# PostgreSQL
# Introducción
**Este plugin tiene como finalidad monitorizar bases de datos PostgreSQL**, mediante consultas que extraerán información sobre datos que son claves para conocer el rendimiento y estado de la bases de datos, como son el número de conexiones, número de consultas , estado de los reinicios, ratio de fragmentación y cache. Estos datos se verán reflejados en PandoraFMS, en módulos que aportaran el valor estadístico, dentro de un agente que representará a cada base de datos.
Este plugin está desarrollado para usarse con Pandora FMS Discovery, por lo que a diferencia de otros plugins no genera agentes por XML, si no que todo lo descubierto se devuelve en la salida JSON del plugin.
# Prerrequisitos
Este plugin realiza conexiones remotas a las bases de datos a monitorizar, por lo que es necesario asegurar la conectividad entre el servidor de Pandora FMS y dichas bases de datos.
# Parámetros y configuración
**Parámetros**
| --conf | Ruta al archivo de configuración |
| --target\\\_databases | Ruta al archivo de configuración que contiene los targets de las bases de datos |
| --target\\\_agents | Ruta al archivo de configuración que contiene los targets de los agentes |
| --custom\\\_queries | Ruta al archivo de configuración que contiene las consultas personalizadas |
**Archivo de configuración (--conf)**
```
agents_group_id = < ID del grupo en el que se crearán los agentes >
interval = < Intervalo de monitorización de los agentes en segundos >
user = < Usuario de conexión >
password = < Contraseña >
threads = < Número de hilos que se usaran para la creación de agentes >
modules_prefix = < Prefijo de módulos >
execute_custom_queries = < Activar con 1 para habilitar el uso de consultas personalizadas >
analyze_connections = < Activar con 1 para habilitar la monitorización de conexiones >
engine_uptime = < Activar con 1 para habilitar la monitorización del tiempo en ejecución >
query_stats = < Activar con 1 para habilitar la moitorización de estadísticas de consultas >
fragmentation_ratio = < Activar con 1 para habilitar la monitorización de estadísticas de ratio de fragmentación >
cache_stats = < Activar con 1 para habilitar la monitorización de estadísticas de cache >
scan_databases = < Activar con 1 para descubrir las bases de datos del objetivo PostgreSQL >
agent_per_database = < Activar con 1 para crear un agente independiente por cada base de datos descubierta >
db_agent_prefix = < Prefijo para los nombres de los agentes individuales de cada base de datos >
entities_list = < Ruta al fichero persistente de entidades descubiertas >
enable_entities_interval = < Activar con 1 para habilitar la revalidación periódica del fichero de entidades >
entities_interval = < Intervalo de revalidación del fichero de entidades en segundos >
check_storage_stats = < Activar con 1 para habilitar estadísticas de almacenamiento de las bases de datos >
check_query_performance = < Activar con 1 para habilitar estadísticas de rendimiento de consultas >
check_connection_stats = < Activar con 1 para habilitar estadísticas de conexiones por base de datos >
check_transaction_stats = < Activar con 1 para habilitar estadísticas de actividad transaccional >
check_table_stats = < Activar con 1 para habilitar estadísticas estructurales de tablas >
check_advanced_perf = < Activar con 1 para habilitar métricas avanzadas de rendimiento >
```
**Nota**: También es posible proporcionar las credenciales mediante el token `credentials` en formato JSON codificado en Base64 (mismo formato que las credenciales de tipo *Custom* del *Credential store* de Pandora FMS). Si está definido tiene prioridad sobre `user` y `password`.
