
Discovery
Este plugin puede integrarse con el Discovery de Pandora FMS.
Para ello se debe cargar el paquete ".disco" que puede descargar desde la librería de Pandora FMS:
https://pandorafms.com/library/
Una vez cargado, se podrán monitorizar entornos de PostgreSQL creando tareas de Discovery desde la sección Management > Discovery > Applications.
Para cada tarea se solicitarán los siguientes datos mínimos:
-
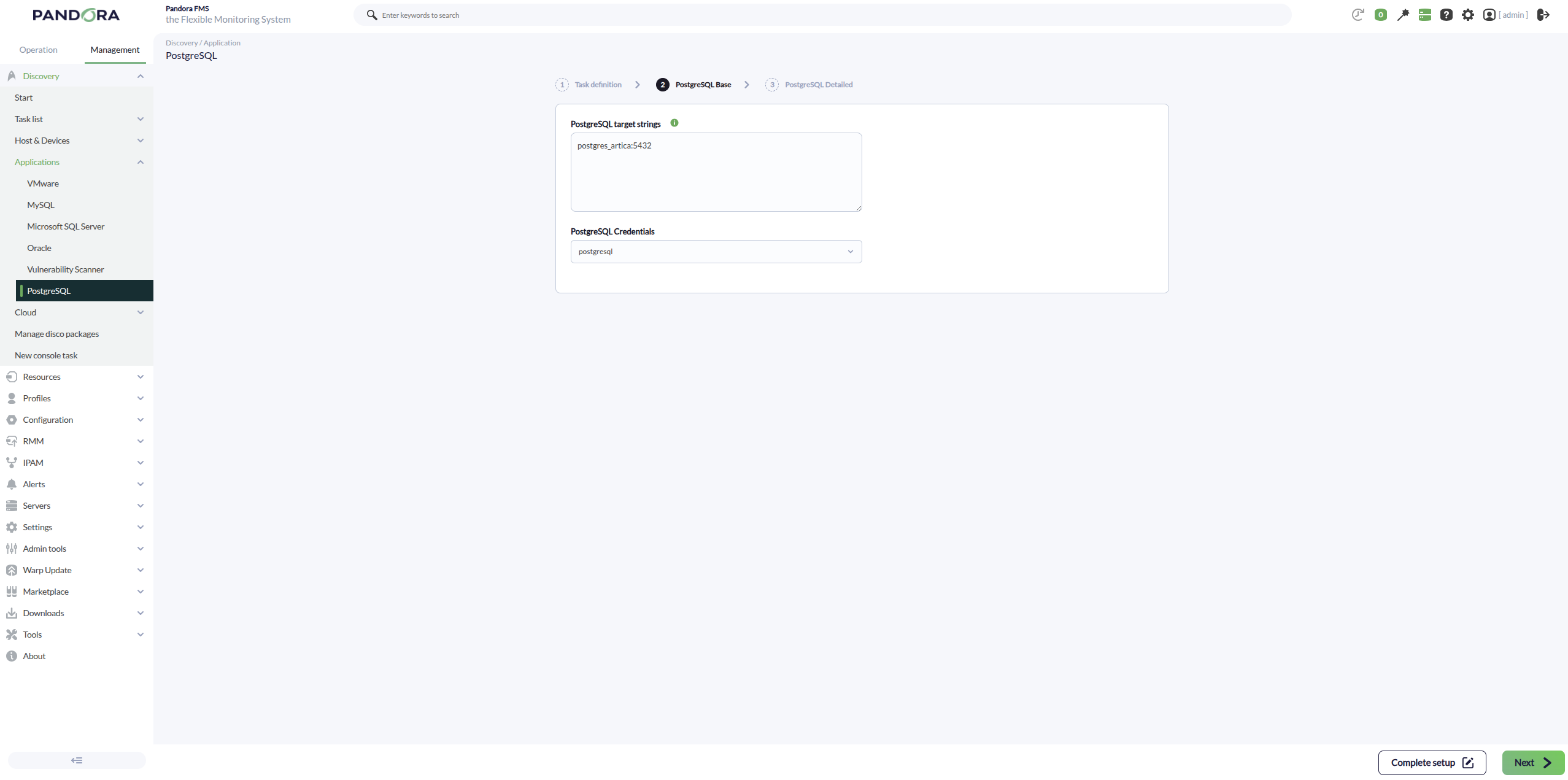
PostgreSQL target strings: Lista de objetivos PostgreSQL a monitorizar por la tarea. Será una lista separada por comas o por líneas. Cada objetivo PostgreSQL se podrá definir con el formato
IP:PUERTOoIP, admitiendo también la selección o exclusión explícita de bases de datos (ver Listado de bases de datos objetivo). - PostgreSQL Credentials: Credenciales de conexión de tipo Custom. Será necesario seleccionar una credencial previamente creada en Management > Configuration > Credential store.
