SQLServer
Este documento describe la funcionalidad SQLServer del discovery de PandoraFMS.
- Introducción
- Prerrequisitos
- Parámetros y configuración
- Ejecución manual
- Discovery
- Agentes y módulos generados por el plugin
Introducción
Este plugin tiene como finalidad monitorizar bases de datos SQL Server, mediante consultas que extraerán información sobre datos que son claves para conocer el rendimiento y estado de la bases de datos, como son el número de conexiones, número de consultas y estado de los reinicios. Estos datos se verán reflejados en PandoraFMS, en módulos que aportaran el valor estadístico, dentro de un agente que representará a cada base de datos.
Este plugin está desarrollado para usarse con Pandora FMS Discovery, por lo que a diferencia de otros plugins no genera agentes por XML, si no que todo lo descubierto se devuelve en la salida JSON del plugin.
Prerrequisitos
Este plugin realiza conexiones remotas a las bases de datos a monitorizar, por lo que es necesario asegurar la conectividad entre el servidor de Pandora FMS y dichas bases de datos.
A su vez los siguientes permisos son requeridos para el usuario que se utiliza para conectar.
VIEW SERVER STATE:
Para ejecutar la consulta SELECT @@VERSION.
Para consultar sys.dm_os_sys_info (tiempo de actividad del servidor).
Para consultar sys.dm_exec_requests (solicitudes activas en el servidor).
Para consultar @@MAX_CONNECTIONS (máximo de conexiones permitidas).
Para ejecutar sp_who 'ACTIVE' (sesiones activas en el servidor).
SELECT:
Para ejecutar consultas personalizadas en las tablas o vistas de las bases de datos específicas.
Parámetros y configuración
Parámetros
| --conf | Ruta al archivo de configuración |
| --target_databases | Ruta al archivo de configuración que contiene los targets de las bases de datos |
| --target_agents | Ruta al archivo de configuración que contiene los targets de los agentes |
| --custom_queries | Ruta al archivo de configuración que contiene las consultas personalizadas |
Archivo de configuración (--conf)
[CONF]
agents_group_id = < ID del grupo en el que se crearán los agentes >
interval = < Intervalo de monitorización de los agentes en segundos >
user = < Usuario de conexión >
password = < Contraseña >
threads = < Número de hilos que se usaran para la creación de agentes >
modules_prefix = < Prefijo de módulos >
entities_list = < Ruta del fichero de entidades >
execute_custom_queries = < Activar con 1 para habilitar el uso de consultas personalizadas >
analyze_connections = < Activar con 1 para habilitar la monitorización de conexiones >
engine_uptime = < Activar con 1 para habilitar la monitorización del tiempo en ejecución >
query_stats = < Activar con 1 para habilitar la monitorización de estadísticas de consultas >
monitor_long_queries = < Activar con 1 para habilitar la monitorización de estadísticas de long queries >
monitor_latch_requests = < Activar con 1 para habilitar la monitorización de estadísticas de latch requests >
monitor_full_scans = < Activar con 1 para habilitar la monitorización de estadísticas de scans >
count_databases = < Activar con 1 para habilitar el conteo de bases de datos >
retrieve_memory_statistics = < Activar con 1 para habilitar la monitorización de estadísticas de memoria >
retrieve_locks_statistics = < Activar con 1 para habilitar la monitorización de estadísticas de locks >
check_engine_performance = < Activar con 1 para habilitar la monitorización de estadísticas de rendimiento >
retrieve_buffer_statistics = < Activar con 1 para habilitar la monitorización de estadísticas de buffer >
retrieve_users_information = < Activar con 1 para habilitar la monitorización de estadísticas de users >
retrieve_cluster_state = < Activar con 1 para habilitar la monitorización de estadísticas de cluster >
retrieve_logs_statistics = < Activar con 1 para habilitar la monitorización de estadísticas de logs >
monitor_active_users = < Activar con 1 para habilitar la monitorización de estadísticas de usuarios activos >
retrieve_transactions_statistics = < Activar con 1 para habilitar la monitorización de estadísticas de transaccion >
monitor_filegroups_space = < Activar con 1 para habilitar la monitorización de estadísticas de espacio de grupos >
monitor_user_reserved_space = < Activar con 1 para habilitar la monitorización de estadísticas de espacio reservado >
monitor_backups = < Activar con 1 para habilitar la monitorización de estadísticas de backups >
agent_per_database = < Activar con 1 para habilitar la creación de agentes para cada base de datos >
db_agent_prefix = < Prefijo para las bases de datos >
scan_databases = < Activar con 1 para habilitar la monitorización de bases de datos >
[MODULE_NAMES]
database_size = < Nombre del modulo, por defecto : database_size >
database_usage = < Nombre del modulo, por defecto : database_usage >
restart_detection = < Nombre del modulo, por defecto : restart detection >