```
credentials = < JSON codificado en Base64 con los campos "user" y "password" >
```
Ejemplo
```
agents_group_id = 10
interval = 300
user = sa
password = HHgD85V@
threads = 1
modules_prefix =
execute_custom_queries = 1
analyze_connections = 1
engine_uptime = 1
query_stats = 1
fragmentation_ratio = 1
cache_stats = 1
scan_databases = 1
agent_per_database = 1
db_agent_prefix =
entities_list = /tmp/postgresql_entities_list.txt
enable_entities_interval = 1
entities_interval = 300
check_storage_stats = 1
check_query_performance = 1
check_connection_stats = 1
check_transaction_stats = 1
check_table_stats = 1
check_advanced_perf = 1
```
**Listado de bases de datos objetivo (--target\_databases)**
El contenido del fichero será un listado de objetivos PostgreSQL separados por comas o por líneas. Las líneas en blanco y las que comiencen por `#` se ignoran. Para cada objetivo se admiten los siguientes formatos:
- `IP:PUERTO\BASE` — Monitorizar únicamente la base de datos indicada.
- `IP:PUERTO|db1;db2;db3` — Monitorizar varias bases de datos concretas del objetivo.
- `IP:PUERTO!|db1;db2` — Excluir las bases de datos indicadas (requiere que `scan_databases` esté activo).
- `IP:PUERTO` — Si `scan_databases` está activo, se descubrirán todas las bases de datos del objetivo; en caso contrario solo se monitorizará la instancia.
Ejemplo
```
172.17.0.3:5432\postgres
172.17.0.4:5432|pandora;metadatos
172.17.0.5:5432!|template0;template1
# Esta línea es un comentario y será ignorada
172.17.0.6:5432
```
**Listado de agentes objetivo (--target\_agents)**
El contenido del fichero será un listado de bases de nombres de agentes, separando cada agente por comas o por líneas. Estos nombres de agentes se usarán para volcar la información de cada base de datos objetivo en el nombre de agente indicado correspondiente, en lugar de dejar que el plugin genere los nombres de agentes de forma automática.
La posición de cada nombre de agente en el listado debe coincidir con la posición de la base de datos objetivo en su propio listado, es decir, el nombre para la primera base de datos objetivo será el primer nombre de este listado, teniendo en cuenta que las líneas en blanco son ignoradas.
Ejemplo
```
agente1,,agente3
agente4
agente5,agente6,agente7,,agente9
```
**Consultas personalizadas (--custom\_queries)**
Se debe introducir un módulo por cada consulta personalizada que se pretenda monitorizar. Los módulos deben seguir una estructura, que es la siguiente:
```
check_begin --> Etiqueta de abertura del módulo
name --> Nombre del módulo
description --> Descripción del módulo.
operation --> Tipo de operación
datatype --> Tipo de módulo
min_warning --> Configuración del umbral mínimo de warning
max_warning --> Configuración del umbral máximo de warning
str_warning --> Configuración de string de warning
warning_inverse --> Activar el intervalo inverso con 1 para umbral de warning
min_critical --> Configuración del umbral mínimo de critical
max_critical --> Configuración del umbral máximo de critical
str_critical --> Configuración de string de critical
critical_inverse --> Activar el intervalo inverso con 1 para umbral de crítico
module_interval --> Este intervalo se calcula como un multiplicador del intervalo del agente.
target --> Consulta personalizada
target_databases --> Agentes de bases de datos en los que se creará el módulo
target_scope --> Ámbito de aplicación: "instances" (solo instancia), "databases" (solo bases de datos) o "all" (por defecto)
check_end --> Etiqueta de cierre del módulo
```
**Notas importantes sobre las consultas personalizadas:**
- Solo se permiten consultas `SELECT`. Cualquier otra consulta será descartada con un aviso en la salida del plugin.
- La palabra reservada `$__self_dbname` será sustituida por el nombre de la base de datos en la que se esté ejecutando la consulta (o `postgres` si se ejecuta a nivel de instancia). Puede usarse tanto en el `target` como en el `name`.
- Se acepta también `sql` como sinónimo de `target`.
- Si no se especifica `target_scope` se asumirá `all` (compatible con versiones anteriores).
- Si no se especifica `target_databases` se asumirá `all` (compatible con versiones anteriores).
- El `name` resultante de la sustitución de `$__self_dbname` se completará con el prefijo del módulo (`modules_prefix`) y, si corresponde, con el nombre de la base de datos.