También se podrá ajustar la configuración de la tarea para personalizar la monitorización deseada:
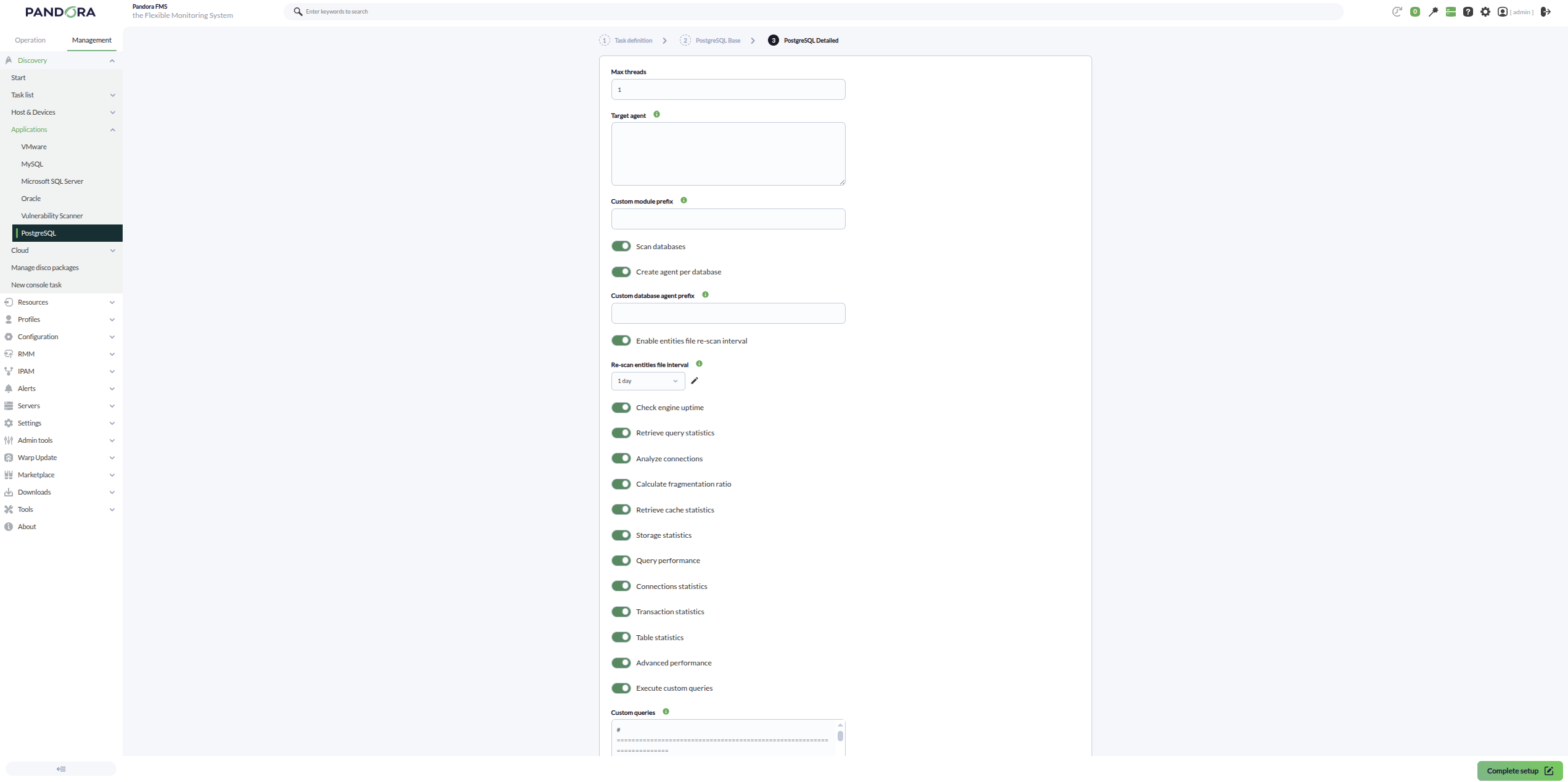
- Max threads: Para optimizar el tiempo de ejecución, se podrán configurar múltiples hilos para monitorizar los agentes de la tarea. Hay que tener en cuenta que configurar múltiples hilos puede aumentar el uso de CPU de la tarea.
- Target agent: Lista de agentes objetivo para los objetivos PostgreSQL a monitorizar. Si no se especifica un nombre de agente para un objetivo se usará su IP o FQDN como nombre del agente.
- Custom module prefix: Texto incluido como prefijo para todos los nombres de módulos generados.
- Scan databases: Si se activa se descubrirán las distintas bases de datos de cada objetivo PostgreSQL.
- Create agent per database: Si se activa se creará un agente distinto para cada base de datos descubierta.
- Custom database agent prefix: Texto incluido como prefijo para los nombres generados para los agentes individuales de cada base de datos descubierta.
-
Enable entities file re-scan interval: Si se activa se utilizará un fichero persistente de entidades descubiertas para comprobar bases de datos previamente detectadas aunque ya no aparezcan en el escaneo actual. De este modo, si una base de datos desaparece del escaneo, su módulo
connectionpodrá pasar a estado crítico en lugar de quedar simplemente huérfano. - Re-scan entities file interval: Intervalo de revalidación del fichero de entidades descubiertas.