queries = < Nombre del modulo, por defecto : queries >
insert = < Nombre del modulo, por defecto : insert >
delete = < Nombre del modulo, por defecto : delete >
update = < Nombre del modulo, por defecto : update >
session_usage = < Nombre del modulo, por defecto : session usage >
database_count = < Nombre del modulo, por defecto : database_count >
server_startup = < Nombre del modulo, por defecto : server_startup >
lock_memory = < Nombre del modulo, por defecto : lock_memory >
connection_memory = < Nombre del modulo, por defecto : connection_memory >
optimizer_memory = < Nombre del modulo, por defecto : optimizer_memory >
sqlcache_memory = < Nombre del modulo, por defecto : sqlcache_memory >
total_memory = < Nombre del modulo, por defecto : total_memory >
deadlocks = < Nombre del modulo, por defecto : deadlocks >
lock_timeouts = < Nombre del modulo, por defecto : lock_timeouts >
lock_requests = < Nombre del modulo, por defecto : lock_requests >
lock_waits = < Nombre del modulo, por defecto : lock_waits >
buf_cachehit_ratio = < Nombre del modulo, por defecto : buf_cachehit_ratio >
free_connections = < Nombre del modulo, por defecto : free_connections >
page_reads = < Nombre del modulo, por defecto : page_reads >
page_writes = < Nombre del modulo, por defecto : page_writes >
latch_waits = < Nombre del modulo, por defecto : latch_waits >
full_scans = < Nombre del modulo, por defecto : full_scans >
locks_used = < Nombre del modulo, por defecto : locks_used >
workspace_memory = < Nombre del modulo, por defecto : workspace_memory >
average_waittime = < Nombre del modulo, por defecto : average_waittime >
server_cpu = < Nombre del modulo, por defecto : server_cpu >
server_io = < Nombre del modulo, por defecto : server_io >
active_connection_ratio = < Nombre del modulo, por defecto : active_connection_ratio >
locked_users = < Nombre del modulo, por defecto : locked_users >
blocked_users = < Nombre del modulo, por defecto : blocked_users >
active_users = < Nombre del modulo, por defecto : active_users >
long_queries = < Nombre del modulo, por defecto : long_queries >
long_queries_string = < Nombre del modulo, por defecto : long_queries_string >
aag_cluster_quorum_state = < Nombre del modulo, por defecto : aag_cluster_quorum_state >
aag_cluster_members_state = < Nombre del modulo, por defecto : aag_cluster_members_state >
aag_synchronization_health = < Nombre del modulo, por defecto : aag_synchronization_health >
aag_replica_synchronization_health = < Nombre del modulo, por defecto : aag_replica_synchronization_health >
aag_replica_connected_state = < Nombre del modulo, por defecto : aag_replica_connected_state >
aag_replica_recovery_health = < Nombre del modulo, por defecto : aag_replica_recovery_health >
aag_replica_operational_state = < Nombre del modulo, por defecto : aag_replica_operational_state >
aag_db_replica_synchronization_state = < Nombre del modulo, por defecto : aag_db_replica_synchronization_state >
aag_listener_state = < Nombre del modulo, por defecto : aag_listener_state >
availability = < Nombre del modulo, por defecto : availability >
state = < Nombre del modulo, por defecto : state >
db_active_users = < Nombre del modulo, por defecto : active users >
transactions = < Nombre del modulo, por defecto : transactions >
active_transactions = < Nombre del modulo, por defecto : active_transactions >
log_flush_waits = < Nombre del modulo, por defecto : log_flush_waits >
log_file_growths = < Nombre del modulo, por defecto : log_file_growths >
log_file_shrinks = < Nombre del modulo, por defecto : log_file_shrinks >
logfile_size = < Nombre del modulo, por defecto : logfile_size >
logfile_usage = < Nombre del modulo, por defecto : logfile_usage >
log_cachehit_ratio = < Nombre del modulo, por defecto : log_cachehit_ratio >
backup_status_minutes = < Nombre del modulo, por defecto : backup_status_minutes >
backup_status_last_backup = < Nombre del modulo, por defecto : backup_status_last_backup >
fg_free_space = < Nombre del modulo, por defecto : fg_free_space >
Ejemplo
[CONF]
agents_group_id = 10
interval = 300
user = sa
password = HHgD85V@
threads = 1
modules_prefix =
entities_list= /tmp/mssql_entities_list.txt
execute_custom_queries = 1
analyze_connections = 1
engine_uptime = 1
query_stats = 1
monitor_long_queries = 1
monitor_latch_requests = 1
monitor_full_scans = 1
count_databases = 1
retrieve_memory_statistics = 1
retrieve_locks_statistics = 1
check_engine_performance = 1
retrieve_buffer_statistics = 1
retrieve_users_information = 1
retrieve_cluster_state = 1
retrieve_logs_statistics = 1
monitor_active_users = 1
retrieve_transactions_statistics = 1
monitor_filegroups_space = 1
monitor_user_reserved_space = 1
monitor_backups = 1
agent_per_database = 1
db_agent_prefix = PANDORA-
scan_databases = 1
[MODULE_NAMES]
database_size = database_size
database_usage = database_usage
restart_detection = restart detection