Ejemplo
```
check_begin
name Select 1
description Number of invalid objects
operation value
datatype generic_data
min_warning 5
target SELECT 1 FROM dual
target_databases all
check_end
check_begin
name NumeroConexiones
description Number of connections
operation value
datatype generic_data
min_warning 5
target SELECT COUNT(*) AS NumeroConexiones FROM pg_stat_activity
target_databases pandora
target_scope databases
check_end
check_begin
name $__self_dbname.files_table
description Invalid objects (detail)
operation full
datatype generic_data
target SELECT COUNT(*) AS NumeroRegistros FROM files
target_databases pandora
check_end
```
# Ejecución manual
El formato de la ejecución del plugin es el siguiente:
```shell
./pandora_postgresql \
--conf < ruta al fichero de configuración > \
--target_databases < ruta al fichero de configuración que contiene las bases de datos objetivo > \
[ --target_agents < ruta al fichero de configuración de agentes > ] \
[ --custom_queries < ruta al fichero de configuración que contiene las consultas personalizas > ]
```
Por ejemplo:
```shell
./pandora_postgresql \
--conf /usr/share/pandora_server/util/plugin/postgresql.conf \
--target_databases /usr/share/pandora_server/util/plugin/targets.conf \
--target_agents /usr/share/pandora_server/util/plugin/target_agents.conf \
--custom_queries /usr/share/pandora_server/util/plugin/custom_queries.conf
```
# Discovery
Este plugin puede integrarse con el *Discovery* de Pandora FMS.
Para ello se debe cargar el paquete ".disco" que puede descargar desde la librería de Pandora FMS:
[https://pandorafms.com/library/](https://pandorafms.com/library/)
[  ](https://pandorafms.com/guides/public/uploads/images/gallery/2026-05/disco.png)
Una vez cargado, se podrán monitorizar entornos de PostgreSQL creando tareas de *Discovery* desde la sección *Management > Discovery > Applications*.
Para cada tarea se solicitarán los siguientes datos mínimos:
- **PostgreSQL target strings**: Lista de objetivos PostgreSQL a monitorizar por la tarea. Será una lista separada por comas o por líneas. Cada objetivo PostgreSQL se podrá definir con el formato `IP:PUERTO` o `IP`, admitiendo también la selección o exclusión explícita de bases de datos (ver *Listado de bases de datos objetivo*).
- **PostgreSQL Credentials**: Credenciales de conexión de tipo *Custom*. Será necesario seleccionar una credencial previamente creada en *Management > Configuration > Credential store*.
[ 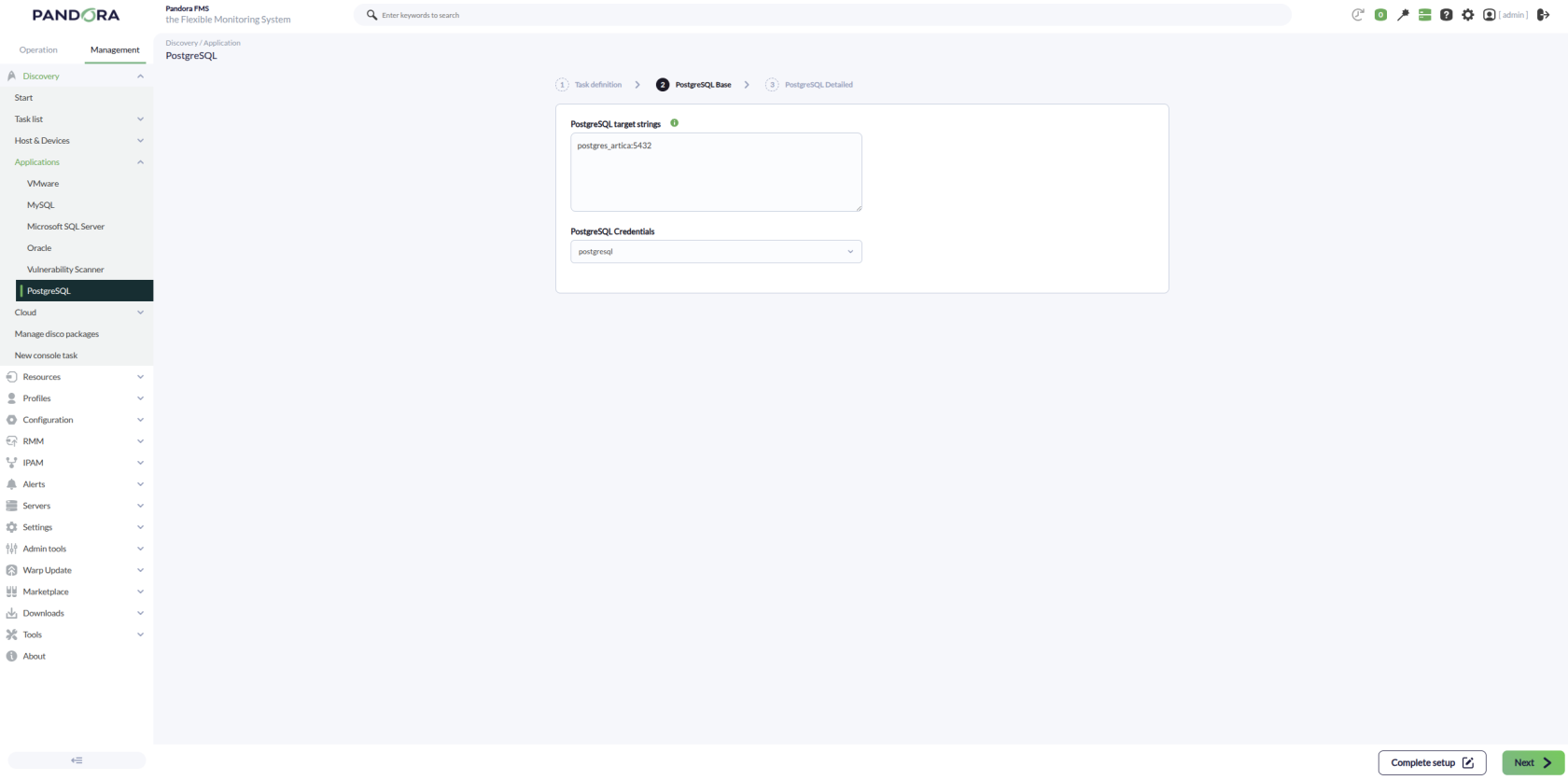 ](https://pandorafms.com/guides/public/uploads/images/gallery/2026-05/step2.png)
También se podrá ajustar la configuración de la tarea para personalizar la monitorización deseada:
- **Max threads**: Para optimizar el tiempo de ejecución, se podrán configurar múltiples hilos para monitorizar los agentes de la tarea. Hay que tener en cuenta que configurar múltiples hilos puede aumentar el uso de CPU de la tarea.
- **Target agent**: Lista de agentes objetivo para los objetivos PostgreSQL a monitorizar. Si no se especifica un nombre de agente para un objetivo se usará su IP o FQDN como nombre del agente.
- **Custom module prefix**: Texto incluido como prefijo para todos los nombres de módulos generados.
- **Scan databases**: Si se activa se descubrirán las distintas bases de datos de cada objetivo PostgreSQL.
- **Create agent per database**: Si se activa se creará un agente distinto para cada base de datos descubierta.
- **Custom database agent prefix**: Texto incluido como prefijo para los nombres generados para los agentes individuales de cada base de datos descubierta.
- **Enable entities file re-scan interval**: Si se activa se utilizará un fichero persistente de entidades descubiertas para comprobar bases de datos previamente detectadas aunque ya no aparezcan en el escaneo actual. De este modo, si una base de datos desaparece del escaneo, su módulo `connection` podrá pasar a estado crítico en lugar de quedar simplemente huérfano.