- Check engine uptime: Si se activa monitorizará el uptime de los objetivos PostgreSQL.
-
Retrieve query statistics: Si se activa monitorizará estadísticas de consultas a nivel de instancia:
-
queries: Número de consultas activas dentro del intervalo configurado. -
insert: Número de consultas INSERT activas. -
delete: Número de consultas DELETE activas. -
update: Número de consultas UPDATE activas.
-
-
Analyze connections: Si se activa monitorizará estadísticas de conexiones de la instancia:
-
session usage: Porcentaje de uso de conexiones respecto al máximo configurado.
-
-
Calculate fragmentation ratio: Si se activa monitorizará estadísticas de fragmentation ratio:
-
fragmentation ratio: Ratio medio estimado de fragmentación.
-
-
Retrieve cache statistics: Si se activa monitorizará estadísticas de caché de la instancia:
-
allocated buffer cache: Total de buffers compartidos asignados. -
backend used buffer cache: Buffers utilizados por procesos backend. -
checkpoints buffer cache: Buffers escritos por checkpoints. -
cleaned buffer cache: Buffers limpiados por el writer.
-
-
Storage statistics: Si se activa monitorizará estadísticas de almacenamiento de las bases de datos descubiertas:
-
database size: Tamaño total de la base de datos. -
tables size: Tamaño total ocupado por las tablas. -
indexes size: Tamaño total ocupado por los índices. -
temp bytes: Cantidad de datos temporales escritos en disco. -
temp files: Número de ficheros temporales creados.
-
-
Query performance: Si se activa monitorizará estadísticas de rendimiento de consultas:
-
long queries: Número de consultas activas con duración superior al intervalo configurado. -
oldest query age: Tiempo de ejecución de la consulta activa más antigua. -
sequential scans: Número de escaneos secuenciales realizados. -
index scans: Número de escaneos realizados utilizando índices. -
cache hit ratio: Ratio de aciertos de caché de la base de datos.
-
-
Connections statistics: Si se activa monitorizará estadísticas de conexiones por base de datos:
-
active connections: Número de conexiones activas. -
idle connections: Número de conexiones inactivas. -
total connections: Número total de conexiones abiertas.
-
-
Transaction statistics: Si se activa monitorizará estadísticas de actividad transaccional:
-
transactions: Número total de transacciones ejecutadas. -
commits: Número de transacciones confirmadas. -
rollbacks: Número de transacciones revertidas. -
rollback ratio: Ratio de transacciones revertidas respecto al total. -
deadlocks: Número de deadlocks detectados. -
conflicts: Número de conflictos detectados en la base de datos.
-
-
Table statistics: Si se activa monitorizará estadísticas estructurales de tablas:
-
table count: Número total de tablas de usuario. -
index count: Número total de índices de usuario. -
live tuples: Número estimado de registros activos. -
dead tuples: Número estimado de registros obsoletos pendientes de limpieza. -
fragmentation ratio: Ratio medio estimado de fragmentación de tablas.
-
-
Advanced performance: Si se activa monitorizará métricas avanzadas de rendimiento:
-
blocks read: Número de bloques leídos desde disco. -
blocks hit: Número de bloques obtenidos desde caché.
-
- Execute custom queries: Si se activa permitirá ejecutar consultas personalizadas sobre la instancia y sobre las bases de datos descubiertas.
-
Custom queries: Bloque de configuración para definir las consultas personalizadas que se ejecutarán. Admite los campos
target_scope(instances,databasesoall) y la palabra reservada$__self_dbnamepara componer dinámicamente el nombre del módulo y la consulta en función de la base de datos en la que se ejecute.
Comportamiento del descubrimiento:
- Siempre se creará un agente principal para cada objetivo PostgreSQL.
- Si Scan databases está activado, se descubrirán las bases de datos del objetivo.
- Si Create agent per database está activado, se creará un agente independiente por cada base de datos descubierta. En caso contrario los módulos de la base de datos se generarán en el agente principal utilizando como prefijo el nombre de la base de datos.
- El módulo connection se creará siempre para cada base de datos descubierta, incluso aunque no haya otros tokens activados.
- El módulo POSTGRESQL connection se creará siempre para el agente principal (instancia) con el objetivo de reflejar la disponibilidad global de la instancia.
- Cuando Enable entities file re-scan interval está activo, las bases de datos previamente detectadas se persisten en el fichero de entidades, de manera que si dejan de aparecer en el escaneo actual el plugin seguirá generando su módulo
connection(que podrá pasar a estado crítico) en lugar de eliminarlas silenciosamente.
Las tareas que se completen exitosamente dispondrán de un sumario de ejecución con la siguiente información:
- Total agents: Total de agentes generados por la tarea.
- Targets up: Total de objetivos a los que ha sido posible conectar.
- Targets down: Total de objetivos a los que no ha sido posible conectar.