin de l'intervalle.
- Toutes les données sont parcourues, en gardant à l'esprit qu'une donnée est valide jusqu'à ce qu'une donnée différente soit reçue.
Compactage des données
Pandora FMS a inclus un système pour compacter les informations de la base de données. Ce système est orienté vers des scénarios de petite et moyenne taille (de 250 à 500 agents et avec moins de 100 000 modules) qui souhaitent avoir un historique étendu d'informations mais en perdant des détails.
La maintenance de la base de données de Pandora FMS qui s'exécute chaque heure et parmi d'autres tâches de nettoyage permet d'effectuer un compactage des données anciennes. Ce compactage utilise une interpolation simple et linéaire ; s'agissant d'une interpolation, cela entraîne une perte de détails dans cette information, mais elle restera suffisamment informative pour la génération de rapports et de graphiques mensuels, annuels, etc.
Dans les bases de données de grande taille, ce comportement peut être assez coûteux en termes de performances et devrait être désactivé ; à la place, il est recommandé d'opter pour le modèle de base de données historique.
Base de données historique
La base de données historique est une fonctionnalité utilisée pour stocker toutes les informations passées, qui ne sont pas utilisées dans les vues des jours récents, comme par exemple les données datant de plus d'un mois. Ces données sont migrées, de manière automatique, vers une base de données différente, qui doit se trouver sur un serveur distinct avec un stockage différent de celui de la base de données principale.
Lorsqu'un graphique ou un rapport avec des données anciennes est affiché, Pandora FMS cherchera les premiers jours dans la base de données principale, et en arrivant au point où elles sont migrées vers la base de données historique, il passera à la recherche dans celle-ci. Grâce à cela, les performances sont maximisées même en accumulant une grande quantité d'informations dans le système.
Configuration avancée
La configuration par défaut de Pandora FMS ne transfère pas les données de type chaîne de caractères (string) vers la base de données historique, cependant si cette configuration a été modifiée et que la base de données historique reçoit ce type d'informations, il est impératif que sa purge soit configurée, car sinon elle finira par occuper trop d'espace, causant des problèmes majeurs et ayant un impact négatif sur les performances.
Pour configurer ce paramètre, il faudra exécuter directement une requête dans la base de données pour déterminer le nombre de jours après lesquels ces informations seront purgées. La table en question est tconfig et le champ string_purge. Pour établir 30 jours pour la purge de ce type d'informations, la requête suivante serait exécutée directement sur la base de données historique :
UPDATE tconfig SET VALUE = 30 WHERE token = "string_purge";
La base de données est maintenue par un script appelé pandora_db.pl. Pour vérifier que la maintenance de la base de données est effectuée correctement, on peut exécuter le script de maintenance manuellement :
/usr/share/pandora_server/util/pandora_db.pl /etc/pandora/pandora_server.conf
Il ne devrait signaler aucune erreur.
Si une autre instance utilise la base de données, on peut utiliser l'option -f qui force l'exécution ; avec le paramètre -p, il n'effectue pas de compactage des données. Ceci est particulièrement utile dans les environnements de Haute disponibilité (HA) avec base de données historique, car le script s'assure d'effectuer les étapes nécessaires pour ces composants dans l'ordre et le mode appropriés.
États des modules dans Pandora FMS
Quand chaque état est-il établi ?
- D'une part, chaque module possède dans sa configuration des seuils d'Avertissement (
WARNING) et Critique (CRITICAL) :
- Ces seuils définissent les valeurs de ses données pour lesquelles ces états seront activés.
- Si le module fournit des données en dehors de ces seuils, il est considéré comme étant en état Normal (
NORMAL).
- Chaque module possède, de plus, un intervalle de temps qui établira la fréquence avec laquelle il obtiendra les données :
- Cet intervalle sera pris en compte par la console pour collecter les données.
- Si le module passe le double de son intervalle sans collecter de données, ce module est considéré comme étant en état Inconnu (
UNKNOWN).
- Enfin, si le module a des alertes configurées et que l'une d'entre elles a été déclenchée et n'a pas été validée, le module aura l'état correspondant d'Alerte déclenchée.
Propagation et priorité
Dans l'organisation de Pandora FMS, certains éléments dépendent d'autres, comme c'est le cas pour les modules d'un agent ou les agents d'un groupe. Cela peut également s'appliquer au cas des politiques de supervision de Pandora FMS, auxquelles sont associés certains agents et certains modules considérés comme associés à chaque agent.
Cette structure est particulièrement utile pour évaluer les états des modules au premier coup d'œil. Ceci est réalisé en propageant les états vers le haut de cette organisation, accordant ainsi un état aux agents, groupes et politiques.
Quel état aura un agent ?
Un agent sera affiché avec l'état le plus critique parmi les états de ses modules. À son tour, un groupe aura l'état le plus critique parmi les états des agents qui lui appartiennent, et il en va de même pour les politiques de supervision qui auront l'état le plus critique de leurs agents assignés.
De cette façon, en voyant un groupe avec un état critique, on saura qu'au moins un de ses agents a ce même état. Pour le localiser, il faudra descendre d'un autre niveau, celui des agents, pour resserrer la recherche et trouver le ou les modules responsables de la propagation de cet état critique.
Quelle est la priorité des états ?
Comme l'état le plus critique des états est propagé, il faut être clair sur les états qui sont prioritaires par rapport aux autres :
- Alertes déclenchées.
- État critique.
- État d'avertissement.
- État inconnu.
- État normal.
Lorsqu'un module a des alertes déclenchées, son état est prioritaire sur tous les autres et l'agent auquel il appartient aura cet état, tout comme le groupe auquel appartient cet agent.
D'autre part, pour qu'un groupe, par exemple, ait un état normal, tous ses agents doivent avoir cet état ; ce qui signifie qu'à leur tour tous les modules de ces groupes auront un état normal.
Code couleurs
 État d'Alertes déclenchées.
État d'Alertes déclenchées.
 État Critique.
État Critique.
 État d'Avertissement.
État d'Avertissement.
 État Inconnu.
État Inconnu.
 État Normal.
État Normal.
Graphiques de Pandora FMS
Les graphiques sont l'une des implémentations les plus complexes de Pandora FMS, ils extraient des données en temps réel de la base de données et n'utilisent aucun système externe (RRDtool ou similaire).
Il existe plusieurs comportements de graphiques en fonction du type de données sources :
- Modules asynchrones. On suppose qu'il n'y a pas de compactage des données. Les données présentes dans la base de données sont tous les échantillons réels de la donnée, il n'y a pas de compactage. Cela produit des graphiques beaucoup plus « exacts » et sans possibilité de mauvaise interprétation.
- Modules de type chaîne de caractères. Ils affichent des graphiques avec le débit de données au fil du temps.
- Modules de données numériques. La plupart des modules rapportent ce type de données.
- Modules de données booléennes. Ils correspondent à des données numériques dans les moniteurs,
PROCtels que les tests Ping, l'état des interfaces, etc. La valeur0correspond à l'état Critique, et la valeur1à l'état Normal.