- **Re-scan entities file interval**: Intervalo de revalidación del fichero de entidades descubiertas.
- **Check engine uptime**: Si se activa monitorizará el uptime de los objetivos PostgreSQL.
- **Retrieve query statistics**: Si se activa monitorizará estadísticas de consultas a nivel de instancia:
- `queries`: Número de consultas activas dentro del intervalo configurado.
- `insert`: Número de consultas INSERT activas.
- `delete`: Número de consultas DELETE activas.
- `update`: Número de consultas UPDATE activas.
- **Analyze connections**: Si se activa monitorizará estadísticas de conexiones de la instancia:
- `session usage`: Porcentaje de uso de conexiones respecto al máximo configurado.
- **Calculate fragmentation ratio**: Si se activa monitorizará estadísticas de fragmentation ratio:
- `fragmentation ratio`: Ratio medio estimado de fragmentación.
- **Retrieve cache statistics**: Si se activa monitorizará estadísticas de caché de la instancia:
- `allocated buffer cache`: Total de buffers compartidos asignados.
- `backend used buffer cache`: Buffers utilizados por procesos backend.
- `checkpoints buffer cache`: Buffers escritos por checkpoints.
- `cleaned buffer cache`: Buffers limpiados por el writer.
- **Storage statistics**: Si se activa monitorizará estadísticas de almacenamiento de las bases de datos descubiertas:
- `database size`: Tamaño total de la base de datos.
- `tables size`: Tamaño total ocupado por las tablas.
- `indexes size`: Tamaño total ocupado por los índices.
- `temp bytes`: Cantidad de datos temporales escritos en disco.
- `temp files`: Número de ficheros temporales creados.
- **Query performance**: Si se activa monitorizará estadísticas de rendimiento de consultas:
- `long queries`: Número de consultas activas con duración superior al intervalo configurado.
- `oldest query age`: Tiempo de ejecución de la consulta activa más antigua.
- `sequential scans`: Número de escaneos secuenciales realizados.
- `index scans`: Número de escaneos realizados utilizando índices.
- `cache hit ratio`: Ratio de aciertos de caché de la base de datos.
- **Connections statistics**: Si se activa monitorizará estadísticas de conexiones por base de datos:
- `active connections`: Número de conexiones activas.
- `idle connections`: Número de conexiones inactivas.
- `total connections`: Número total de conexiones abiertas.
- **Transaction statistics**: Si se activa monitorizará estadísticas de actividad transaccional:
- `transactions`: Número total de transacciones ejecutadas.
- `commits`: Número de transacciones confirmadas.
- `rollbacks`: Número de transacciones revertidas.
- `rollback ratio`: Ratio de transacciones revertidas respecto al total.
- `deadlocks`: Número de deadlocks detectados.
- `conflicts`: Número de conflictos detectados en la base de datos.
- **Table statistics**: Si se activa monitorizará estadísticas estructurales de tablas:
- `table count`: Número total de tablas de usuario.
- `index count`: Número total de índices de usuario.
- `live tuples`: Número estimado de registros activos.
- `dead tuples`: Número estimado de registros obsoletos pendientes de limpieza.
- `fragmentation ratio`: Ratio medio estimado de fragmentación de tablas.
- **Advanced performance**: Si se activa monitorizará métricas avanzadas de rendimiento:
- `blocks read`: Número de bloques leídos desde disco.
- `blocks hit`: Número de bloques obtenidos desde caché.
- **Execute custom queries**: Si se activa permitirá ejecutar consultas personalizadas sobre la instancia y sobre las bases de datos descubiertas.
- **Custom queries**: Bloque de configuración para definir las consultas personalizadas que se ejecutarán. Admite los campos `target_scope` (`instances`, `databases` o `all`) y la palabra reservada `$__self_dbname` para componer dinámicamente el nombre del módulo y la consulta en función de la base de datos en la que se ejecute.
