Pandora AzurePostgresql
Plugin with which to monitor an azure postgresql data server.
- Introduction
- Compatibility matrix
- Pre requisites
- Previous configuration
- Parameters
- Manual execution
- Configuration in PandoraFMS
- Modules generated by the plugin
Introduction
Ver. 23-08-2022
Plugin with which to monitor an azure postgresql data server.
Type: Server plug-in
Compatibility matrix
| Systems where tested |
CentOS 7, Fedora, rocky linux |
| Systems where it should work |
Any linux system |
Pre requisites
- Pandora FMS Data Server enabled
- Have the Pandora FMS Plugin Server enabled.
- Know some of your account credentials, such as your tenant id, secret, client id and server resource id.
Previous configuration
The plugin makes use of a file in which two types of data can be entered.
#credentials
tenant_id:<tenant-id>
client_id:<client-id>
secret:<secret>
#id resources
serverpostgres_id:<server_resource_id>Obtaining credentials necessary for the use of the plugin.
1. Credentials to authenticate:
-Tenant id
-Client id
-Secret
2. Recurse ID
You need the resource id of the resource that the plugin monitors, these are :
- Postgresql server resource id
Obtaining tenant id and client id.
1. To obtain the tenant id and the client id, we will go to the application registry menu inside the active directory:
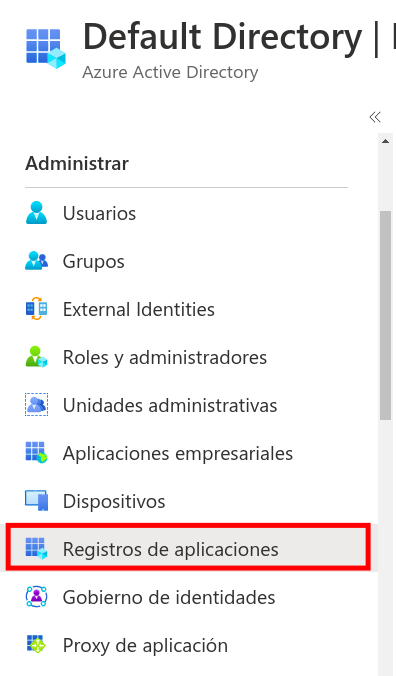
2. We will enter inside the application.
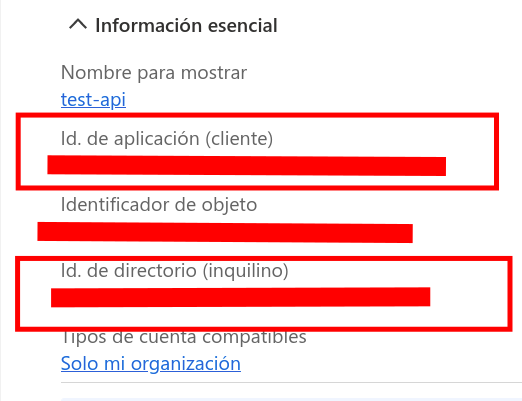
3. The tenant id and client id will appear in the application menu.
4. To find the secret we will go to certificates and secrets inside the active directory menu.

5. Within this menu we will be able to see the secret keys or generate them (it has to be the key value, not the id).
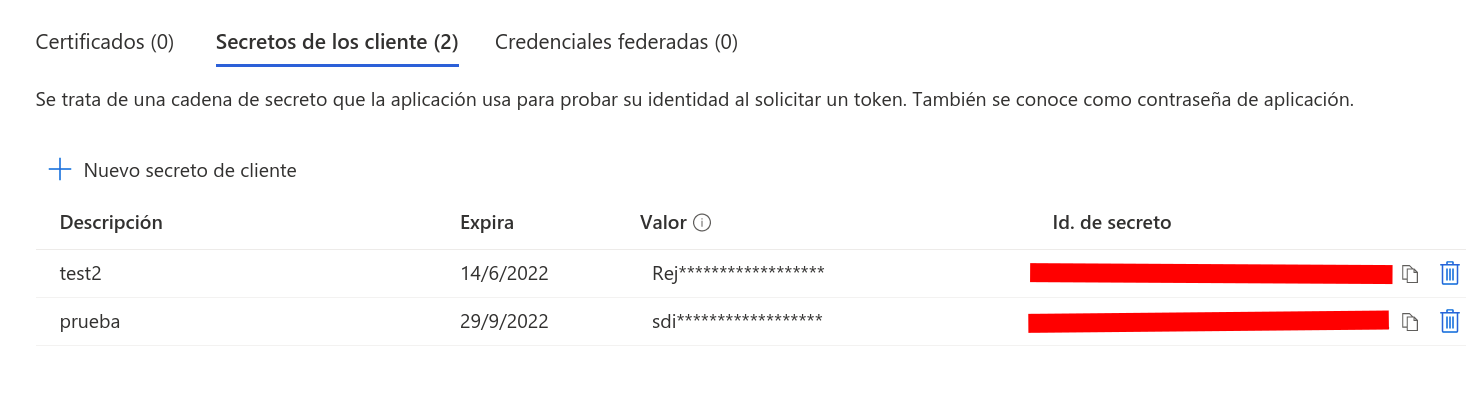
Obtaining the resource id of the database.