queries = queries
insert = insert
delete = delete
update = update
session_usage = session usage
database_count = database_count
server_startup = server_startup
lock_memory = lock_memory
connection_memory = connection_memory
optimizer_memory = optimizer_memory
sqlcache_memory = sqlcache_memory
total_memory = total_memory
deadlocks = deadlocks
lock_timeouts = lock_timeouts
lock_requests = lock_requests
lock_waits = lock_waits
buf_cachehit_ratio = buf_cachehit_ratio
free_connections = free_connections
page_reads = page_reads
page_writes = page_writes
latch_waits = latch_waits
full_scans = full_scans
locks_used = locks_used
workspace_memory = workspace_memory
average_waittime = average_waittime
server_cpu = server_cpu
server_io = server_io
active_connection_ratio = active_connection_ratio
locked_users = locked_users
blocked_users = blocked_users
active_users = active_users
long_queries = long_queries
long_queries_string = long_queries_string
aag_cluster_quorum_state = aag_cluster_quorum_state
aag_cluster_members_state = aag_cluster_members_state
aag_synchronization_health = aag_synchronization_health
aag_replica_synchronization_health = aag_replica_synchronization_health
aag_replica_connected_state = aag_replica_connected_state
aag_replica_recovery_health = aag_replica_recovery_health
aag_replica_operational_state = aag_replica_operational_state
aag_db_replica_synchronization_state = aag_db_replica_synchronization_state
aag_listener_state = aag_listener_state
availability = availability
state = state
db_active_users = active users
transactions = transactions
active_transactions = active_transactions
log_flush_waits = log_flush_waits
log_file_growths = log_file_growths
log_file_shrinks = log_file_shrinks
logfile_size = logfile_size
logfile_usage = logfile_usage
log_cachehit_ratio = log_cachehit_ratio
backup_status_minutes = backup_status_minutes
backup_status_last_backup = backup_status_last_backup
fg_free_space = fg_free_spaceListado de bases de datos objetivo (--target_databases)
El contenido del fichero será un listado de instancias objetivo, separando cada base de datos por comas o por líneas. El formato para una base de datos podrá ser cualquiera de los siguientes:
ip
ip:puerto
ip\instanciaEjemplo
172.17.0.4:1433\DEVENV
172.17.0.2:1433\PRODENVSi se especifícan de esta manera, se monitorizarán todas las bases de datos de cada instancia.
Si que quiere monitorizar bases concretas de una instancia, se deben especificar con "|" y separando cada base de datos con ";".
Ejemplo :
172.17.0.4:1433\DEVENV|pandora;testing;modelSi se quiere monitorizar todas las bases de datos de una instancia, pero descartar algunas, se debe especificar "!" antes del "|".
Ejemplo:
172.17.0.4:1433\DEVENV!|pandora;testing;modelListado de agentes objetivo (--target_agents)
El contenido del fichero será un listado de bases de nombres de agentes, separando cada agente por comas o por líneas. Estos nombres de agentes se usarán para volcar la información de cada base de datos objetivo en el nombre de agente indicado correspondiente, en lugar de dejar que el plugin genere los nombres de agentes de forma automática.
La posición de cada nombre de agente en el listado debe coincidir con la posición de la base de datos objetivo en su propio listado, es decir, el nombre para la primera base de datos objetivo será el primer nombre de este listado, teniendo en cuenta que las líneas en blanco son ignoradas.
Ejemplo
agente1,,agente3
agente4
agente5,agente6,agente7,,agente9Consultas personalizadas (--custom_queries)
Se debe introducir un módulo por cada consulta personalizada que se pretenda monitorizar. Los módulos deben seguir una estructura, que es la siguiente:
check_begin --> Etiqueta de abertura del módulo
name --> Nombre del módulo
description --> Descripción del módulo.
operation --> Tipo de operación
datatype --> Tipo de módulo
min_warning --> Configuración del umbral mínimo de warning
max_warning --> Configuración del umbral máximo de warning
str_warning --> Configuración de string de warning
warning_inverse --> Activar el intervalo inverso con 1 para umbral de warning
min_critical --> Configuración del umbral mínimo de critical
max_critical --> Configuración del umbral máximo de critical
str_critical --> Configuración de string de critical
critical_inverse --> Activar el intervalo inverso con 1 para umbral de crítico
module_interval --> Este intervalo se calcula como un multiplicador del intervalo del agente.
target --> Consulta personalizada
target_databases --> Agentes de instancias en los que se creará el módulo, o nombre de de base de datos en las que se creara el módulo. Si se quiere aplicar a todos los elementos, se puede especificar: All o no especificarse directamente.
target_scope --> Elemento de destino al que se aplicará la consulta personalizada, puede ser: instances o databases. Si no se especifica se aplicara tanto a instancias como a bases de datos.