[ 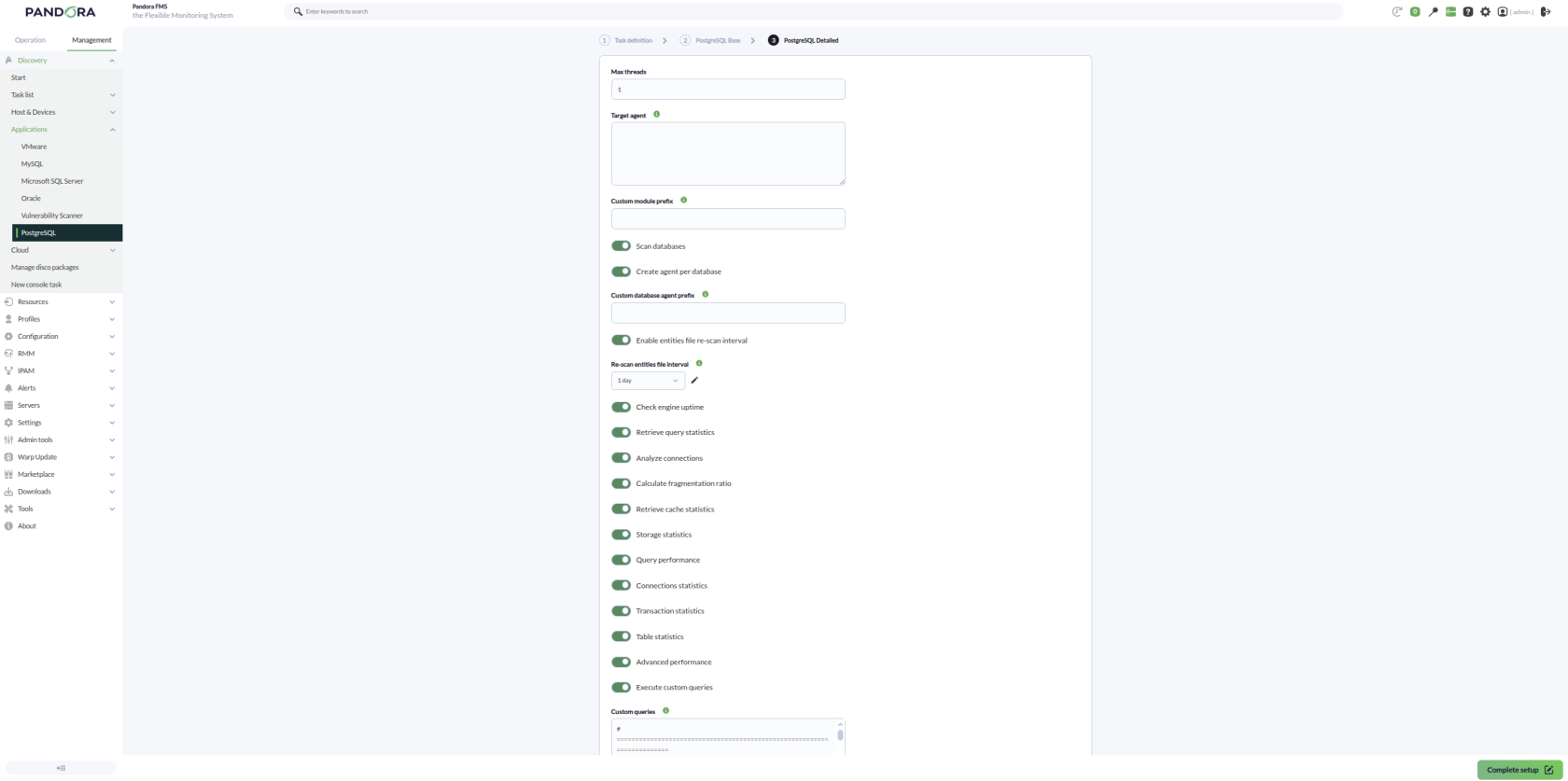 ](https://pandorafms.com/guides/public/uploads/images/gallery/2026-05/step3.png)
Comportamiento del descubrimiento:
- Siempre se creará un agente principal para cada objetivo PostgreSQL.