Parameters
| Parameters | Description |
| --timespan | In hours (optional), last time period, can be used in a custom run to display data from a time period (optional). |
| --metric | Metric name for custom execution (optional). |
| --granularity | In minutes combined with timespan it will show you the data in intervals (optional). |
| --name_module | To choose the name of the module in a custom run (optional). |
| --tentacle_port | Tentacle port Default 41121 (optional) |
| --tentacle_address | Ip of the tentacle server to send the data (optional) |
| --agent_name | To name the agent that will contain the modules, by default: "Azure SQL" (optional). |
| --prefix_module | To prefix the modules in case you want to differentiate them from other executions (optional). |
| --conf | Path of the conf file with the queries (required) |
| -g,--group | Pandora FMS target group (optional) |
| --data_dir | Pandora FMS data directory. By default it is /var/spool/pandora/data_in/ (optional) |
| --as_agent_plugin | It is optional, if you want the plugin to be an agent plugin and put the modules in the pandora agent, execute this with a 1 (optional) |
Manual execution
Basic manual execution
./pandora_azurepostgresql --conf <path-conf> --as_agent_plugin 1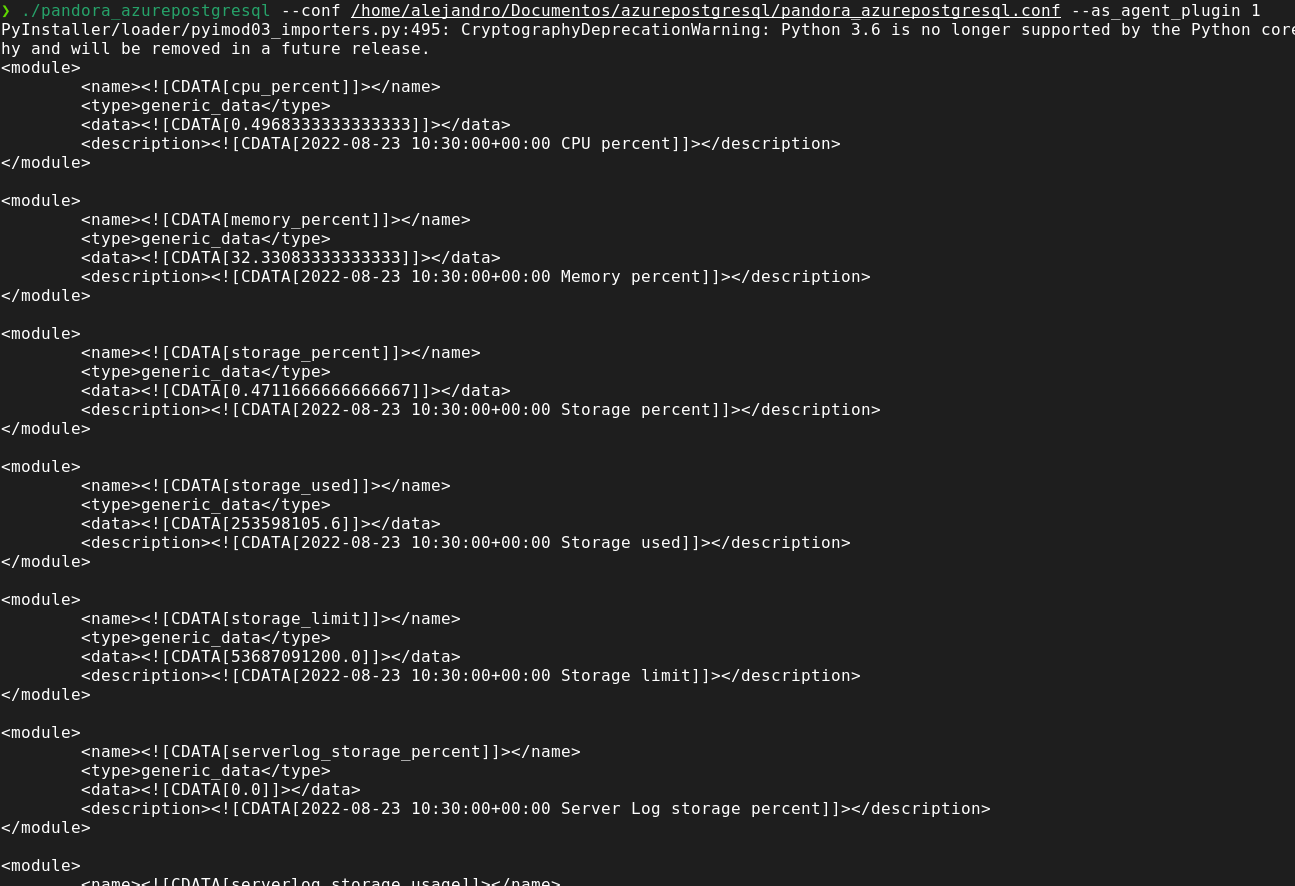
Manual execution for module creation with customized intervals
./pandora_azurepostgresql --conf <path-conf> --as_agent_plugin 1 --timespan <period in hours> --granularity <interval in minutes> --metric <name-metric> --name_module <name_module>![]()
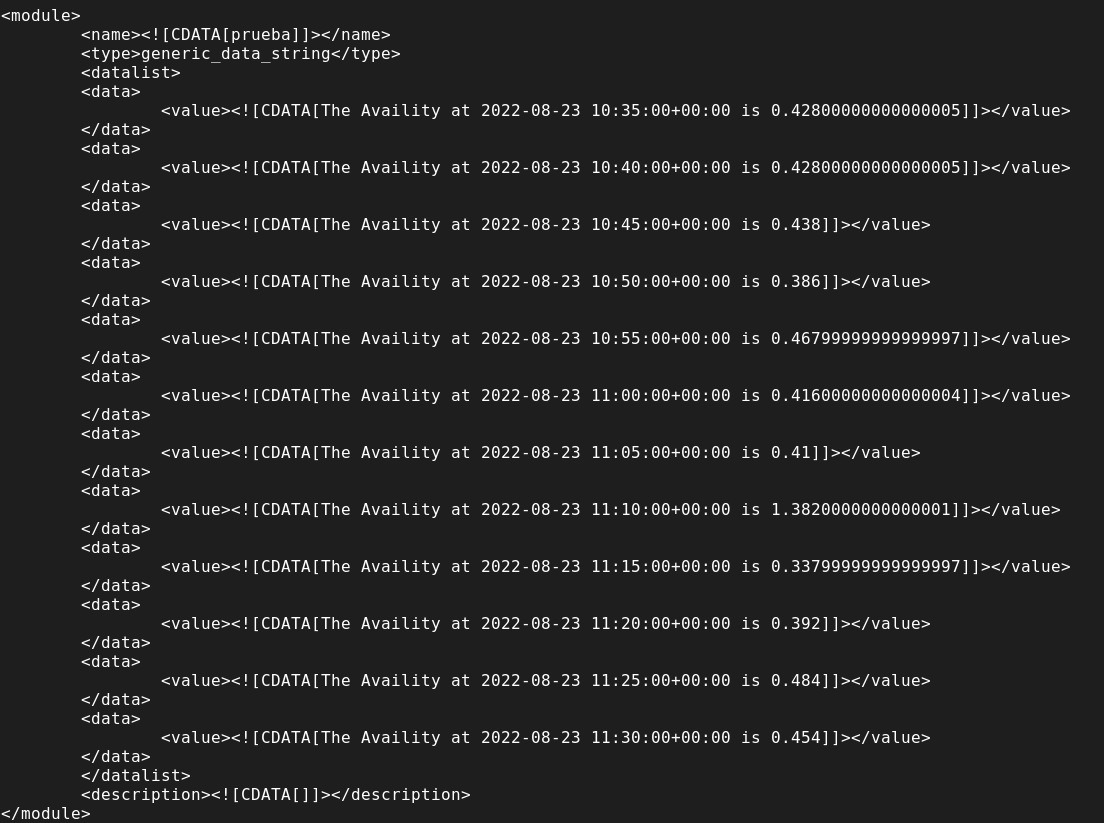
Configuration in PandoraFMS
As server plugin
Manual installation
Go to servers > plugins:
Click on add:
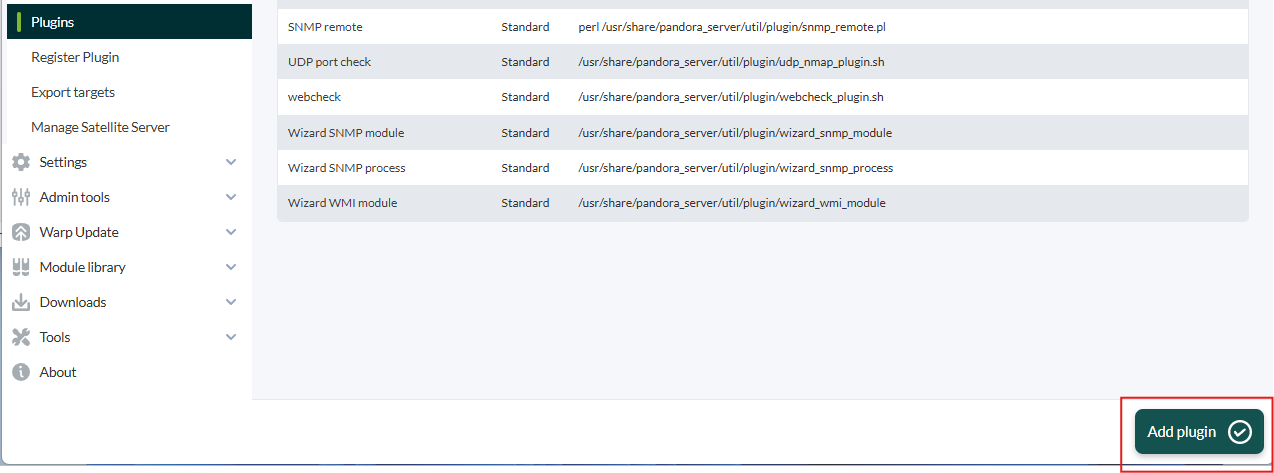
We put in name and the description that is preferred.
We put as command the execution with the path of the plugin:
/path_pandora_azurepostgresqlRemember that the recommended path for the use of the server plugins is: /usr/share/pandora_server/util/plugin/