ignore_databases --> Agentes de instancias en los que no se creara el módulo o nombres de bases de datos en los que no se creará el módulo.
check_end --> Etiqueta de cierre del móduloEjemplo
check_begin
name Select 1
description Number of invalid objects
operation value
datatype generic_data
min_warning 5
target SELECT 1;
target_databases all
check_end
check_begin
name NumeroConexiones
description Number of connections
operation value
datatype generic_data
min_warning 10
target SELECT COUNT(*) AS NumeroConexiones FROM sys.dm_exec_sessions WHERE is_user_process = 1;
target_databases all
target_scope databases
ignore_databases master
check_end
check_begin
name lista_table_size.MB
description table size in MB
operation full
datatype generic_data
target SELECT SUM(reserved_page_count) * 8 / 1024.0 AS TamañoMB FROM sys.dm_db_partition_stats WHERE object_id = OBJECT_ID('lista');
target_databases pandora
check_endEjecución manual
El formato de la ejecución del plugin es el siguiente:
./pandora_mssql \
--conf < ruta al fichero de configuración > \
--target_databases < ruta al fichero de configuración que contiene las bases de datos objetivo > \
[ --target_agents < ruta al fichero de configuración de agentes > ] \
[ --custom_queries < ruta al fichero de configuración que contiene las consultas personalizas > ]Por ejemplo:
./pandora_mssql \
--conf /usr/share/pandora_server/util/plugin/mssql.conf \
--target_databases /usr/share/pandora_server/util/plugin/targets.conf \
--target_agents /usr/share/pandora_server/util/plugin/target_agents.conf \
--custom_queries /usr/share/pandora_server/util/plugin/custom_queries.confDiscovery
Este plugin puede integrarse con el Discovery de Pandora FMS.
Para ello se debe cargar el paquete ".disco" que puede descargar desde la librería de Pandora FMS:
https://pandorafms.com/library/mssql-discovery/
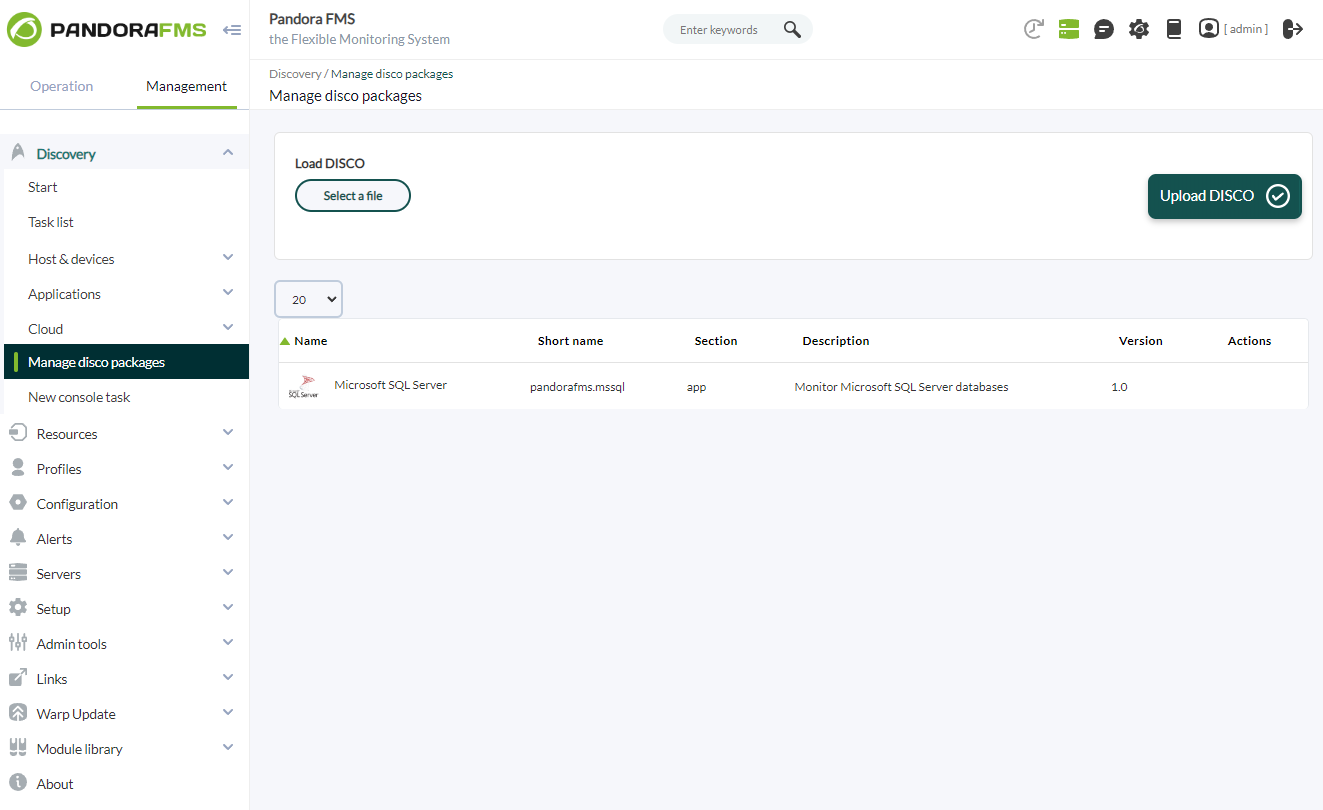
Una vez cargado, se podrán monitorizar entornos de Microsoft SQL Server creando tareas de Discovery desde la sección Management > Discovery > Applications.