- Si **Scan databases** está activado, se descubrirán las bases de datos del objetivo.
- Si **Create agent per database** está activado, se creará un agente independiente por cada base de datos descubierta. En caso contrario los módulos de la base de datos se generarán en el agente principal utilizando como prefijo el nombre de la base de datos.
- El módulo **connection** se creará siempre para cada base de datos descubierta, incluso aunque no haya otros tokens activados.
- El módulo **POSTGRESQL connection** se creará siempre para el agente principal (instancia) con el objetivo de reflejar la disponibilidad global de la instancia.
- Cuando **Enable entities file re-scan interval** está activo, las bases de datos previamente detectadas se persisten en el fichero de entidades, de manera que si dejan de aparecer en el escaneo actual el plugin seguirá generando su módulo `connection` (que podrá pasar a estado crítico) en lugar de eliminarlas silenciosamente.
Las tareas que se completen exitosamente dispondrán de un sumario de ejecución con la siguiente información:
- **Total agents**: Total de agentes generados por la tarea.
- **Targets up**: Total de objetivos a los que ha sido posible conectar.
- **Targets down**: Total de objetivos a los que no ha sido posible conectar.
# Agentes y módulos generados por el plugin
El plugin creará un agente principal por cada objetivo PostgreSQL definido. Ese agente contendrá los siguientes módulos según la configuración activada.
El módulo **POSTGRESQL connection** se generará siempre, independientemente de los tokens activados, y reflejará la disponibilidad general de la instancia.
| POSTGRESQL connection | \*\*Disponibilidad de la instancia PostgreSQL.\*\* Será 1 si se ha podido establecer la conexión con la instancia y 0 en caso contrario. |
Si está activado **engine\_uptime**:
| restart detection | \*\*Será 0 si se ha detectado un reinicio inesperado, y 1 en caso contrario.\*\* Permite detectar reinicios inesperados del servicio PostgreSQL que puedan afectar a la disponibilidad de la base de datos o provocar interrupciones en el servicio. |
Si está activado **query\_stats**:
| queries | \*\*Número de consultas activas.\*\* Permite conocer la carga actual de consultas activas sobre la instancia PostgreSQL. |
| insert | \*\*Número de consultas INSERT activas.\*\* Permite evaluar la actividad de inserción de datos y detectar posibles cargas elevadas de escritura. |
| delete | \*\*Número de consultas DELETE activas.\*\* Permite detectar operaciones de eliminación que puedan afectar al rendimiento. |
| update | \*\*Número de consultas UPDATE activas.\*\* Permite monitorizar operaciones de modificación de datos en curso. |
Si está activado **analyze\_connections**:
| session usage | \*\*Porcentaje de uso de conexiones respecto al máximo configurado.\*\* Permite controlar el consumo de conexiones disponibles y detectar situaciones de saturación. |
Si está activado **cache\_stats**:
| allocated buffer cache | \*\*Total de buffers compartidos asignados.\*\* Representa la memoria reservada por PostgreSQL para caché de datos. |
| backend used buffer cache | \*\*Buffers utilizados por procesos backend.\*\* Permite evaluar el uso de caché por procesos activos. |
| checkpoints buffer cache | \*\*Buffers escritos por checkpoints.\*\* Ayuda a analizar actividad de sincronización de datos a disco. |
| cleaned buffer cache | \*\*Buffers limpiados por el proceso writer.\*\* Permite evaluar actividad de limpieza de buffers. |
Si está activado **fragmentation\_ratio**:
| fragmentation ratio | \*\*Ratio medio estimado de fragmentación.\*\* Un ratio elevado puede indicar desperdicio de espacio o degradación del rendimiento. |
Si está activado **scan\_databases**, el plugin descubrirá las bases de datos del objetivo PostgreSQL.
El módulo **connection** se generará siempre para cada base de datos descubierta.