And in parameters of the plugin we will introduce these followed by the macro "_field<N>_", the obligatory one for it to work is --conf.
Although it is not mandatory, it is highly recommended the use of the --agent_name parameter, since it allows us to customize the name of the agent that will contain the modules created for each customized query. It is also advisable to use the --prefix_module parameter, because this will allow us to assign a prefix to the modules, which can be useful to recognize them faster and differentiate them if we create several executions for different databases.
--CONF
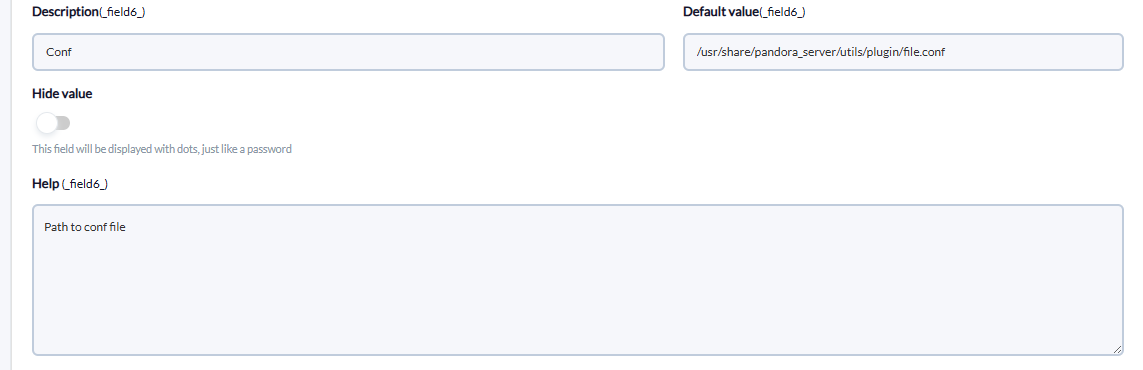
Once this is done, we will click on "create".
Once this is done, the only thing left to do is to call it so we will go to some agent's view and create a plugin module:
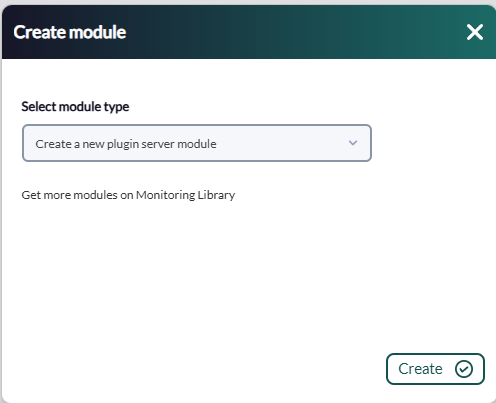
We will give it a name and in the section "plugin" we will put the one we have just configured.