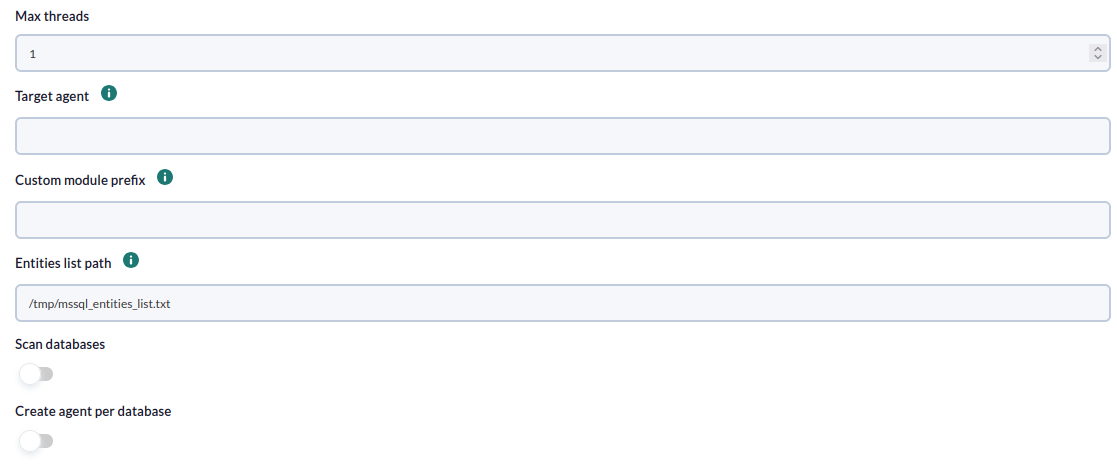
Para cada tarea se solicitarán los siguientes datos mínimos:
- Microsoft SQL Server target string: Lista de objetivos Microsoft SQL Server a monitorizar por la tarea. Será una lista separada por comas o por líneas. Cada instancia de base de datos objetivo se podrá definir con el formato IP:PUERTO\INSTANCIA, IP:PUERTO, IP\INSTANCIA o IP.
Si que quiere monitorizar bases concretas de una instancia, se deben especificar con "|" y separando cada base de datos con ";".
Ejemplo :
172.17.0.4:1433\DEVENV|pandora;testing;modelSi se quiere monitorizar todas las bases de datos de una instancia, pero descartar algunas, se debe especificar "!" antes del "|".
Ejemplo:172.17.0.4:1433\DEVENV!|pandora;testing;model - User: Usuario de conexión a las bases de datos objetivo.
- Password: Contraseña del usuario indicado.

También se podrá ajustar la configuración de la tarea para personalizar la monitorización deseada:
- Max threads: Para optimizar el tiempo de ejecución, se podrán configurar múltiples hilos para monitorizar los agentes de la tarea. Hay que tener en cuenta que configurar múltiples hilos puede aumentar el uso de CPU de la tarea.
- Target agent: Lista de agentes objetivo para los objetivos Microsoft SQL Server a monitorizar. Es decir, los nombres con los que se generarán los agentes de cada objetivo definido en la tarea. Será una lista separada por comas o por líneas. La posición de los nombres en la lista deberá coincidir con la posición de los objetivos Microsoft SQL Server en su lista, es decir, el primer nombre se usará para el primer objetivo y así sucesivamente. Si la lista se separa por líneas, las líneas en blanco se ignorarán. Si no se especifica un nombre de agente para un objetivo se usará su IP o FQDN como nombre del agente.
- Custom module prefix: Texto incluido como prefijo para los todos los nombres de módulos generados. Es útil para localizar los módulos generados por la tarea o distinguirlos de otros.
- Entities list path : Ruta del fichero de entities, por defecto : "/tmp/mssql_entities_list.txt". No se debe usar el mismo que ya exista para otra tarea.
- Scan databases: Activar para monitorizar las bases de datos de las instancias.
- Create agent per database: Activar para crear un agente por cada base de datos monitorizada.