Si está activado **agent\_per\_database**, se creará un agente independiente por cada base de datos descubierta. En caso contrario, los módulos se generarán en el agente principal utilizando el prefijo correspondiente al nombre de la base de datos.
Si está activado **Storage statistics**:
| database size | \*\*Tamaño total de la base de datos.\*\* Permite controlar el crecimiento general del almacenamiento. |
| tables size | \*\*Tamaño total ocupado por las tablas.\*\* Permite analizar el espacio consumido por datos. |
| indexes size | \*\*Tamaño total ocupado por índices.\*\* Ayuda a detectar crecimiento excesivo de estructuras de indexación. |
| temp bytes | \*\*Datos temporales escritos en disco.\*\* Puede indicar operaciones pesadas de ordenación o procesamiento temporal. |
| temp files | \*\*Ficheros temporales creados.\*\* Ayuda a detectar carga elevada de operaciones temporales. |
Si está activado **Query performance**:
| long queries | \*\*Consultas activas de larga duración.\*\* Permite detectar consultas lentas o potencialmente problemáticas. |
| oldest query age | \*\*Tiempo de ejecución de la consulta activa más antigua.\*\* Útil para identificar bloqueos o procesos prolongados. |
| sequential scans | \*\*Número de escaneos secuenciales.\*\* Un valor elevado puede indicar falta de índices adecuados. |
| index scans | \*\*Número de escaneos mediante índices.\*\* Permite evaluar el uso eficiente de índices. |
| cache hit ratio | \*\*Ratio de aciertos de caché.\*\* Permite evaluar eficiencia del acceso a datos en memoria. |
Si está activado **Connections statistics**:
| active connections | \*\*Número de conexiones activas.\*\* Refleja actividad real de usuarios o procesos. |
| idle connections | \*\*Número de conexiones inactivas.\*\* Permite detectar sesiones abiertas sin actividad. |
| total connections | \*\*Número total de conexiones.\*\* Control global de consumo de conexiones por base de datos. |
Si está activado **Transaction statistics**:
| transactions | \*\*Total de transacciones ejecutadas.\*\* Refleja actividad transaccional general. |
| commits | \*\*Transacciones confirmadas.\*\* Indica operaciones completadas correctamente. |
| rollbacks | \*\*Transacciones revertidas.\*\* Puede indicar errores o cancelaciones. |
| rollback ratio | \*\*Ratio de rollbacks.\*\* Ayuda a detectar comportamientos anómalos. |
| deadlocks | \*\*Deadlocks detectados.\*\* Permite identificar conflictos de bloqueo. |
| conflicts | \*\*Conflictos detectados.\*\* Útil para evaluar concurrencia problemática. |
Si está activado **Table statistics**:
| table count | \*\*Número de tablas de usuario.\*\* Inventario estructural de la base de datos. |
| index count | \*\*Número de índices de usuario.\*\* Control de estructuras auxiliares. |
| live tuples | \*\*Registros activos estimados.\*\* Refleja volumen útil de datos. |
| dead tuples | \*\*Registros obsoletos estimados.\*\* Ayuda a detectar necesidad de VACUUM. |
| fragmentation ratio | \*\*Fragmentación estimada de tablas.\*\* Control del estado estructural de almacenamiento. |
Si está activado **Advanced performance**:
| blocks read | \*\*Bloques leídos desde disco.\*\* Permite medir acceso físico a almacenamiento. |
| blocks hit | \*\*Bloques obtenidos desde caché.\*\* Permite medir eficiencia del uso de memoria. |
El plugin también creará un **módulo por cada consulta personalizada** definida en el fichero de configuración. Las consultas con `target_scope`=`instances` se asignarán al agente principal de la instancia y las que tengan `target_scope`=`databases` se asignarán a los agentes de las bases de datos correspondientes.
En versiones PostgreSQL 17 y superiores, los módulos "backend used buffer cache", "checkpoints buffer cache" y "cleaned buffer cache" no están disponibles.