Once this is done, click on create.
If the module is shown with 1, it means that it is running correctly.
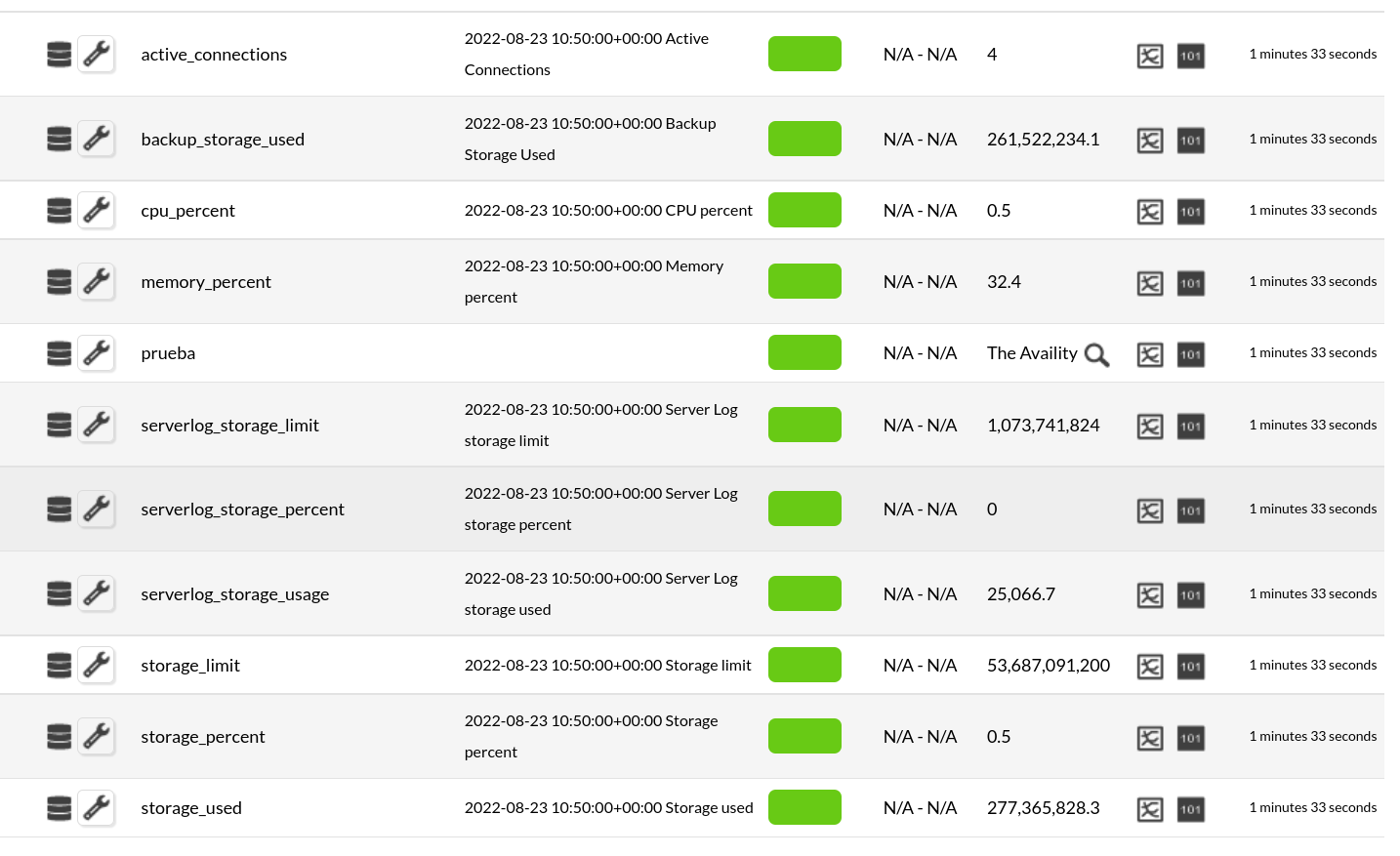
Modules generated by the plugin
The plugin will create an agent with the name we have set with the --agent_name parameter.

And it will create the following modules:
|
cpu_percent
|
|
memory_percent
|
|
io_consumption_percent
|
|
storage_percent
|
|
storage_used
|
|
storage_limit
|
|
serverlog_storage_percent
|
|
serverlog_storage_usage
|
|
serverlog_storage_limit
|
|
active_connections
|
|
connections_failed
|
|
backup_storage_used
|
|
network_bytes_egress
|
|
network_bytes_ingress
|
|
pg_replica_log_delay_in_seconds
|
|
pg_replica_log_delay_in_bytes
|