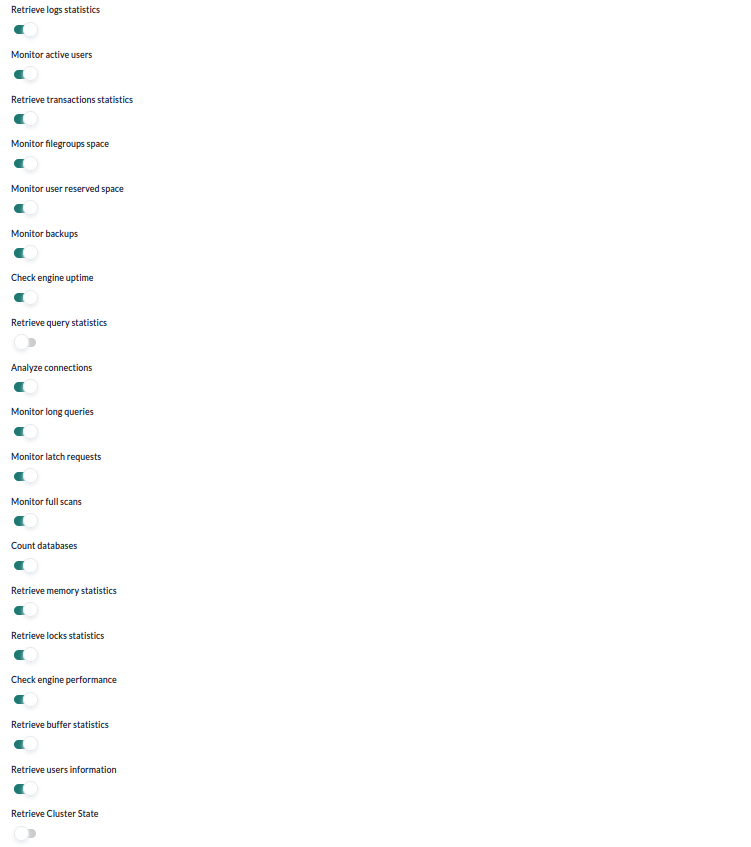
-
Retrieve logs statistics: Si se activa monitorizará las estadísticas de logs.
-
Monitor active users: Si se activa monitorizará los usuarios activos.
-
Retrieve transactions statistics: Si se activa monitorizará las estadísticas de transacciones.
-
Monitor filegroups space: Si se activa monitorizará el espacio de los filegroups.
-
Monitor user reserved space: Si se activa monitorizará el espacio reservado por los usuarios.
-
Monitor backups: Si se activa monitorizará el estado de los backups.
-
Check engine uptime: Si se activa monitorizará el uptime del motor/instancia.
-
Retrieve query statistics: Si se activa monitorizará las estadísticas de consultas.
-
Analyze connections: Si se activa monitorizará las conexiones.
-
Monitor long queries: Si se activa monitorizará las consultas de larga duración.
-
Monitor latch requests: Si se activa monitorizará las solicitudes de latch.
-
Monitor full scans: Si se activa monitorizará los full scans ejecutados.
-
Count databases: Si se activa monitorizará el número de bases de datos.
-
Retrieve memory statistics: Si se activa monitorizará las estadísticas de memoria.
-
Retrieve locks statistics: Si se activa monitorizará las estadísticas de bloqueos.
-
Check engine performance: Si se activa monitorizará el rendimiento del motor/instancia.
-
Retrieve buffer statistics: Si se activa monitorizará las estadísticas de buffer.
-
Retrieve users information: Si se activa monitorizará la información de los usuarios.
-
Retrieve Cluster State: Si se activa monitorizará el estado del clúster.
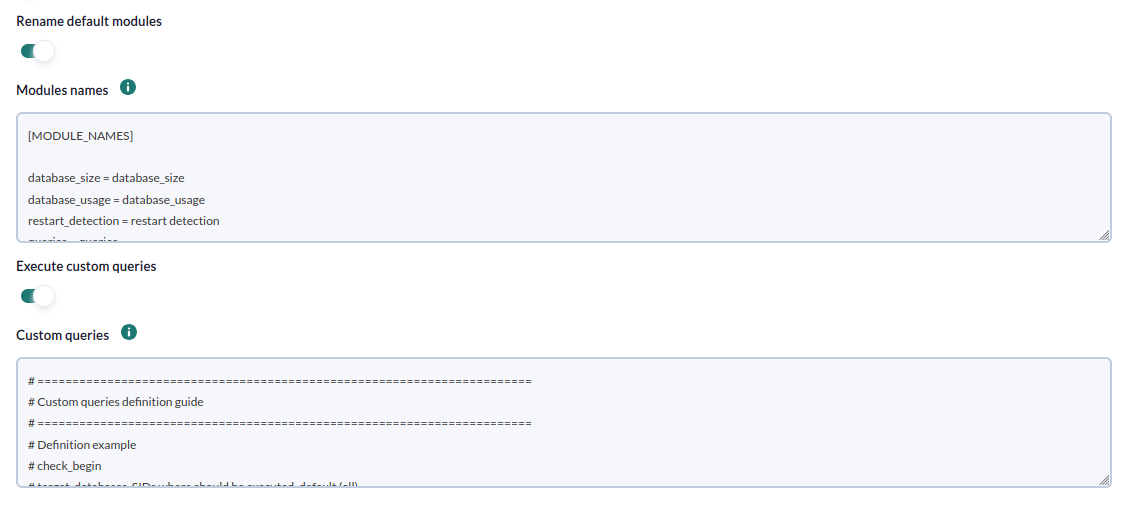
- Rename default modules: Si se activa permitirá cambiar el nombre de los módulos que vienen por defecto.
- Modules names: Bloque de configuración para definir el nombre de los módulos que vienen por defecto.
- Execute custom queries: Si se activa permitirá ejecutar consultas personalizadas a cada objetivo Microsoft SQL Server.
- Custom queries: Bloque de configuración para definir las consultas personalizadas que se ejecutarán. Cada consulta generará un nuevo módulo para cada agente de la tarea.
Las tareas que se completen exitosamente dispondrán de un sumario de ejecución con la siguiente información:
- Total agents: Total de agentes generados por la tarea.
- Targets up: Total de objetivos a los que ha sido posible conectar.
- Targets down: Total de objetivos a los que no ha sido posible conectar.

Las tareas que no se completen exitosamente dispondrán de un sumario de ejecución registrando los errores producidos.
Agentes y módulos generados por el plugin
El plugin creará un agente por cada base de datos objetivo. Ese agente contendrá los siguientes módulos
Métricas de instancia
|
server_startup
|
Supervisa el tiempo de actividad (en días) del servidor de base de datos |
|
locks_used
|
Supervisa el porcentaje de bloqueos utilizados y de propietarios de bloqueos |
|
workspace_memory
|
Supervisa la cantidad de memoria que se utiliza para ejecutar procesos como operaciones hash, de clasificación, de copia masiva y de creación de índices. |
|
average_waittime
|
Tiempo medio de espera de bloqueo de SQL Server |
Si esta activado engine_uptime:
| restart_detection | Será 0 si se ha detectado un reinicio inesperado, y 1 de no ser este el caso. Cuando un servidor se reinicia inesperadamente, puede haber una interrupción en el acceso a la base de datos y potencialmente se pueden perder transacciones o datos no guardados correctamente. |
Si esta activado query_stats:
| queries | Número de consultas totales. Monitorizar las consultas es esencial para comprender la carga de trabajo que se está ejecutando en el servidor y evaluar el rendimiento general del sistema. Al supervisar el número total de consultas, puedes identificar picos de actividad, optimizar el rendimiento y detectar posibles problemas, como consultas ineficientes o excesivas. |
| update | Número de consultas UPDATE. Las consultas UPDATE se utilizan para modificar los datos existentes en la base de datos. Monitorizar las consultas UPDATE es importante para evaluar la frecuencia y la eficiencia de las actualizaciones de datos. Puedes identificar consultas UPDATE que afectan a un gran número de filas o que tienen un impacto significativo en el rendimiento del servidor. Esto te permite optimizar las consultas, revisar la estructura de las tablas o tomar medidas para reducir la carga generada por las actualizaciones. |
| delete | Número de consultas DELETE. Las consultas DELETE se utilizan para eliminar datos de la base de datos. Monitorizar las consultas DELETE es útil para evaluar la frecuencia y la eficiencia de las eliminaciones de datos. Puedes identificar consultas DELETE que afectan a un gran número de filas o que tienen un impacto significativo en el rendimiento del servidor. Esto te permite optimizar las consultas, revisar la estructura de las tablas o tomar medidas para reducir la carga generada por las eliminaciones. |
| insert | Número de consultas INSERT. Las consultas INSERT se utilizan para insertar nuevos datos en la base de datos. Monitorizar las consultas INSERT te permite evaluar la frecuencia y la eficiencia de las inserciones de datos. Puedes identificar consultas INSERT que están generando una alta carga en el servidor o que podrían estar causando problemas de rendimiento. Esto te permite optimizar las consultas, revisar la estructura de las tablas o considerar estrategias de inserción diferida para mejorar el rendimiento en entornos de alta concurrencia. |
Si esta activado analyze_connections:
| session usage | Número de conexiones actuales respecto al total de conexiones máximas. La monitorización del uso de sesiones en SQL Server es importante para optimizar el rendimiento, identificar problemas de bloqueo, mejorar la seguridad y auditoría, y planificar eficientemente los recursos del servidor. |
Si esta activado retrieve_memory_statistics:
|
lock_memory
|
Controla la cantidad de memoria de bloqueo asignada en Bytes |
|
connection_memory
|
Controla la cantidad de memoria de conexión en Bytes |
|
optimizer_memory
|
Monitoriza la cantidad de memoria del optimizador en Bytes |
|
sqlcache_memory
|
Monitoriza la cantidad de memoria caché SQL en Bytes |
|
total_memory
|
Monitoriza la cantidad total de memoria dinámica del servidor en Bytes |
Si esta activado retrieve_locks_statistics:
|
deacklocks
|
Supervisa el número de bloqueos por segundo |
|
lock_timeouts
|
Controlar el número de bloqueos por segundo |
|
lock_requests
|
Controlar el número de solicitudes de bloqueo por segundo |
|
lock_waits
|
Controlar el número de bloqueos por segundo |
Si esta activado retrieve_buffer_statistics:
|
buf_cachehit_ratio
|
Porcentaje de páginas encontradas en la memoria caché sin tener que leer del disco |
|
free_connections
|
Supervisa el % de conexiones libres a la instancia de SQL Server |
|
page_reads
|
Supervisa el número de lecturas de páginas de base de datos por segundo |
|
page_writes
|
Supervisa el número de escrituras de páginas de base de datos por segundo. |
Si esta activado monitor_latch_requests:
|
latch_waits
|
Controla el número de peticiones de latch por segundo |
Si esta activado monitor_full_scans:
|
full_scans
|
Supervisa el número de exploraciones completas (tabla o índice) por segundo. |
Si esta activado check_engine_performance:
|
server_cpu
|
Monitoriza el % de uso de CPU por instancia de SQL Server |
|
io_busy
|
Monitoriza el % de I/O ocupado para la instancia SQL Server |
|
server_io
|
Monitoriza el % de I/O ocupado para la instancia SQL Server |
Si esta activado retrieve_users_information:
|
active_connection_ratio
|
Supervisa la relación entre las conexiones activas y el total de conexiones permitidas. |
|
locked_users
|
Controla el número de usuarios suspendidos por bloqueos |
|
blocked_users
|
Controla el número de usuarios suspendidos por bloqueos |
|
active_users
|
Supervisa el número de usuarios que han iniciado sesión en el servidor. |
Si esta activado monitor_long_queries:
|
long_queries
|
Supervisa las consultas de larga duración (en segundos) |
|
long_queries_string
|
Salida completa de consultas de larga duración |
Si esta activado retrieve_cluster_state:
|
aag_cluster_quorum_state
|
Estado: < descripción >. Supervisa el estado de quórum del WSFC AlwaysOn. |
|
aag_cluster_members_state
|
Estado: < descripción >. Monitoriza el estado de los nodos WSFC AlwaysOn |
|
aag_synchronization_health
|
Estado: <descripción >. Supervisa el estado de sincronización de un grupo de disponibilidad. |
|
aag_replica_synchronization_health
|
Estado: < descripción >. Rol: < rol > . Monitoriza la salud de sincronización de una réplica de disponibilidad. |
|
aag_replica_connected_state
|
Estado: < descripción > Role: < rol > Supervisa el estado conectado de una réplica de disponibilidad. |
|
aag_replica_recovery_health
|
Estado:< descripción >. Rol: < rol >. Monitoriza la salud de recuperación de una réplica de disponibilidad. |
|
aag_replica_operational_state
|
Estado: < estado >. Rol: < rol >. Supervisa el Estado operativo actual de la réplica de disponibilidad. |
|
aag_db_replica_synchronization_state
|
Estado: < descripción >. Supervisa el estado de sincronización de las bases de datos en la réplica de disponibilidad. |
|
aag_listener_state
|
Estado: < desc >. Rol: < rol >. Supervisar el estado de escucha de grupo de disponibilidad AlwaysOn |
Metricas de base de datos
Si monitor_active_users esta activado :
|
active users
|
Supervisa el número de transacciones de usuario activas por base de datos. |
Si retrieve_transactions_statistics esta activado:
|
transactions
|
Controla el número de transacciones por segundo |
|
active transactions
|
Transacciones activas |
Si retrieve_logs_statistics esta activado:
|
log_flush_waits
|
Supervisa el número de esperas de descarga de registro por segundo. |
|
log_file_growths
|
Supervisa el uso (crecimiento) de los registros de transacciones. |
|
log_file_shrinks
|
Supervisa el uso (reducción) de los registros de transacciones. |
|
logfile_size
|
Supervisa el tamaño del archivo de registro |
|
logfile_usage
|
Monitors free space in log files |
Si monitor_backups esta activado:
|
backup_status_minutes
|
Controla el número de minutos transcurridos desde la última copia de seguridad |
|
backup_status_last_backup
|
Controla cuándo se hizo la última copia de seguridad |
Si monitor_filegroups_space esta activado:
|
fg_free_space
|
Supervisa el espacio libre en los grupos de archivos |
Si monitor_user_reserved_space esta activado:
|
Monitors reserved space in user tables
|
Supervisa el espacio reservado en las tablas de usuario |
|
Monitors reserved space free data % in user tables
|
Supervisa el % de datos libres de espacio reservado en las tablas de usuario |
El plugin también creará un módulo por cada consulta personalizada definida en el fichero de configuración.